 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
May 10, 2026Continual post-training aims to extend large language models (LLMs) with new knowledge, skills, and behaviors, yet it remains unclear when sequential updates enable capability transfer and when they cause catastrophic forgetting. Existing methods mitigate forgetting through sequential fine-tuning, replay, regularization, or model merging, but offer limited criteria for determining when incorporating new updates is beneficial or harmful. In this work, we study LLM continual post-training through three questions: What drives forgetting? When do sequentially acquired capabilities transfer or interfere? How can compatibility be used to control update integration? We address these questions through task geometry: we represent each post-training task by its parameter update and study the covariance geometry induced by the update. Our central finding is that: forgetting can be considered as a state-relative update-integration failure, it arises when the covariance geometries induced by tasks misalign with the geometry of the evolving model state. Sequential updates transfer when they remain compatible with the model state shaped by previous updates, and interfere when state-relative geometry conflict becomes high. Motivated by this finding, we propose Geometry-Conflict Wasserstein Merging (GCWM), a data-free update-integration method that constructs a shared Wasserstein metric via Gaussian Wasserstein barycenters and uses geometry conflict to gate geometry-aware correction. Across Qwen3 0.6B--14B on domain-continual and capability-continual settings, GCWM consistently outperforms data-free baselines, improving retention and final performance without replay data. These results identify geometry conflict as both an explanatory signal for forgetting and a practical control signal for LLM continual post-training.
MR-Coupler: Automated Metamorphic Test Generation via Functional Coupling Analysis
Apr 11, 2026Metamorphic testing (MT) is a widely recognized technique for alleviating the oracle problem in software testing. However, its adoption is hindered by the difficulty of constructing effective metamorphic relations (MRs), which often require domain-specific or hard-to-obtain knowledge. In this work, we propose a novel approach that leverages the functional coupling between methods, which is readily available in source code, to automatically construct MRs and generate metamorphic test cases (MTCs). Our technique, MR-Coupler, identifies functionally coupled method pairs, employs large language models to generate candidate MTCs, and validates them through test amplification and mutation analysis. In particular, we leverage three functional coupling features to avoid expensive enumeration of possible method pairs, and a novel validation mechanism to reduce false alarms. Our evaluation of MR-Coupler on 100 human-written MTCs and 50 real-world bugs shows that it generates valid MTCs for over 90% of tasks, improves valid MTC generation by 64.90%, and reduces false alarms by 36.56% compared to baselines. Furthermore, the MTCs generated by MR-Coupler detect 44% of the real bugs. Our results highlight the effectiveness of leveraging functional coupling for automated MR construction and the potential of MR-Coupler to facilitate the adoption of MT in practice. We also released the tool and experimental data to support future research.
* Note: Accepted on ACM International Conference on the Foundations of Software Engineering (FSE) 2026
Demystifying the Silence of Correctness Bugs in PyTorch Compiler
Apr 09, 2026Performance optimization of AI infrastructure is key to the fast adoption of large language models (LLMs). The PyTorch compiler (torch.compile), a core optimization tool for deep learning (DL) models (including LLMs), has received due attention. However, torch.compile is prone to correctness bugs, which cause incorrect outputs of compiled DL models without triggering exceptions, crashes, or warnings. These bugs pose a serious threat to the reliability of downstream LLM applications. Data from the PyTorch community shows that 19.2% of high-priority issues are incorrect outputs of compiled DL models induced by torch.compile bugs, the second-most-common bug category (only behind program crashes at 19.57%). However, no systematic study has been conducted to specifically characterize and thereby detect these bugs. In this paper, we present the first empirical study of the correctness bugs in torch.compile, examine their characteristics, and assess the effectiveness of existing fuzzers in detecting them. Based on our findings, we propose a proof-of-concept testing technique named AlignGuard, tailored specifically for detecting correctness bugs in torch.compile. AlignGuard incorporates bug characteristics distilled from our empirical study, applying LLM-based test mutation to existing test cases for correctness bug detection. At the time of writing, AlignGuard has successfully detected 23 new correctness bugs in recent torch.compile. All these bugs have been confirmed or fixed by the PyTorch development team, and over half (14/23) of them are even marked as high-priority bugs, underscoring the usefulness of our technique.
Scaling Coding Agents via Atomic Skills
Apr 06, 2026Current LLM coding agents are predominantly trained on composite benchmarks (e.g., bug fixing), which often leads to task-specific overfitting and limited generalization. To address this, we propose a novel scaling paradigm that shifts the focus from task-level optimization to atomic skill mastery. We first formalize five fundamental atomic skills, code localization, code editing, unit-test generation, issue reproduction, and code review, that serve as the basis vectors for complex software engineering tasks. Compared with composite coding tasks, these atomic skills are more generalizable and composable. Then, we scale coding agents by performing joint RL over atomic skills. In this manner, atomic skills are consistently improved without negative interference or trade-offs between them. Notably, we observe that improvements in these atomic skills generalize well to other unseen composite coding tasks, such as bug-fixing, code refactoring, machine learning engineering, and code security. The observation motivates a new scaling paradigm for coding agents by training with atomic skills. Extensive experiments demonstrate the effectiveness of our proposed paradigm. Notably, our joint RL improves average performance by 18.7% on 5 atomic skills and 5 composite tasks.
