 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR-Coupler: Automated Metamorphic Test Generation via Functional Coupling Analysis
Apr 11, 2026Metamorphic testing (MT) is a widely recognized technique for alleviating the oracle problem in software testing. However, its adoption is hindered by the difficulty of constructing effective metamorphic relations (MRs), which often require domain-specific or hard-to-obtain knowledge. In this work, we propose a novel approach that leverages the functional coupling between methods, which is readily available in source code, to automatically construct MRs and generate metamorphic test cases (MTCs). Our technique, MR-Coupler, identifies functionally coupled method pairs, employs large language models to generate candidate MTCs, and validates them through test amplification and mutation analysis. In particular, we leverage three functional coupling features to avoid expensive enumeration of possible method pairs, and a novel validation mechanism to reduce false alarms. Our evaluation of MR-Coupler on 100 human-written MTCs and 50 real-world bugs shows that it generates valid MTCs for over 90% of tasks, improves valid MTC generation by 64.90%, and reduces false alarms by 36.56% compared to baselines. Furthermore, the MTCs generated by MR-Coupler detect 44% of the real bugs. Our results highlight the effectiveness of leveraging functional coupling for automated MR construction and the potential of MR-Coupler to facilitate the adoption of MT in practice. We also released the tool and experimental data to support future research.
* Note: Accepted on ACM International Conference on the Foundations of Software Engineering (FSE) 2026
Precision in Practice: Knowledge Guided Code Summarizing Grounded in Industrial Expectations
Feb 03, 2026Code summaries are essential for helping developers understand code functionality and reducing maintenance and collaboration costs. Although recent advances in large language models (LLMs) have significantly improved automatic code summarization, the practical usefulness of generated summaries in industrial settings remains insufficiently explored. In collaboration with documentation experts from the industrial HarmonyOS project, we conducted a questionnaire study showing that over 57.4% of code summaries produced by state-of-the-art approaches were rejected due to violations of developers' expectations for industrial documentation. Beyond semantic similarity to reference summaries, developers emphasize additional requirements, including the use of appropriate domain terminology, explicit function categorization, and the avoidance of redundant implementation details. To address these expectations, we propose ExpSum, an expectation-aware code summarization approach that integrates function metadata abstraction, informative metadata filtering, context-aware domain knowledge retrieval, and constraint-driven prompting to guide LLMs in generating structured, expectation-aligned summaries. We evaluate ExpSum on the HarmonyOS project and widely used code summarization benchmarks. Experimental results show that ExpSum consistently outperforms all baselines, achieving improvements of up to 26.71% in BLEU-4 and 20.10% in ROUGE-L on HarmonyOS. Furthermore, LLM-based evaluations indicate that ExpSum-generated summaries better align with developer expectations across other projects, demonstrating its effectiveness for industrial code documentation.
Isolating Language-Coding from Problem-Solving: Benchmarking LLMs with PseudoEval
Feb 26, 2025Existing code generation benchmarks for Large Language Models (LLMs) such as HumanEval and MBPP are designed to study LLMs' end-to-end performance, where the benchmarks feed a problem description in natural language as input and examine the generated code in specific programming languages. However, the evaluation scores revealed in this way provide a little hint as to the bottleneck of the code generation -- whether LLMs are struggling with their problem-solving capability or language-coding capability. To answer this question, we construct PseudoEval, a multilingual code generation benchmark that provides a solution written in pseudocode as input. By doing so, the bottleneck of code generation in various programming languages could be isolated and identified. Our study yields several interesting findings. For example, we identify that the bottleneck of LLMs in Python programming is problem-solving, while Rust is struggling relatively more in language-coding. Also, our study indicates that problem-solving capability may transfer across programming languages, while language-coding needs more language-specific effort, especially for undertrained programming languages. Finally, we release the pipeline of constructing PseudoEval to facilitate the extension to existing benchmarks. PseudoEval is available at: https://anonymous.4open.science/r/PseudocodeACL25-7B74.
