 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA
Aug 26, 2020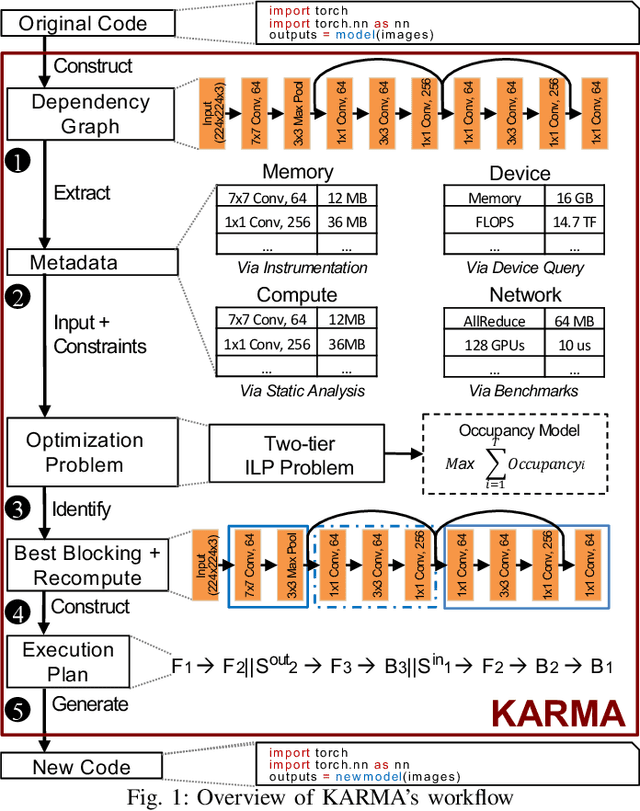
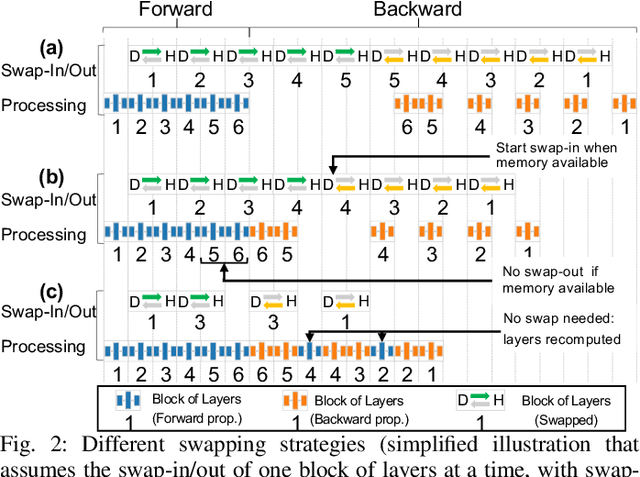
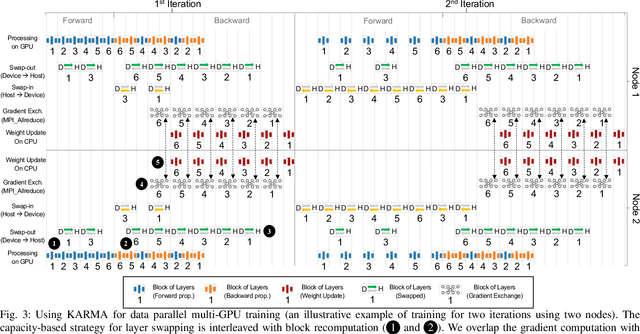

The dedicated memory of hardware accelerators can be insufficient to store all weights and/or intermediate states of large deep learning models. Although model parallelism is a viable approach to reduce the memory pressure issue, significant modification of the source code and considerations for algorithms are required. An alternative solution is to use out-of-core methods instead of, or in addition to, data parallelism. We propose a performance model based on the concurrency analysis of out-of-core training behavior, and derive a strategy that combines layer swapping and redundant recomputing. We achieve an average of 1.52x speedup in six different models over the state-of-the-art out-of-core methods. We also introduce the first method to solve the challenging problem of out-of-core multi-node training by carefully pipelining gradient exchanges and performing the parameter updates on the host. Our data parallel out-of-core solution can outperform complex hybrid model parallelism in training large models, e.g. Megatron-LM and Turning-NLG.
