 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDEInvBench: A Comprehensive Dataset and Design Space Exploration of Neural Networks for PDE Inverse Problems
May 26, 2026Inverse problems in partial differential equations (PDEs) involve estimating the physical parameters of a system from observed spatiotemporal solution fields. Neural networks are well-suited for PDE parameter estimation due to their capability to model function-to-function space transformations. While existing benchmarks of machine learning methods for PDEs primarily focus on the forward problem, there are no similar comprehensive studies and benchmark datasets on PDE inverse problems, i.e., mapping solution fields to underlying physical parameters. We fill this gap by introducing PDEInvBench, a comprehensive benchmark dataset consisting of numerical simulations for both time-dependent and time-independent PDEs across a wide range of physical behaviors and parameters. Our dataset includes evaluation splits that assess performance in both in-distribution and various out-of-distribution settings. Using our benchmark dataset, we comprehensively explore the design space of neural networks for PDE inverse problems along three key dimensions: (1) optimization procedures, analyzing the role of supervised, self-supervised, and test-time training objectives on performance, (2) problem representations, where we study the value of architectural choices with different inductive biases and various conditioning strategies, and (3) scaling, which we perform with respect to both model and data size. Our experiments reveal several practical insights: 1) neural networks perform best with a two-stage training procedure: initial supervision with PDE parameters followed by test-time fine-tuning using the PDE residual, 2) incorporating PDE derivatives as input features consistently improves accuracy, and 3) increasing the diversity of initial conditions in the training data yields greater performance gains than expanding the range of PDE parameters. We make our dataset and codebase publicly available.
* 37 total pages, 13 main pages, 20 figures, 8 tables. Published in Transactions on Machine Learning Research (TMLR), 2026
Geometric Red-Teaming for Robotic Manipulation
Sep 15, 2025Standard evaluation protocols in robotic manipulation typically assess policy performance over curated, in-distribution test sets, offering limited insight into how systems fail under plausible variation. We introduce Geometric Red-Teaming (GRT), a red-teaming framework that probes robustness through object-centric geometric perturbations, automatically generating CrashShapes -- structurally valid, user-constrained mesh deformations that trigger catastrophic failures in pre-trained manipulation policies. The method integrates a Jacobian field-based deformation model with a gradient-free, simulator-in-the-loop optimization strategy. Across insertion, articulation, and grasping tasks, GRT consistently discovers deformations that collapse policy performance, revealing brittle failure modes missed by static benchmarks. By combining task-level policy rollouts with constraint-aware shape exploration, we aim to build a general purpose framework for structured, object-centric robustness evaluation in robotic manipulation. We additionally show that fine-tuning on individual CrashShapes, a process we refer to as blue-teaming, improves task success by up to 60 percentage points on those shapes, while preserving performance on the original object, demonstrating the utility of red-teamed geometries for targeted policy refinement. Finally, we validate both red-teaming and blue-teaming results with a real robotic arm, observing that simulated CrashShapes reduce task success from 90% to as low as 22.5%, and that blue-teaming recovers performance to up to 90% on the corresponding real-world geometry -- closely matching simulation outcomes. Videos and code can be found on our project website: https://georedteam.github.io/ .
