 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Cross-Modal Transfer from Natural Language to Code through Adapter Modules
Apr 19, 2022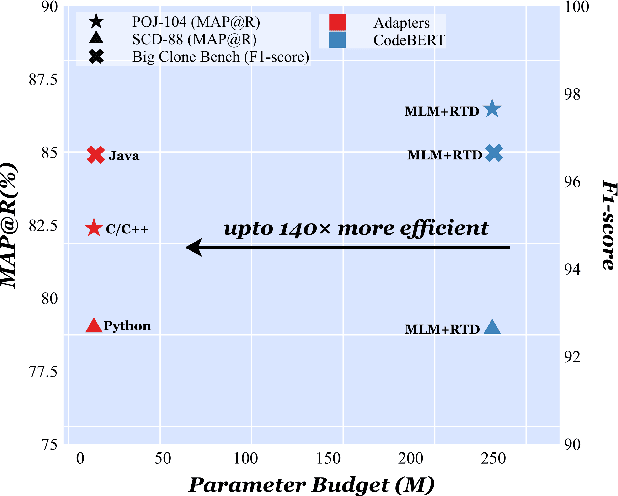

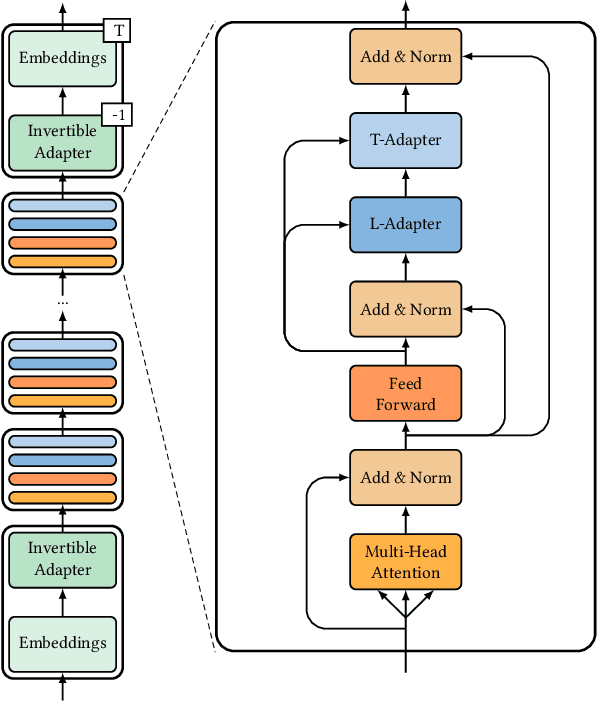
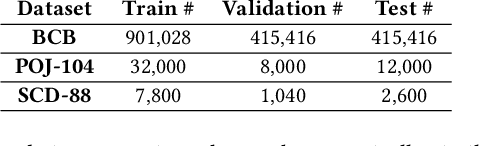
Pre-trained neural Language Models (PTLM), such as CodeBERT, are recently used in software engineering as models pre-trained on large source code corpora. Their knowledge is transferred to downstream tasks (e.g. code clone detection) via fine-tuning. In natural language processing (NLP), other alternatives for transferring the knowledge of PTLMs are explored through using adapters, compact, parameter efficient modules inserted in the layers of the PTLM. Although adapters are known to facilitate adapting to many downstream tasks compared to fine-tuning the model that require retraining all of the models' parameters -- which owes to the adapters' plug and play nature and being parameter efficient -- their usage in software engineering is not explored. Here, we explore the knowledge transfer using adapters and based on the Naturalness Hypothesis proposed by Hindle et. al \cite{hindle2016naturalness}. Thus, studying the bimodality of adapters for two tasks of cloze test and code clone detection, compared to their benchmarks from the CodeXGLUE platform. These adapters are trained using programming languages and are inserted in a PTLM that is pre-trained on English corpora (N-PTLM). Three programming languages, C/C++, Python, and Java, are studied along with extensive experiments on the best setup used for adapters. Improving the results of the N-PTLM confirms the success of the adapters in knowledge transfer to software engineering, which sometimes are in par with or exceed the results of a PTLM trained on source code; while being more efficient in terms of the number of parameters, memory usage, and inference time. Our results can open new directions to build smaller models for more software engineering tasks. We open source all the scripts and the trained adapters.