 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABCI 3.0: Evolution of the leading AI infrastructure in Japan
Nov 14, 2024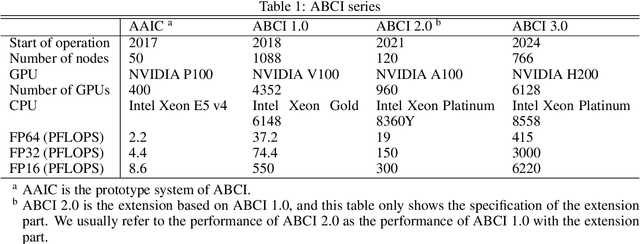
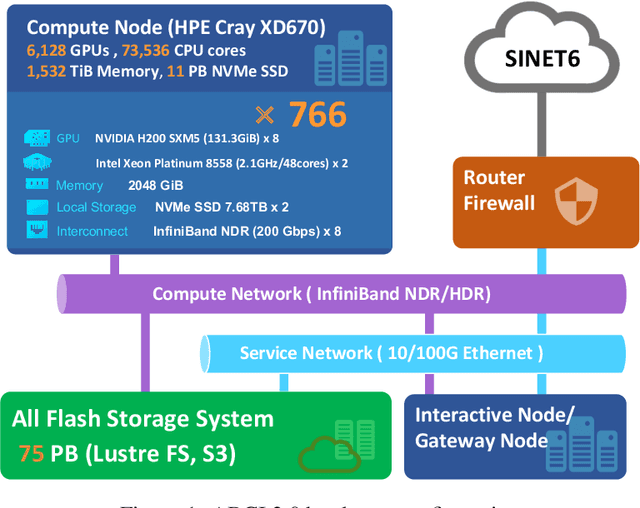


ABCI 3.0 is the latest version of the ABCI, a large-scale open AI infrastructure that AIST has been operating since August 2018 and will be fully operational in January 2025. ABCI 3.0 consists of computing servers equipped with 6128 of the NVIDIA H200 GPUs and an all-flash storage system. Its peak performance is 6.22 exaflops in half precision and 3.0 exaflops in single precision, which is 7 to 13 times faster than the previous system, ABCI 2.0. It also more than doubles both storage capacity and theoretical read/write performance. ABCI 3.0 is expected to accelerate research and development, evaluation, and workforce development of cutting-edge AI technologies, with a particular focus on generative AI.
An Oracle for Guiding Large-Scale Model/Hybrid Parallel Training of Convolutional Neural Networks
Apr 19, 2021


Deep Neural Network (DNN) frameworks use distributed training to enable faster time to convergence and alleviate memory capacity limitations when training large models and/or using high dimension inputs. With the steady increase in datasets and model sizes, model/hybrid parallelism is deemed to have an important role in the future of distributed training of DNNs. We analyze the compute, communication, and memory requirements of Convolutional Neural Networks (CNNs) to understand the trade-offs between different parallelism approaches on performance and scalability. We leverage our model-driven analysis to be the basis for an oracle utility which can help in detecting the limitations and bottlenecks of different parallelism approaches at scale. We evaluate the oracle on six parallelization strategies, with four CNN models and multiple datasets (2D and 3D), on up to 1024 GPUs. The results demonstrate that the oracle has an average accuracy of about 86.74% when compared to empirical results, and as high as 97.57% for data parallelism.
Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA
Aug 26, 2020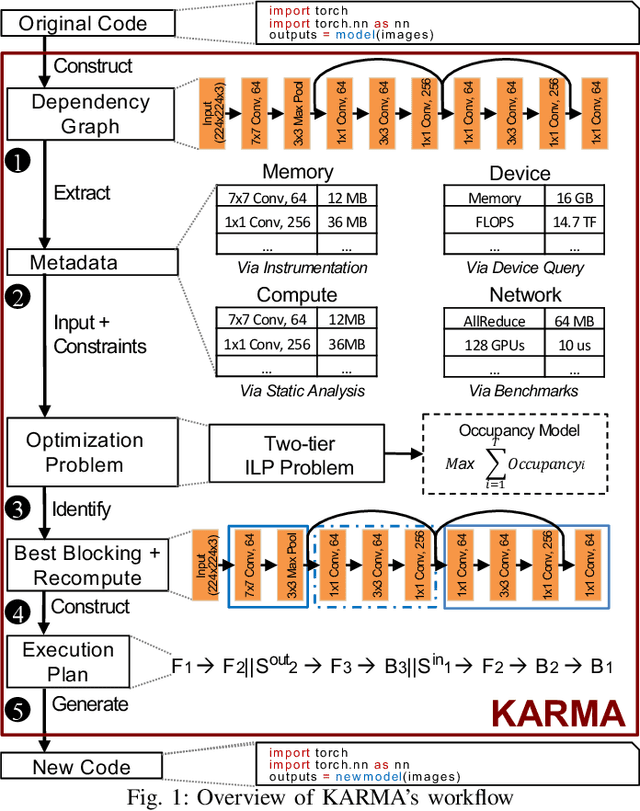
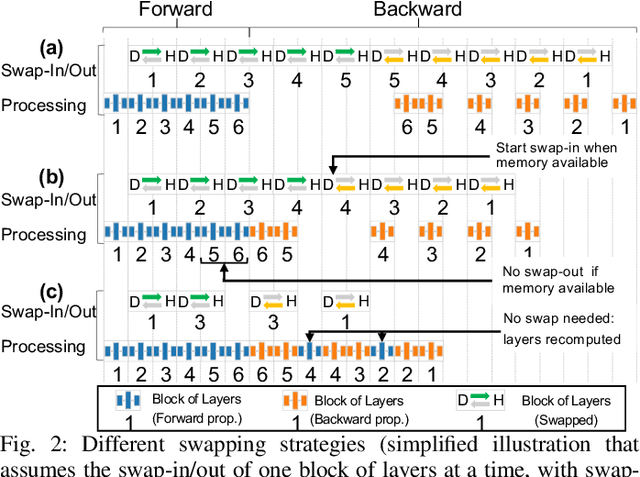
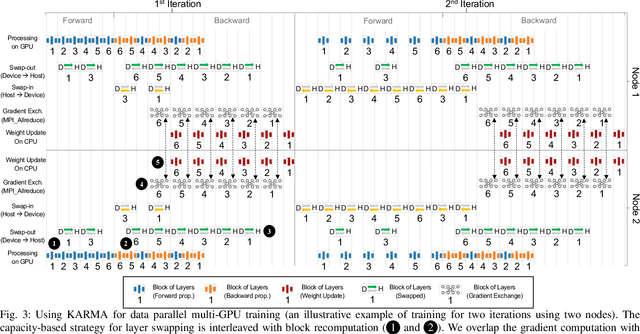