Nighttime Dehaze-Enhancement
Oct 18, 2022
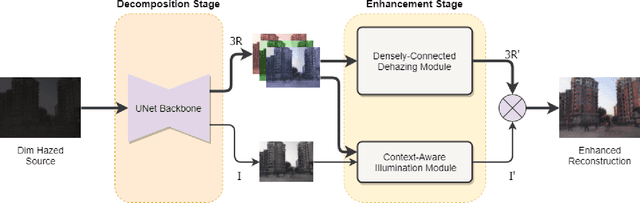


In this paper, we introduce a new computer vision task called nighttime dehaze-enhancement. This task aims to jointly perform dehazing and lightness enhancement. Our task fundamentally differs from nighttime dehazing -- our goal is to jointly dehaze and enhance scenes, while nighttime dehazing aims to dehaze scenes under a nighttime setting. In order to facilitate further research on this task, we release a new benchmark dataset called Reside-$\beta$ Night dataset, consisting of 4122 nighttime hazed images from 2061 scenes and 2061 ground truth images. Moreover, we also propose a new network called NDENet (Nighttime Dehaze-Enhancement Network), which jointly performs dehazing and low-light enhancement in an end-to-end manner. We evaluate our method on the proposed benchmark and achieve SSIM of 0.8962 and PSNR of 26.25. We also compare our network with other baseline networks on our benchmark to demonstrate the effectiveness of our approach. We believe that nighttime dehaze-enhancement is an essential task particularly for autonomous navigation applications, and hope that our work will open up new frontiers in research. Our dataset and code will be made publicly available upon acceptance of our paper.
Leveraging Dependency Grammar for Fine-Grained Offensive Language Detection using Graph Convolutional Networks
May 26, 2022
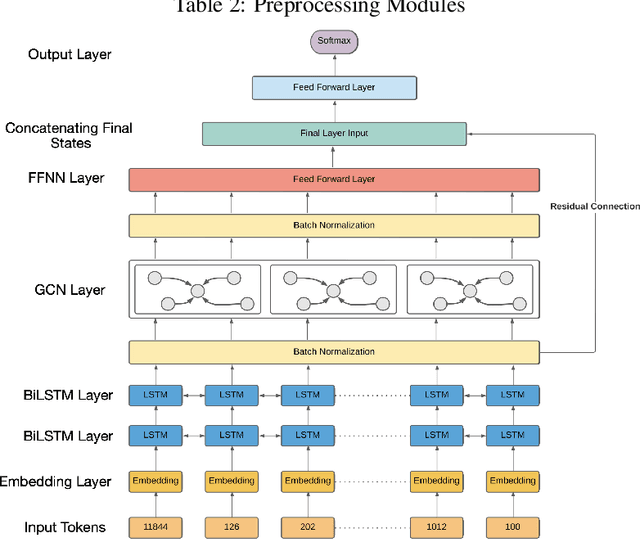

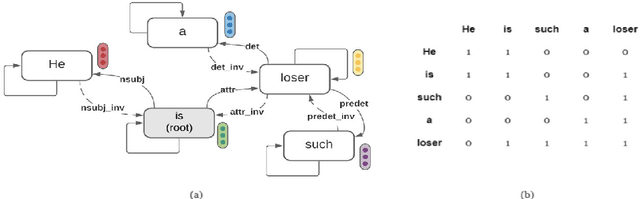
The last few years have witnessed an exponential rise in the propagation of offensive text on social media. Identification of this text with high precision is crucial for the well-being of society. Most of the existing approaches tend to give high toxicity scores to innocuous statements (e.g., "I am a gay man"). These false positives result from over-generalization on the training data where specific terms in the statement may have been used in a pejorative sense (e.g., "gay"). Emphasis on such words alone can lead to discrimination against the classes these systems are designed to protect. In this paper, we address the problem of offensive language detection on Twitter, while also detecting the type and the target of the offence. We propose a novel approach called SyLSTM, which integrates syntactic features in the form of the dependency parse tree of a sentence and semantic features in the form of word embeddings into a deep learning architecture using a Graph Convolutional Network. Results show that the proposed approach significantly outperforms the state-of-the-art BERT model with orders of magnitude fewer number of parameters.
