 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Decoder Attention Network with Contour-weighted Loss Function for Data-Imbalance Medical Image Segmentation
Jan 20, 2026Image segmentation is pivotal in medical image analysis, facilitating clinical diagnosis, treatment planning, and disease evaluation. Deep learning has significantly advanced automatic segmentation methodologies by providing superior modeling capability for complex structures and fine-grained anatomical regions. However, medical images often suffer from data imbalance issues, such as large volume disparities among organs or tissues, and uneven sample distributions across different anatomical structures. This imbalance tends to bias the model toward larger organs or more frequently represented structures, while overlooking smaller or less represented structures, thereby affecting the segmentation accuracy and robustness. To address these challenges, we proposed a novel contour-weighted segmentation approach, which improves the model's capability to represent small and underrepresented structures. We developed PDANet, a lightweight and efficient segmentation network based on a partial decoder mechanism. We evaluated our method using three prominent public datasets. The experimental results show that our methodology excelled in three distinct tasks: segmenting multiple abdominal organs, brain tumors, and pelvic bone fragments with injuries. It consistently outperformed nine state-of-the-art methods. Moreover, the proposed contour-weighted strategy improved segmentation for other comparison methods across the three datasets, yielding average enhancements in Dice scores of 2.32%, 1.67%, and 3.60%, respectively. These results demonstrate that our contour-weighted segmentation method surpassed current leading approaches in both accuracy and robustness. As a model-independent strategy, it can seamlessly fit various segmentation frameworks, enhancing their performance. This flexibility highlighted its practical importance and potential for broad use in medical image analysis.
