 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODECLEANER: Elevating Standards with A Robust Data Contamination Mitigation Toolkit
Nov 16, 2024Data contamination presents a critical barrier preventing widespread industrial adoption of advanced software engineering techniques that leverage code language models (CLMs). This phenomenon occurs when evaluation data inadvertently overlaps with the public code repositories used to train CLMs, severely undermining the credibility of performance evaluations. For software companies considering the integration of CLM-based techniques into their development pipeline, this uncertainty about true performance metrics poses an unacceptable business risk. Code refactoring, which comprises code restructuring and variable renaming, has emerged as a promising measure to mitigate data contamination. It provides a practical alternative to the resource-intensive process of building contamination-free evaluation datasets, which would require companies to collect, clean, and label code created after the CLMs' training cutoff dates. However, the lack of automated code refactoring tools and scientifically validated refactoring techniques has hampered widespread industrial implementation. To bridge the gap, this paper presents the first systematic study to examine the efficacy of code refactoring operators at multiple scales (method-level, class-level, and cross-class level) and in different programming languages. In particular, we develop an open-sourced toolkit, CODECLEANER, which includes 11 operators for Python, with nine method-level, one class-level, and one cross-class-level operator. A drop of 65% overlap ratio is found when applying all operators in CODECLEANER, demonstrating their effectiveness in addressing data contamination. Additionally, we migrate four operators to Java, showing their generalizability to another language. We make CODECLEANER online available to facilitate further studies on mitigating CLM data contamination.
When Dataflow Analysis Meets Large Language Models
Feb 16, 2024


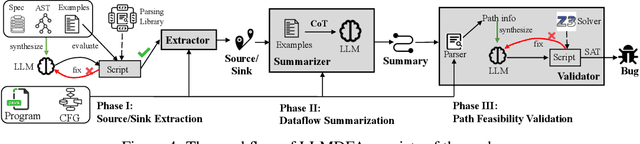
Dataflow analysis is a powerful code analysis technique that reasons dependencies between program values, offering support for code optimization, program comprehension, and bug detection. Existing approaches require the successful compilation of the subject program and customizations for downstream applications. This paper introduces LLMDFA, an LLM-powered dataflow analysis framework that analyzes arbitrary code snippets without requiring a compilation infrastructure and automatically synthesizes downstream applications. Inspired by summary-based dataflow analysis, LLMDFA decomposes the problem into three sub-problems, which are effectively resolved by several essential strategies, including few-shot chain-of-thought prompting and tool synthesis. Our evaluation has shown that the design can mitigate the hallucination and improve the reasoning ability, obtaining high precision and recall in detecting dataflow-related bugs upon benchmark programs, outperforming state-of-the-art (classic) tools, including a very recent industrial analyzer.
Fast Test Input Generation for Finding Deviated Behaviors in Compressed Deep Neural Network
Dec 06, 2021
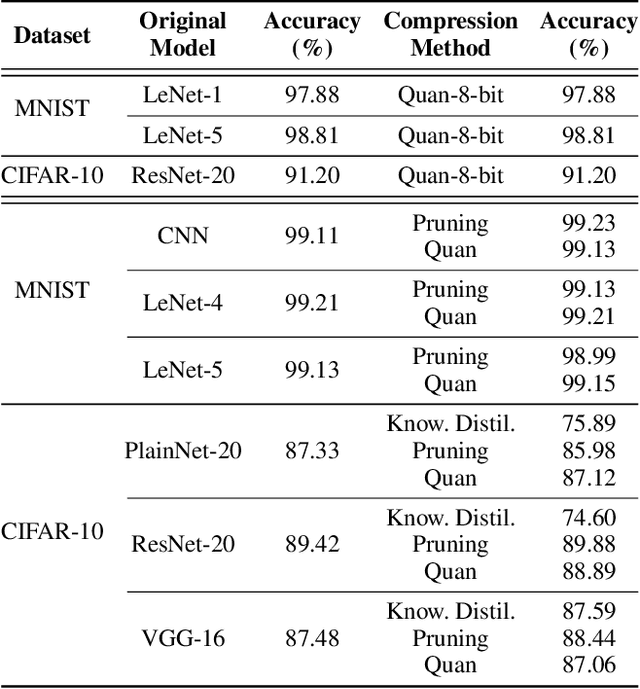
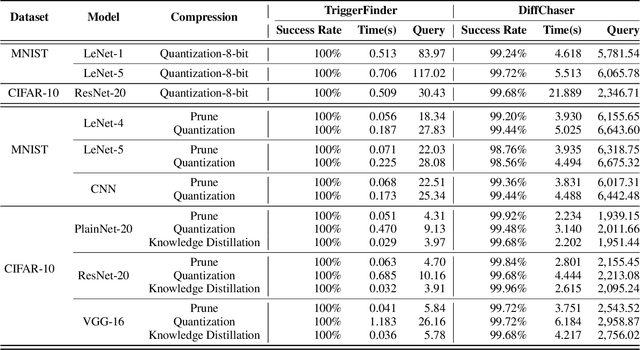
Model compression can significantly reduce sizes of deep neural network (DNN) models so that large, sophisticated models after compression can be deployed on resource-limited mobile and IoT devices. However, model compression often introduces deviated behaviors into a compressed model: the original and compressed models output different prediction results for the same input. Hence, it is critical to warn developers and help them comprehensively evaluate possible consequences of such behaviors before deployment. To this end, we propose TriggerFinder, a novel, effective and efficient testing approach to automatically identifying inputs to trigger deviated behaviors in compressed models. Given an input i as a seed, TriggerFinder iteratively applies a series of mutation operations to change i until the resulting input triggers a deviated behavior. However, compressed models usually hide their architecture and gradient information; without such internal information as guidance, it becomes difficult to effectively and efficiently trigger deviated behaviors. To tackle this challenge, we propose a novel fitness function to determine the mutated input that is closer to the inputs that can trigger the deviated predictions. Furthermore, TriggerFinder models this search problem as a Markov Chain process and leverages the Metropolis-Hasting algorithm to guide the selection of mutation operators. We evaluated TriggerFinder on 18 compressed models with two datasets. The experiment results demonstrate that TriggerFinder can successfully find triggering inputs for all seed inputs while the baseline fails in certain cases. As for efficiency, TriggerFinder is 5.2x-115.8x as fast as the baselines. Furthermore, the queries required by TriggerFinder to find one triggering input is only 51.8x-535.6x as small as the baseline.