On The Cross-Modal Transfer from Natural Language to Code through Adapter Modules
Apr 19, 2022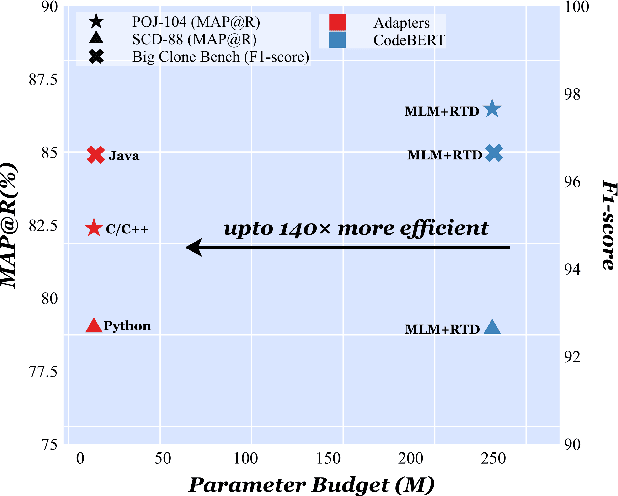

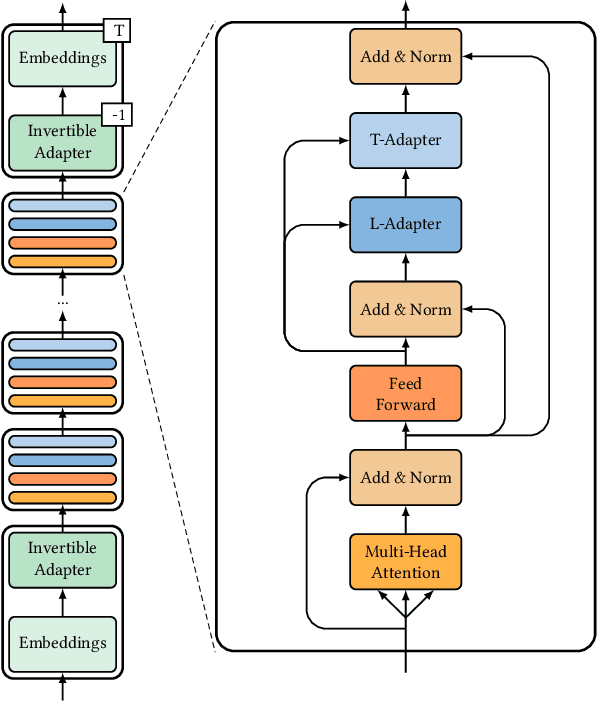
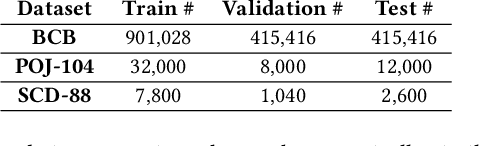
Pre-trained neural Language Models (PTLM), such as CodeBERT, are recently used in software engineering as models pre-trained on large source code corpora. Their knowledge is transferred to downstream tasks (e.g. code clone detection) via fine-tuning. In natural language processing (NLP), other alternatives for transferring the knowledge of PTLMs are explored through using adapters, compact, parameter efficient modules inserted in the layers of the PTLM. Although adapters are known to facilitate adapting to many downstream tasks compared to fine-tuning the model that require retraining all of the models' parameters -- which owes to the adapters' plug and play nature and being parameter efficient -- their usage in software engineering is not explored. Here, we explore the knowledge transfer using adapters and based on the Naturalness Hypothesis proposed by Hindle et. al \cite{hindle2016naturalness}. Thus, studying the bimodality of adapters for two tasks of cloze test and code clone detection, compared to their benchmarks from the CodeXGLUE platform. These adapters are trained using programming languages and are inserted in a PTLM that is pre-trained on English corpora (N-PTLM). Three programming languages, C/C++, Python, and Java, are studied along with extensive experiments on the best setup used for adapters. Improving the results of the N-PTLM confirms the success of the adapters in knowledge transfer to software engineering, which sometimes are in par with or exceed the results of a PTLM trained on source code; while being more efficient in terms of the number of parameters, memory usage, and inference time. Our results can open new directions to build smaller models for more software engineering tasks. We open source all the scripts and the trained adapters.