An Effective Algorithm for Learning Single Occurrence Regular Expressions with Interleaving
Jun 05, 2019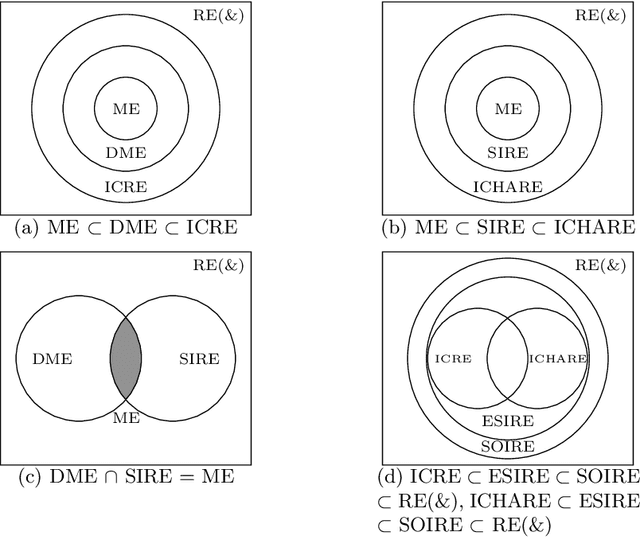
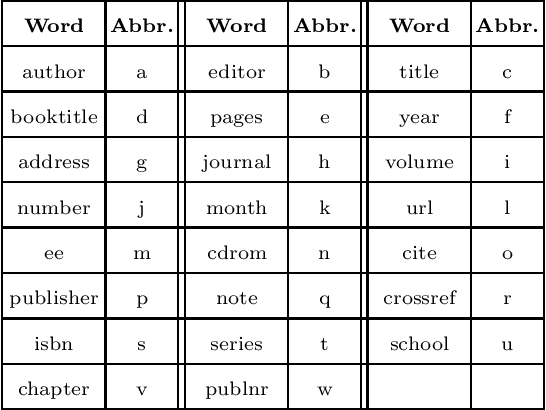
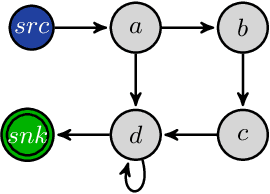
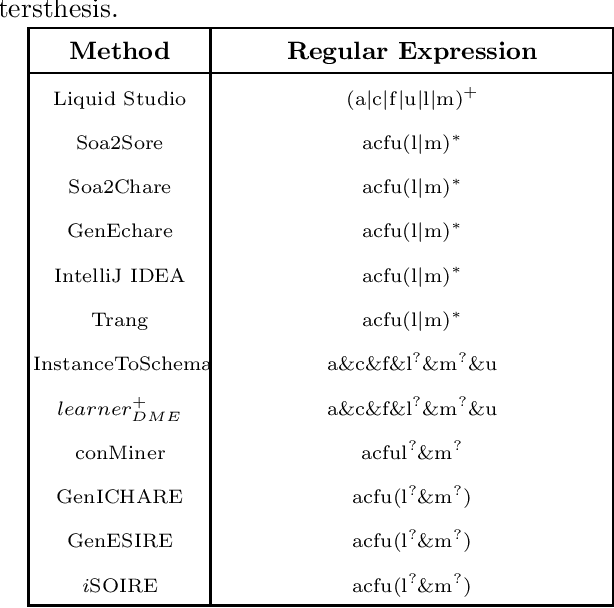
The advantages offered by the presence of a schema are numerous. However, many XML documents in practice are not accompanied by a (valid) schema, making schema inference an attractive research problem. The fundamental task in XML schema learning is inferring restricted subclasses of regular expressions. Most previous work either lacks support for interleaving or only has limited support for interleaving. In this paper, we first propose a new subclass Single Occurrence Regular Expressions with Interleaving (SOIRE), which has unrestricted support for interleaving. Then, based on single occurrence automaton and maximum independent set, we propose an algorithm iSOIRE to infer SOIREs. Finally, we further conduct a series of experiments on real datasets to evaluate the effectiveness of our work, comparing with both ongoing learning algorithms in academia and industrial tools in real-world. The results reveal the practicability of SOIRE and the effectiveness of iSOIRE, showing the high preciseness and conciseness of our work.