ModelWisdom: An Integrated Toolkit for TLA+ Model Visualization, Digest and Repair
Feb 12, 2026Model checking in TLA+ provides strong correctness guarantees, yet practitioners continue to face significant challenges in interpreting counterexamples, understanding large state-transition graphs, and repairing faulty models. These difficulties stem from the limited explainability of raw model-checker output and the substantial manual effort required to trace violations back to source specifications. Although the TLA+ Toolbox includes a state diagram viewer, it offers only a static, fully expanded graph without folding, color highlighting, or semantic explanations, which limits its scalability and interpretability. We present ModelWisdom, an interactive environment that uses visualization and large language models to make TLA+ model checking more interpretable and actionable. ModelWisdom offers: (i) Model Visualization, with colorized violation highlighting, click-through links from transitions to TLA+ code, and mapping between violating states and broken properties; (ii) Graph Optimization, including tree-based structuring and node/edge folding to manage large models; (iii) Model Digest, which summarizes and explains subgraphs via large language models (LLMs) and performs preprocessing and partial explanations; and (iv) Model Repair, which extracts error information and supports iterative debugging. Together, these capabilities turn raw model-checker output into an interactive, explainable workflow, improving understanding and reducing debugging effort for nontrivial TLA+ specifications. The website to ModelWisdom is available: https://model-wisdom.pages.dev. A demonstrative video can be found at https://www.youtube.com/watch?v=plyZo30VShA.
An Empirical Study of Bugs in Data Visualization Libraries
Jun 18, 2025Data visualization (DataViz) libraries play a crucial role in presentation, data analysis, and application development, underscoring the importance of their accuracy in transforming data into visual representations. Incorrect visualizations can adversely impact user experience, distort information conveyance, and influence user perception and decision-making processes. Visual bugs in these libraries can be particularly insidious as they may not cause obvious errors like crashes, but instead mislead users of the underlying data graphically, resulting in wrong decision making. Consequently, a good understanding of the unique characteristics of bugs in DataViz libraries is essential for researchers and developers to detect and fix bugs in DataViz libraries. This study presents the first comprehensive analysis of bugs in DataViz libraries, examining 564 bugs collected from five widely-used libraries. Our study systematically analyzes their symptoms and root causes, and provides a detailed taxonomy. We found that incorrect/inaccurate plots are pervasive in DataViz libraries and incorrect graphic computation is the major root cause, which necessitates further automated testing methods for DataViz libraries. Moreover, we identified eight key steps to trigger such bugs and two test oracles specific to DataViz libraries, which may inspire future research in designing effective automated testing techniques. Furthermore, with the recent advancements in Vision Language Models (VLMs), we explored the feasibility of applying these models to detect incorrect/inaccurate plots. The results show that the effectiveness of VLMs in bug detection varies from 29% to 57%, depending on the prompts, and adding more information in prompts does not necessarily increase the effectiveness. More findings can be found in our manuscript.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025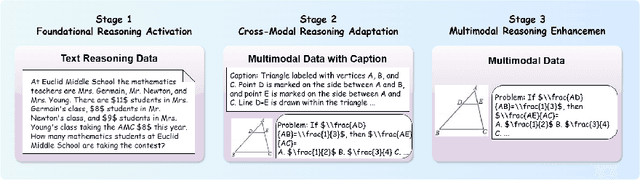
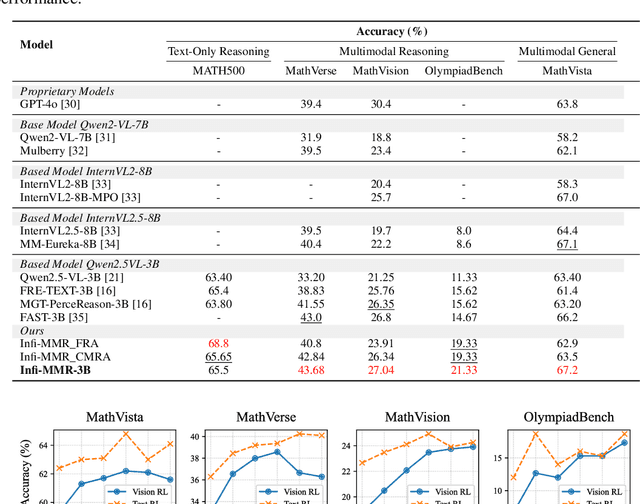
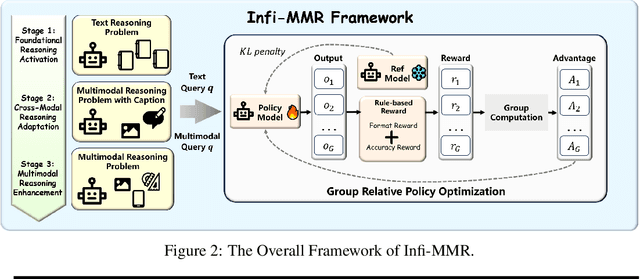
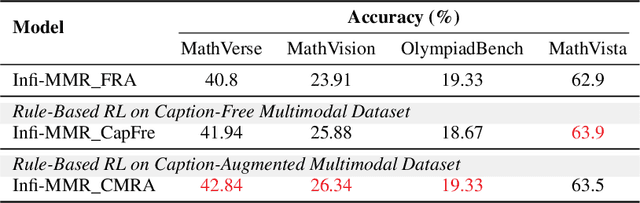
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
IP Leakage Attacks Targeting LLM-Based Multi-Agent Systems