Bine Trees: Enhancing Collective Operations by Optimizing Communication Locality
Aug 24, 2025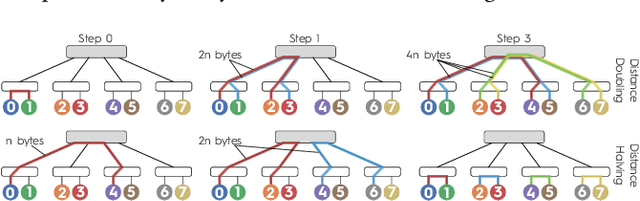



Communication locality plays a key role in the performance of collective operations on large HPC systems, especially on oversubscribed networks where groups of nodes are fully connected internally but sparsely linked through global connections. We present Bine (binomial negabinary) trees, a family of collective algorithms that improve communication locality. Bine trees maintain the generality of binomial trees and butterflies while cutting global-link traffic by up to 33%. We implement eight Bine-based collectives and evaluate them on four large-scale supercomputers with Dragonfly, Dragonfly+, oversubscribed fat-tree, and torus topologies, achieving up to 5x speedups and consistent reductions in global-link traffic across different vector sizes and node counts.
Myths and Legends in High-Performance Computing
Jan 06, 2023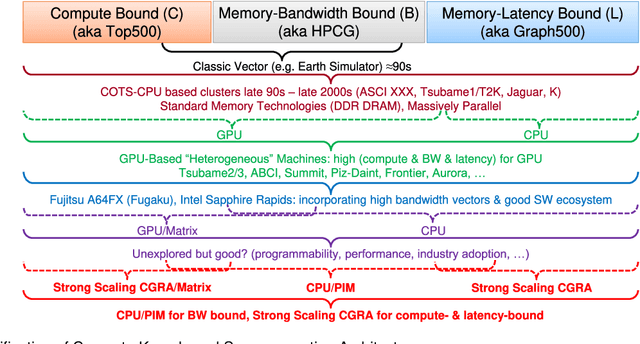
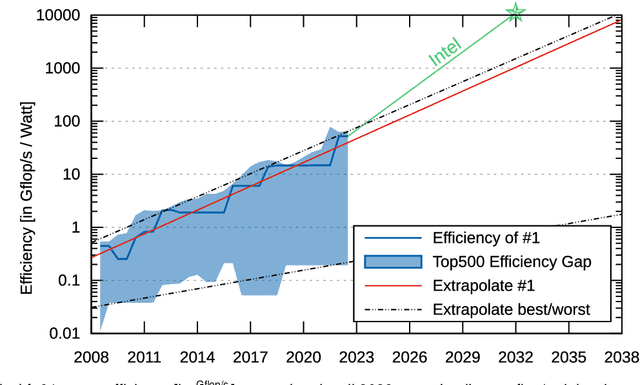
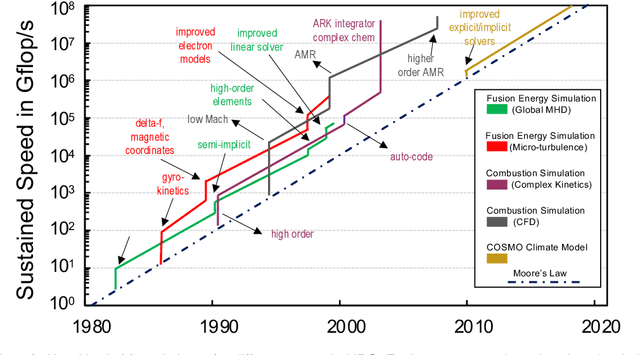
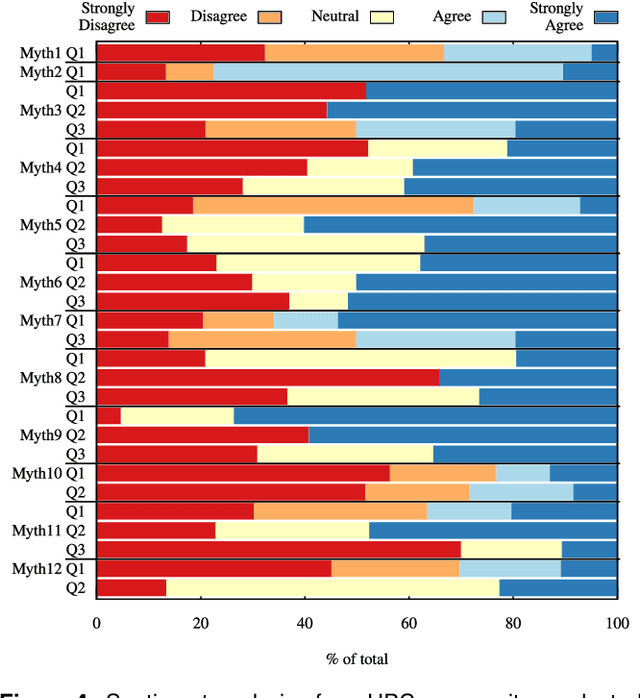
In this humorous and thought provoking article, we discuss certain myths and legends that are folklore among members of the high-performance computing community. We collected those myths from conversations at conferences and meetings, product advertisements, papers, and other communications such as tweets, blogs, and news articles within (and beyond) our community. We believe they represent the zeitgeist of the current era of massive change, driven by the end of many scaling laws such as Dennard scaling and Moore's law. While some laws end, new directions open up, such as algorithmic scaling or novel architecture research. However, these