 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Dependency Grammar for Fine-Grained Offensive Language Detection using Graph Convolutional Networks
Paper and Code

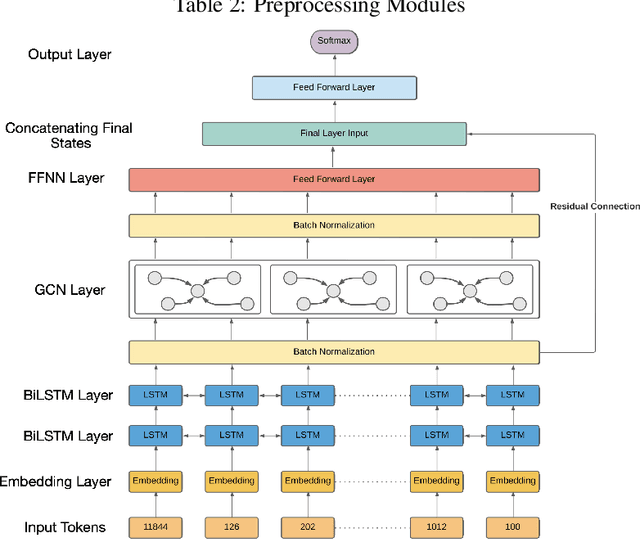

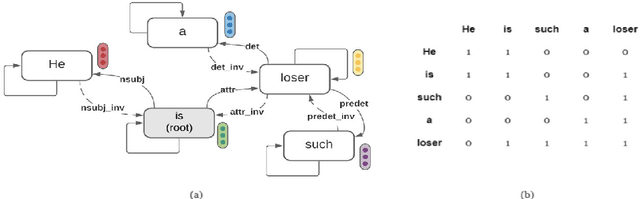
The last few years have witnessed an exponential rise in the propagation of offensive text on social media. Identification of this text with high precision is crucial for the well-being of society. Most of the existing approaches tend to give high toxicity scores to innocuous statements (e.g., "I am a gay man"). These false positives result from over-generalization on the training data where specific terms in the statement may have been used in a pejorative sense (e.g., "gay"). Emphasis on such words alone can lead to discrimination against the classes these systems are designed to protect. In this paper, we address the problem of offensive language detection on Twitter, while also detecting the type and the target of the offence. We propose a novel approach called SyLSTM, which integrates syntactic features in the form of the dependency parse tree of a sentence and semantic features in the form of word embeddings into a deep learning architecture using a Graph Convolutional Network. Results show that the proposed approach significantly outperforms the state-of-the-art BERT model with orders of magnitude fewer number of parameters.