 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMO: Coverage-guided Model Generation For Deep Learning Library Testing
Paper and Code
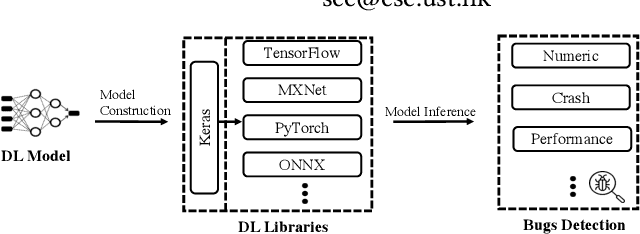
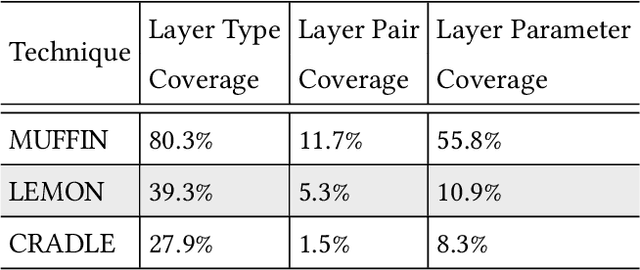
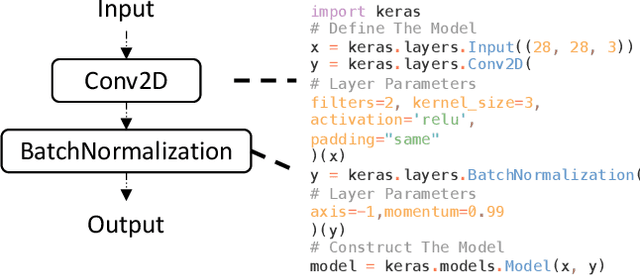
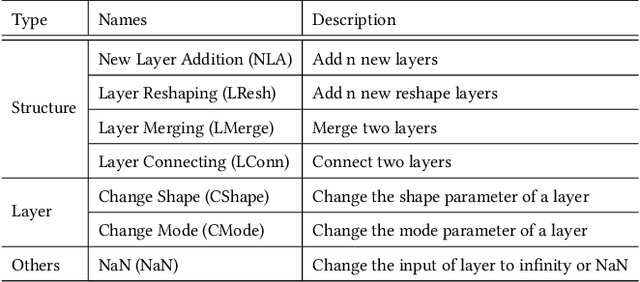
Recent deep learning (DL) applications are mostly built on top of DL libraries. The quality assurance of these libraries is critical to the dependable deployment of DL applications. A few techniques have thereby been proposed to test DL libraries by generating DL models as test inputs. Then these techniques feed those DL models to DL libraries for making inferences, in order to exercise DL libraries modules related to a DL model's execution. However, the test effectiveness of these techniques is constrained by the diversity of generated DL models. Our investigation finds that these techniques can cover at most 11.7% of layer pairs (i.e., call sequence between two layer APIs) and 55.8% of layer parameters (e.g., "padding" in Conv2D). As a result, we find that many bugs arising from specific layer pairs and parameters can be missed by existing techniques. In view of the limitations of existing DL library testing techniques, we propose MEMO to efficiently generate diverse DL models by exploring layer types, layer pairs, and layer parameters. MEMO: (1) designs an initial model reduction technique to boost test efficiency without compromising model diversity; and (2) designs a set of mutation operators for a customized Markov Chain Monte Carlo (MCMC) algorithm to explore new layer types, layer pairs, and layer parameters. We evaluate MEMO on seven popular DL libraries, including four for model execution (TensorFlow, PyTorch and MXNet, and ONNX) and three for model conversions (Keras-MXNet, TF2ONNX, ONNX2PyTorch). The evaluation result shows that MEMO outperforms recent works by covering 10.3% more layer pairs, 15.3% more layer parameters, and 2.3% library branches. Moreover, MEMO detects 29 new bugs in the latest version of DL libraries, with 17 of them confirmed by DL library developers, and 5 of those confirmed bugs have been fixed.