The dedicated memory of hardware accelerators can be insufficient to store all weights and/or intermediate states of large deep learning models. Although model parallelism is a viable approach to reduce the memory pressure issue, significant modification of the source code and considerations for algorithms are required. An alternative solution is to use out-of-core methods instead of, or in addition to, data parallelism. We propose a performance model based on the concurrency analysis of out-of-core training behavior, and derive a strategy that combines layer swapping and redundant recomputing. We achieve an average of 1.52x speedup in six different models over the state-of-the-art out-of-core methods. We also introduce the first method to solve the challenging problem of out-of-core multi-node training by carefully pipelining gradient exchanges and performing the parameter updates on the host. Our data parallel out-of-core solution can outperform complex hybrid model parallelism in training large models, e.g. Megatron-LM and Turning-NLG.
Perturbative GAN: GAN with Perturbation Layers
Feb 05, 2019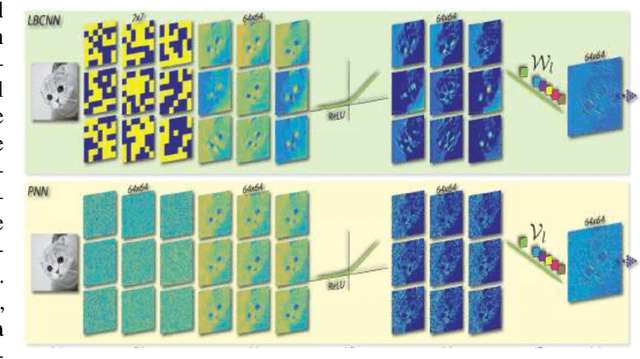
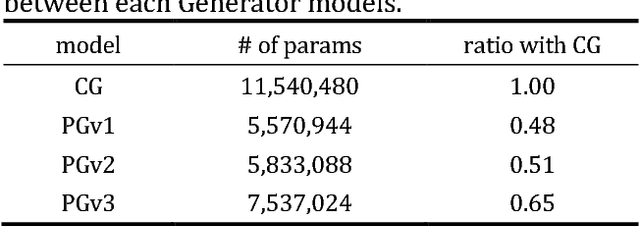
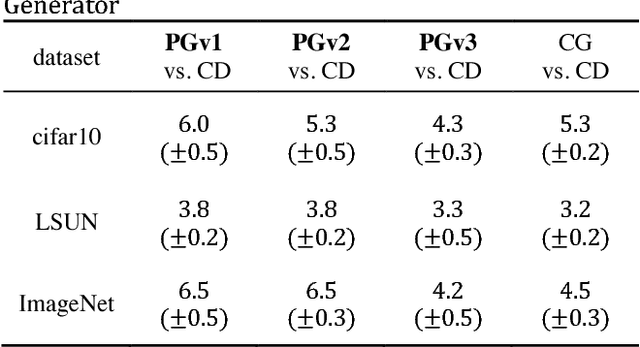
Perturbative GAN, which replaces convolution layers of existing convolutional GANs (DCGAN, WGAN-GP, BIGGAN, etc.) with perturbation layers that adds a fixed noise mask, is proposed. Compared with the convolu-tional GANs, the number of parameters to be trained is smaller, the convergence of training is faster, the incep-tion score of generated images is higher, and the overall training cost is reduced. Algorithmic generation of the noise masks is also proposed, with which the training, as well as the generation, can be boosted with hardware acceleration. Perturbative GAN is evaluated using con-ventional datasets (CIFAR10, LSUN, ImageNet), both in the cases when a perturbation layer is adopted only for Generators and when it is introduced to both Generator and Discriminator.