 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKDLSQ-BERT: A Quantized Bert Combining Knowledge Distillation with Learned Step Size Quantization
Jan 15, 2021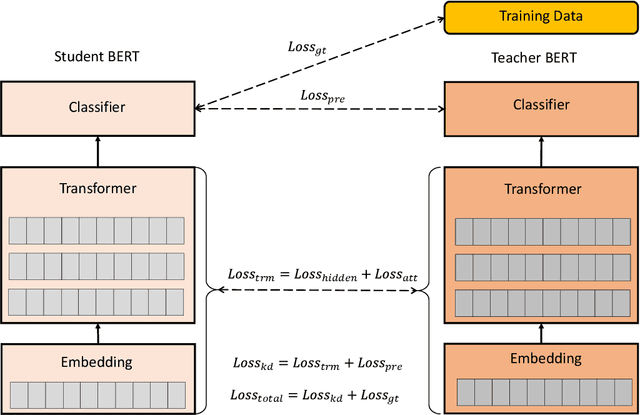
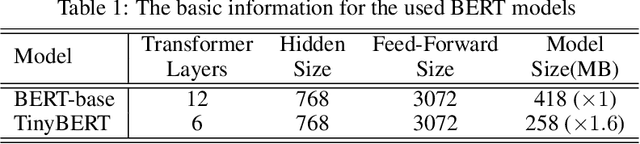
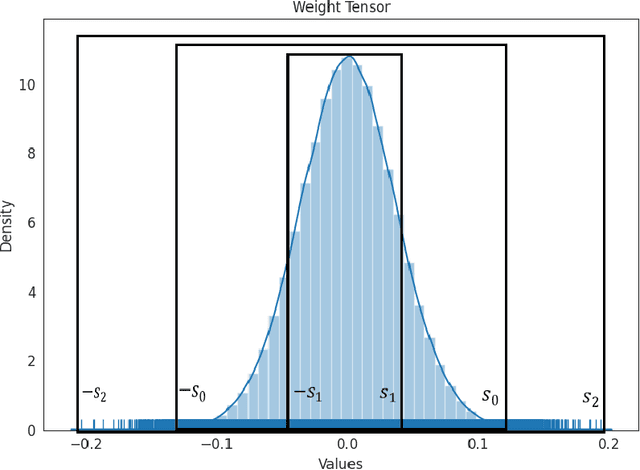
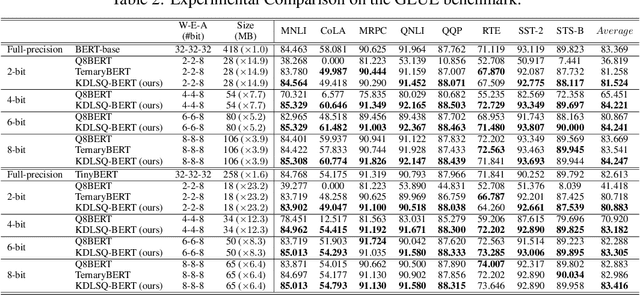
Recently, transformer-based language models such as BERT have shown tremendous performance improvement for a range of natural language processing tasks. However, these language models usually are computation expensive and memory intensive during inference. As a result, it is difficult to deploy them on resource-restricted devices. To improve the inference performance, as well as reduce the model size while maintaining the model accuracy, we propose a novel quantization method named KDLSQ-BERT that combines knowledge distillation (KD) with learned step size quantization (LSQ) for language model quantization. The main idea of our method is that the KD technique is leveraged to transfer the knowledge from a "teacher" model to a "student" model when exploiting LSQ to quantize that "student" model during the quantization training process. Extensive experiment results on GLUE benchmark and SQuAD demonstrate that our proposed KDLSQ-BERT not only performs effectively when doing different bit (e.g. 2-bit $\sim$ 8-bit) quantization, but also outperforms the existing BERT quantization methods, and even achieves comparable performance as the full-precision base-line model while obtaining 14.9x compression ratio. Our code will be public available.