 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Visual Programming for Visual Reasoning via Probabilistic Graphs
Dec 16, 2025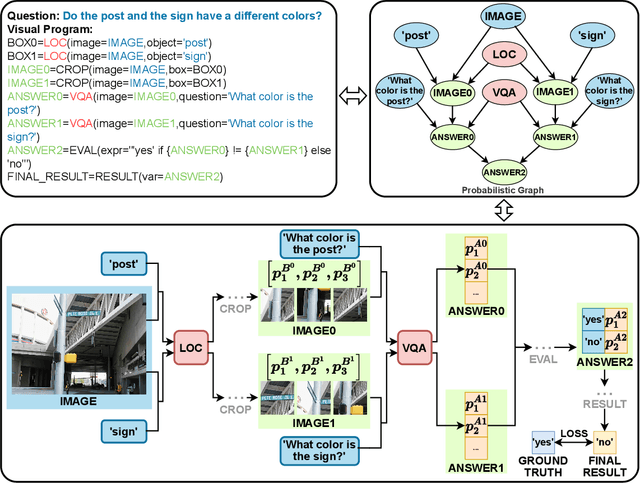


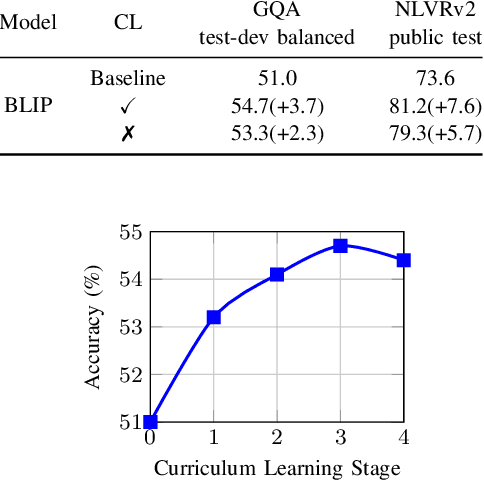
Recently, Visual Programming (VP) based on large language models (LLMs) has rapidly developed and demonstrated significant potential in complex Visual Reasoning (VR) tasks. Previous works to enhance VP have primarily focused on improving the quality of LLM-generated visual programs. However, they have neglected to optimize the VP-invoked pre-trained models, which serve as modules for the visual sub-tasks decomposed from the targeted tasks by VP. The difficulty is that there are only final labels of targeted VR tasks rather than labels of sub-tasks. Besides, the non-differentiable nature of VP impedes the direct use of efficient gradient-based optimization methods to leverage final labels for end-to-end learning of the entire VP framework. To overcome these issues, we propose EVPG, a method to Enhance Visual Programming for visual reasoning via Probabilistic Graphs. Specifically, we creatively build a directed probabilistic graph according to the variable dependency relationships during the VP executing process, which reconstructs the non-differentiable VP executing process into a differentiable exact probability inference process on this directed probabilistic graph. As a result, this enables the VP framework to utilize the final labels for efficient, gradient-based optimization in end-to-end supervised learning on targeted VR tasks. Extensive and comprehensive experiments demonstrate the effectiveness and advantages of our EVPG, showing significant performance improvements for VP on three classical complex VR tasks: GQA, NLVRv2, and Open Images.
SR-FoT: A Syllogistic-Reasoning Framework of Thought for Large Language Models Tackling Knowledge-based Reasoning Tasks
Jan 20, 2025Deductive reasoning is a crucial logical capability that assists us in solving complex problems based on existing knowledge. Although augmented by Chain-of-Thought prompts, Large Language Models (LLMs) might not follow the correct reasoning paths. Enhancing the deductive reasoning abilities of LLMs, and leveraging their extensive built-in knowledge for various reasoning tasks, remains an open question. Attempting to mimic the human deductive reasoning paradigm, we propose a multi-stage Syllogistic-Reasoning Framework of Thought (SR-FoT) that enables LLMs to perform syllogistic deductive reasoning to handle complex knowledge-based reasoning tasks. Our SR-FoT begins by interpreting the question and then uses the interpretation and the original question to propose a suitable major premise. It proceeds by generating and answering minor premise questions in two stages to match the minor premises. Finally, it guides LLMs to use the previously generated major and minor premises to perform syllogistic deductive reasoning to derive the answer to the original question. Extensive and thorough experiments on knowledge-based reasoning tasks have demonstrated the effectiveness and advantages of our SR-FoT.
VisualProg Distiller: Learning to Fine-tune Non-differentiable Visual Programming Frameworks
Sep 18, 2023As an interpretable and universal neuro-symbolic paradigm based on Large Language Models, visual programming (VisualProg) can execute compositional visual tasks without training, but its performance is markedly inferior compared to task-specific supervised learning models. To increase its practicality, the performance of VisualProg on specific tasks needs to be improved. However, the non-differentiability of VisualProg limits the possibility of employing the fine-tuning strategy on specific tasks to achieve further improvements. In our analysis, we discovered that significant performance issues in VisualProg's execution originated from errors made by the sub-modules at corresponding visual sub-task steps. To address this, we propose ``VisualProg Distiller", a method of supplementing and distilling process knowledge to optimize the performance of each VisualProg sub-module on decoupled visual sub-tasks, thus enhancing the overall task performance. Specifically, we choose an end-to-end model that is well-performed on the given task as the teacher and further distill the knowledge of the teacher into the invoked visual sub-modules step-by-step based on the execution flow of the VisualProg-generated programs. In this way, our method is capable of facilitating the fine-tuning of the non-differentiable VisualProg frameworks effectively. Extensive and comprehensive experimental evaluations demonstrate that our method can achieve a substantial performance improvement of VisualProg, and outperforms all the compared state-of-the-art methods by large margins. Furthermore, to provide valuable process supervision for the GQA task, we construct a large-scale dataset by utilizing the distillation process of our method.