 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORACLE: Optimizing Reasoning Abilities of Large Language Models via Constraint-Led Synthetic Data Elicitation
Mar 22, 2026Training large language models (LLMs) with synthetic reasoning data has become a popular approach to enhancing their reasoning capabilities, while a key factor influencing the effectiveness of this paradigm is the quality of the generated multi-step reasoning data. To generate high-quality reasoning data, many recent methods generate synthetic reasoning paths and filter them based on final answer correctness, often overlooking flaws in intermediate reasoning steps. To enhance the verification of intermediate reasoning steps, prior work primarily resorts to code execution or symbolic reasoning engines. However, code-based validation is restricted to code or mathematical tasks, and reasoning engines require a well-structured and complete context. As a result, existing methods fail to function effectively in natural language reasoning tasks that involve ambiguous or incomplete contexts. In these tasks, synthetic data still lack reliable checks for verifying each reasoning step. To address this challenge, we introduce ORACLE, a structured data generation framework inspired by syllogistic reasoning. ORACLE integrates the generative strengths of LLMs with symbolic supervision: the LLM produces step-wise reasoning contexts, while a symbolic reasoning engine verifies the validity of each intermediate step. By employing a unified prompting template to elicit modular reasoning chains, ORACLE enables fine-grained, step-level validation, facilitating the construction of high-quality multi-step reasoning data. Across six logical, factual, and commonsense reasoning benchmarks, our ORACLE consistently outperforms strong baselines on multiple models.
Massive Editing for Large Language Models Based on Dynamic Weight Generation
Dec 17, 2025Knowledge Editing (KE) is a field that studies how to modify some knowledge in Large Language Models (LLMs) at a low cost (compared to pre-training). Currently, performing large-scale edits on LLMs while ensuring the Reliability, Generality, and Locality metrics of the edits remain a challenge. This paper proposes a Massive editing approach for LLMs based on dynamic weight Generation (MeG). Our MeG involves attaching a dynamic weight neuron to specific layers of the LLMs and using a diffusion model to conditionally generate the weights of this neuron based on the input query required for the knowledge. This allows the use of adding a single dynamic weight neuron to achieve the goal of large-scale knowledge editing. Experiments show that our MeG can significantly improve the performance of large-scale KE in terms of Reliability, Generality, and Locality metrics compared to existing knowledge editing methods, particularly with a high percentage point increase in the absolute value index for the Locality metric, demonstrating the advantages of our proposed method.
Enhancing Visual Programming for Visual Reasoning via Probabilistic Graphs
Dec 16, 2025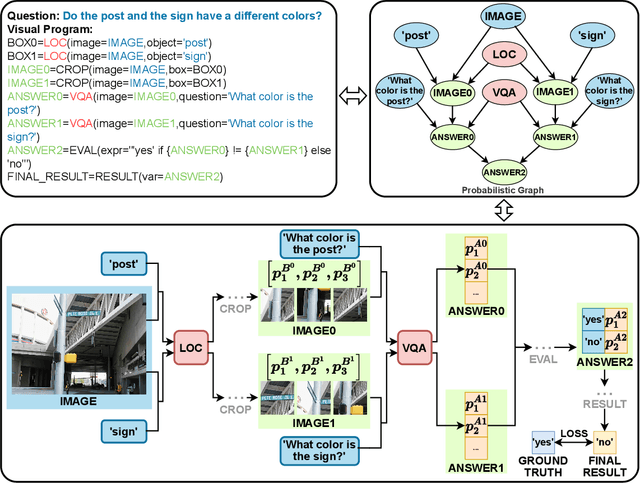


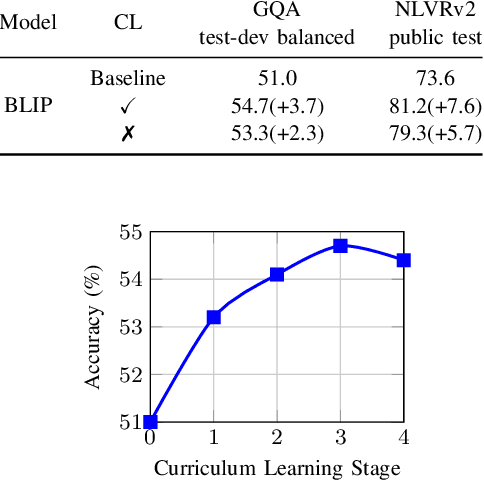
Recently, Visual Programming (VP) based on large language models (LLMs) has rapidly developed and demonstrated significant potential in complex Visual Reasoning (VR) tasks. Previous works to enhance VP have primarily focused on improving the quality of LLM-generated visual programs. However, they have neglected to optimize the VP-invoked pre-trained models, which serve as modules for the visual sub-tasks decomposed from the targeted tasks by VP. The difficulty is that there are only final labels of targeted VR tasks rather than labels of sub-tasks. Besides, the non-differentiable nature of VP impedes the direct use of efficient gradient-based optimization methods to leverage final labels for end-to-end learning of the entire VP framework. To overcome these issues, we propose EVPG, a method to Enhance Visual Programming for visual reasoning via Probabilistic Graphs. Specifically, we creatively build a directed probabilistic graph according to the variable dependency relationships during the VP executing process, which reconstructs the non-differentiable VP executing process into a differentiable exact probability inference process on this directed probabilistic graph. As a result, this enables the VP framework to utilize the final labels for efficient, gradient-based optimization in end-to-end supervised learning on targeted VR tasks. Extensive and comprehensive experiments demonstrate the effectiveness and advantages of our EVPG, showing significant performance improvements for VP on three classical complex VR tasks: GQA, NLVRv2, and Open Images.
