 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially-Optimal Mechanism Design for Incentivized Online Learning
Paper and Code
Dec 29, 2021
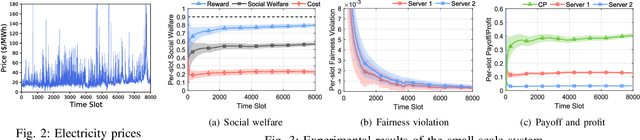
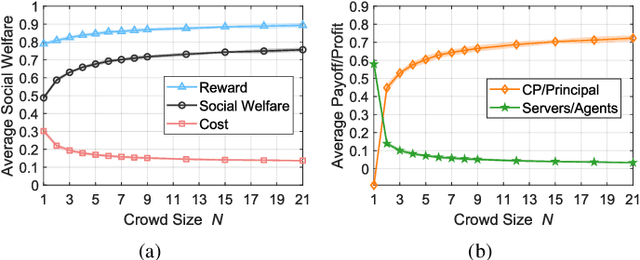

Multi-arm bandit (MAB) is a classic online learning framework that studies the sequential decision-making in an uncertain environment. The MAB framework, however, overlooks the scenario where the decision-maker cannot take actions (e.g., pulling arms) directly. It is a practically important scenario in many applications such as spectrum sharing, crowdsensing, and edge computing. In these applications, the decision-maker would incentivize other selfish agents to carry out desired actions (i.e., pulling arms on the decision-maker's behalf). This paper establishes the incentivized online learning (IOL) framework for this scenario. The key challenge to design the IOL framework lies in the tight coupling of the unknown environment learning and asymmetric information revelation. To address this, we construct a special Lagrangian function based on which we propose a socially-optimal mechanism for the IOL framework. Our mechanism satisfies various desirable properties such as agent fairness, incentive compatibility, and voluntary participation. It achieves the same asymptotic performance as the state-of-art benchmark that requires extra information. Our analysis also unveils the power of crowd in the IOL framework: a larger agent crowd enables our mechanism to approach more closely the theoretical upper bound of social performance. Numerical results demonstrate the advantages of our mechanism in large-scale edge computing.