CODECLEANER: Elevating Standards with A Robust Data Contamination Mitigation Toolkit
Nov 16, 2024Data contamination presents a critical barrier preventing widespread industrial adoption of advanced software engineering techniques that leverage code language models (CLMs). This phenomenon occurs when evaluation data inadvertently overlaps with the public code repositories used to train CLMs, severely undermining the credibility of performance evaluations. For software companies considering the integration of CLM-based techniques into their development pipeline, this uncertainty about true performance metrics poses an unacceptable business risk. Code refactoring, which comprises code restructuring and variable renaming, has emerged as a promising measure to mitigate data contamination. It provides a practical alternative to the resource-intensive process of building contamination-free evaluation datasets, which would require companies to collect, clean, and label code created after the CLMs' training cutoff dates. However, the lack of automated code refactoring tools and scientifically validated refactoring techniques has hampered widespread industrial implementation. To bridge the gap, this paper presents the first systematic study to examine the efficacy of code refactoring operators at multiple scales (method-level, class-level, and cross-class level) and in different programming languages. In particular, we develop an open-sourced toolkit, CODECLEANER, which includes 11 operators for Python, with nine method-level, one class-level, and one cross-class-level operator. A drop of 65% overlap ratio is found when applying all operators in CODECLEANER, demonstrating their effectiveness in addressing data contamination. Additionally, we migrate four operators to Java, showing their generalizability to another language. We make CODECLEANER online available to facilitate further studies on mitigating CLM data contamination.
Generating Multi-scale Maps from Remote Sensing Images via Series Generative Adversarial Networks
Mar 31, 2021

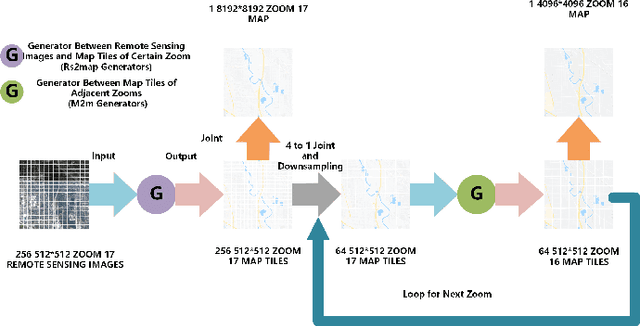
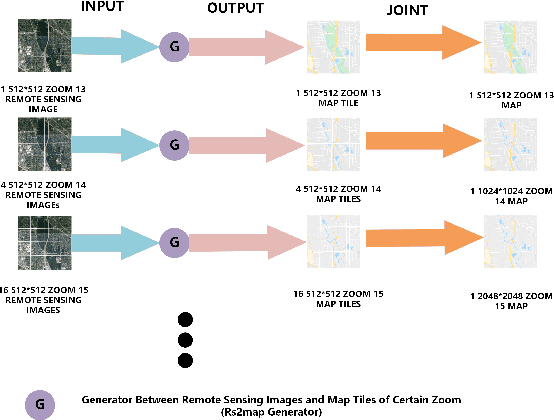
Considering the success of generative adversarial networks (GANs) for image-to-image translation, researchers have attempted to translate remote sensing images (RSIs) to maps (rs2map) through GAN for cartography. However, these studies involved limited scales, which hinders multi-scale map creation. By extending their method, multi-scale RSIs can be trivially translated to multi-scale maps (multi-scale rs2map translation) through scale-wise rs2map models trained for certain scales (parallel strategy). However, this strategy has two theoretical limitations. First, inconsistency between various spatial resolutions of multi-scale RSIs and object generalization on multi-scale maps (RS-m inconsistency) increasingly complicate the extraction of geographical information from RSIs for rs2map models with decreasing scale. Second, as rs2map translation is cross-domain, generators incur high computation costs to transform the RSI pixel distribution to that on maps. Thus, we designed a series strategy of generators for multi-scale rs2map translation to address these limitations. In this strategy, high-resolution RSIs are inputted to an rs2map model to output large-scale maps, which are translated to multi-scale maps through series multi-scale map translation models. The series strategy avoids RS-m inconsistency as inputs are high-resolution large-scale RSIs, and reduces the distribution gap in multi-scale map generation through similar pixel distributions among multi-scale maps. Our experimental results showed better quality multi-scale map generation with the series strategy, as shown by average increases of 11.69%, 53.78%, 55.42%, and 72.34% in the structural similarity index, edge structural similarity index, intersection over union (road), and intersection over union (water) for data from Mexico City and Tokyo at zoom level 17-13.