May 18, 2025The rapid advancement of Large Language Models (LLMs) has led to the emergence of Multi-Agent Systems (MAS) to perform complex tasks through collaboration. However, the intricate nature of MAS, including their architecture and agent interactions, raises significant concerns regarding intellectual property (IP) protection. In this paper, we introduce MASLEAK, a novel attack framework designed to extract sensitive information from MAS applications. MASLEAK targets a practical, black-box setting, where the adversary has no prior knowledge of the MAS architecture or agent configurations. The adversary can only interact with the MAS through its public API, submitting attack query $q$ and observing outputs from the final agent. Inspired by how computer worms propagate and infect vulnerable network hosts, MASLEAK carefully crafts adversarial query $q$ to elicit, propagate, and retain responses from each MAS agent that reveal a full set of proprietary components, including the number of agents, system topology, system prompts, task instructions, and tool usages. We construct the first synthetic dataset of MAS applications with 810 applications and also evaluate MASLEAK against real-world MAS applications, including Coze and CrewAI. MASLEAK achieves high accuracy in extracting MAS IP, with an average attack success rate of 87% for system prompts and task instructions, and 92% for system architecture in most cases. We conclude by discussing the implications of our findings and the potential defenses.
Isolating Language-Coding from Problem-Solving: Benchmarking LLMs with PseudoEval
Feb 26, 2025Existing code generation benchmarks for Large Language Models (LLMs) such as HumanEval and MBPP are designed to study LLMs' end-to-end performance, where the benchmarks feed a problem description in natural language as input and examine the generated code in specific programming languages. However, the evaluation scores revealed in this way provide a little hint as to the bottleneck of the code generation -- whether LLMs are struggling with their problem-solving capability or language-coding capability. To answer this question, we construct PseudoEval, a multilingual code generation benchmark that provides a solution written in pseudocode as input. By doing so, the bottleneck of code generation in various programming languages could be isolated and identified. Our study yields several interesting findings. For example, we identify that the bottleneck of LLMs in Python programming is problem-solving, while Rust is struggling relatively more in language-coding. Also, our study indicates that problem-solving capability may transfer across programming languages, while language-coding needs more language-specific effort, especially for undertrained programming languages. Finally, we release the pipeline of constructing PseudoEval to facilitate the extension to existing benchmarks. PseudoEval is available at: https://anonymous.4open.science/r/PseudocodeACL25-7B74.
From Informal to Formal -- Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs
Jan 27, 2025The research in AI-based formal mathematical reasoning has shown an unstoppable growth trend. These studies have excelled in mathematical competitions like IMO, showing significant progress. However, these studies intertwined multiple skills simultaneously, i.e., problem-solving, reasoning, and writing formal specifications, making it hard to precisely identify the LLMs' strengths and weaknesses in each task. This paper focuses on formal verification, an immediate application scenario of formal reasoning, and decomposes it into six sub-tasks. We constructed 18k high-quality instruction-response pairs across five mainstream formal specification languages (Coq, Lean4, Dafny, ACSL, and TLA+) in six formal-verification-related tasks by distilling GPT-4o. They are split into a 14k+ fine-tuning dataset FM-alpaca and a 4k benchmark FM-Bench. We found that LLMs are good at writing proof segments when given either the code, or the detailed description of proof steps. Also, the fine-tuning brought about a nearly threefold improvement at most. Interestingly, we observed that fine-tuning with formal data also enhances mathematics, reasoning, and coding abilities. We hope our findings inspire further research. Fine-tuned models are released to facilitate subsequent studies