SR-FoT: A Syllogistic-Reasoning Framework of Thought for Large Language Models Tackling Knowledge-based Reasoning Tasks
Jan 20, 2025Deductive reasoning is a crucial logical capability that assists us in solving complex problems based on existing knowledge. Although augmented by Chain-of-Thought prompts, Large Language Models (LLMs) might not follow the correct reasoning paths. Enhancing the deductive reasoning abilities of LLMs, and leveraging their extensive built-in knowledge for various reasoning tasks, remains an open question. Attempting to mimic the human deductive reasoning paradigm, we propose a multi-stage Syllogistic-Reasoning Framework of Thought (SR-FoT) that enables LLMs to perform syllogistic deductive reasoning to handle complex knowledge-based reasoning tasks. Our SR-FoT begins by interpreting the question and then uses the interpretation and the original question to propose a suitable major premise. It proceeds by generating and answering minor premise questions in two stages to match the minor premises. Finally, it guides LLMs to use the previously generated major and minor premises to perform syllogistic deductive reasoning to derive the answer to the original question. Extensive and thorough experiments on knowledge-based reasoning tasks have demonstrated the effectiveness and advantages of our SR-FoT.
Is this Generated Person Existed in Real-world? Fine-grained Detecting and Calibrating Abnormal Human-body
Nov 21, 2024



Recent improvements in visual synthesis have significantly enhanced the depiction of generated human photos, which are pivotal due to their wide applicability and demand. Nonetheless, the existing text-to-image or text-to-video models often generate low-quality human photos that might differ considerably from real-world body structures, referred to as "abnormal human bodies". Such abnormalities, typically deemed unacceptable, pose considerable challenges in the detection and repair of them within human photos. These challenges require precise abnormality recognition capabilities, which entail pinpointing both the location and the abnormality type. Intuitively, Visual Language Models (VLMs) that have obtained remarkable performance on various visual tasks are quite suitable for this task. However, their performance on abnormality detection in human photos is quite poor. Hence, it is quite important to highlight this task for the research community. In this paper, we first introduce a simple yet challenging task, i.e., \textbf{F}ine-grained \textbf{H}uman-body \textbf{A}bnormality \textbf{D}etection \textbf{(FHAD)}, and construct two high-quality datasets for evaluation. Then, we propose a meticulous framework, named HumanCalibrator, which identifies and repairs abnormalities in human body structures while preserving the other content. Experiments indicate that our HumanCalibrator achieves high accuracy in abnormality detection and accomplishes an increase in visual comparisons while preserving the other visual content.