myths are rarely based on scientific facts but often on some evidence or argumentation. In fact, we believe that this is the very reason for the existence of many myths and why they cannot be answered clearly. While it feels like there should be clear answers for each, some may remain endless philosophical debates such as the question whether Beethoven was better than Mozart. We would like to see our collection of myths as a discussion of possible new directions for research and industry investment.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021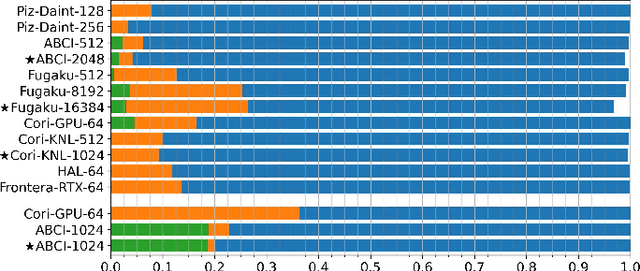
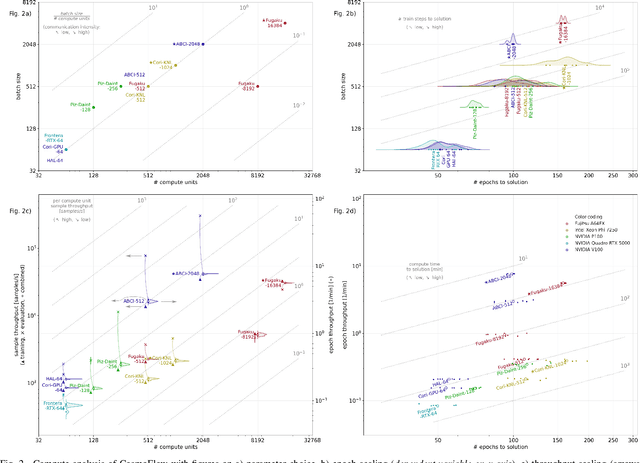
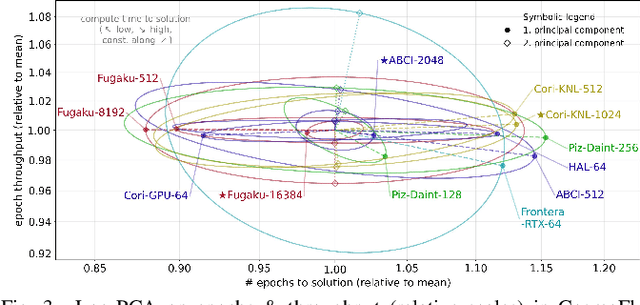
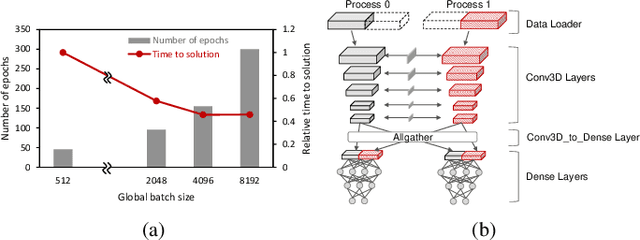
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA
Aug 26, 2020
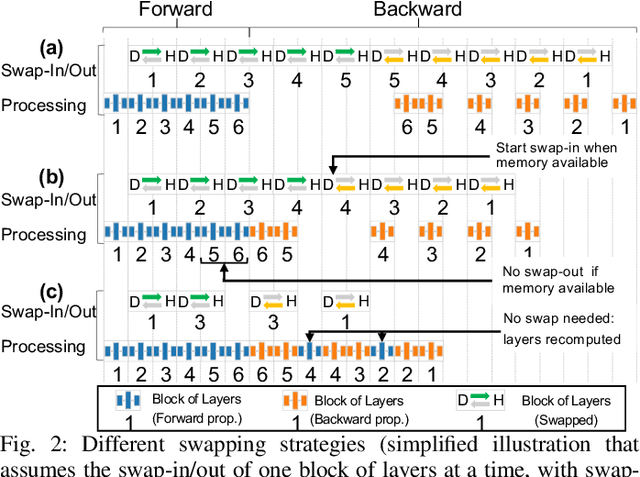
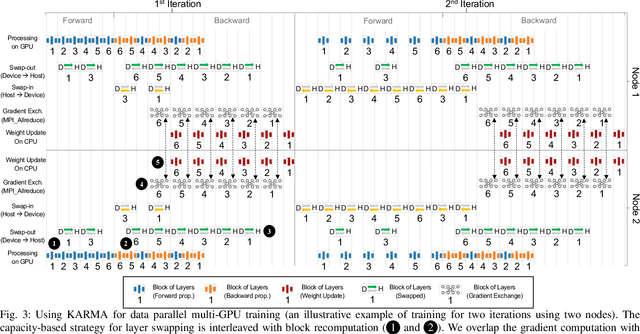

The dedicated memory of hardware accelerators can be insufficient to store all weights and/or intermediate states of large deep learning models. Although model parallelism is a viable approach to reduce the memory pressure issue, significant modification of the source code and considerations for algorithms are required. An alternative solution is to use out-of-core methods instead of, or in addition to, data parallelism. We propose a performance model based on the concurrency analysis of out-of-core training behavior, and derive a strategy that combines layer swapping and redundant recomputing. We achieve an average of 1.52x speedup in six different models over the state-of-the-art out-of-core methods. We also introduce the first method to solve the challenging problem of out-of-core multi-node training by carefully pipelining gradient exchanges and performing the parameter updates on the host. Our data parallel out-of-core solution can outperform complex hybrid model parallelism in training large models, e.g. Megatron-LM and Turning-NLG.