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Nov 29, 2023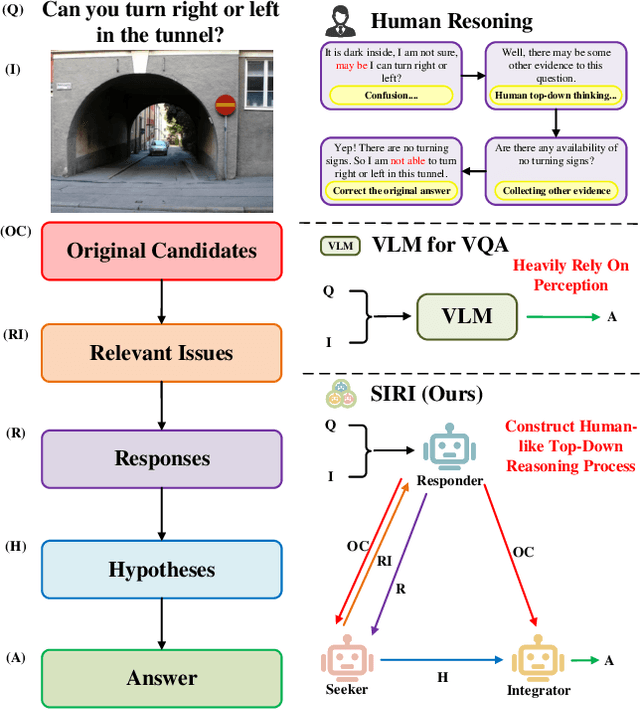

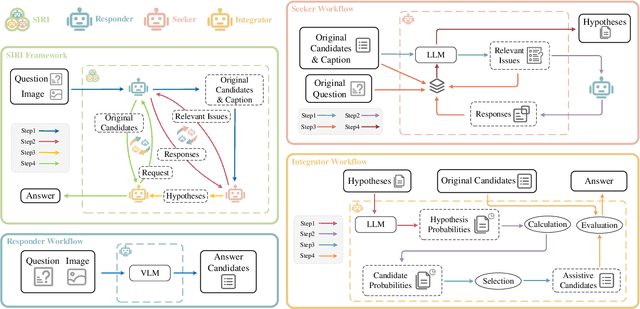

Recently, Vision Language Models (VLMs) have gained significant attention, exhibiting notable advancements across various tasks by leveraging extensive image-text paired data. However, prevailing VLMs often treat Visual Question Answering (VQA) as perception tasks, employing black-box models that overlook explicit modeling of relationships between different questions within the same visual scene. Moreover, the existing VQA methods that rely on Knowledge Bases (KBs) might frequently encounter biases from limited data and face challenges in relevant information indexing. Attempt to overcome these limitations, this paper introduces an explainable multi-agent collaboration framework by tapping into knowledge embedded in Large Language Models (LLMs) trained on extensive corpora. Inspired by human cognition, our framework uncovers latent information within the given question by employing three agents, i.e., Seeker, Responder, and Integrator, to perform a top-down reasoning process. The Seeker agent generates relevant issues related to the original question. The Responder agent, based on VLM, handles simple VQA tasks and provides candidate answers. The Integrator agent combines information from the Seeker agent and the Responder agent to produce the final VQA answer. Through the above collaboration mechanism, our framework explicitly constructs a multi-view knowledge base for a specific image scene, reasoning answers in a top-down processing manner. We extensively evaluate our method on diverse VQA datasets and VLMs, demonstrating its broad applicability and interpretability with comprehensive experimental results.
VisualProg Distiller: Learning to Fine-tune Non-differentiable Visual Programming Frameworks
Sep 18, 2023As an interpretable and universal neuro-symbolic paradigm based on Large Language Models, visual programming (VisualProg) can execute compositional visual tasks without training, but its performance is markedly inferior compared to task-specific supervised learning models. To increase its practicality, the performance of VisualProg on specific tasks needs to be improved. However, the non-differentiability of VisualProg limits the possibility of employing the fine-tuning strategy on specific tasks to achieve further improvements. In our analysis, we discovered that significant performance issues in VisualProg's execution originated from errors made by the sub-modules at corresponding visual sub-task steps. To address this, we propose ``VisualProg Distiller", a method of supplementing and distilling process knowledge to optimize the performance of each VisualProg sub-module on decoupled visual sub-tasks, thus enhancing the overall task performance. Specifically, we choose an end-to-end model that is well-performed on the given task as the teacher and further distill the knowledge of the teacher into the invoked visual sub-modules step-by-step based on the execution flow of the VisualProg-generated programs. In this way, our method is capable of facilitating the fine-tuning of the non-differentiable VisualProg frameworks effectively. Extensive and comprehensive experimental evaluations demonstrate that our method can achieve a substantial performance improvement of VisualProg, and outperforms all the compared state-of-the-art methods by large margins. Furthermore, to provide valuable process supervision for the GQA task, we construct a large-scale dataset by utilizing the distillation process of our method.