 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Paper and Code
Nov 29, 2023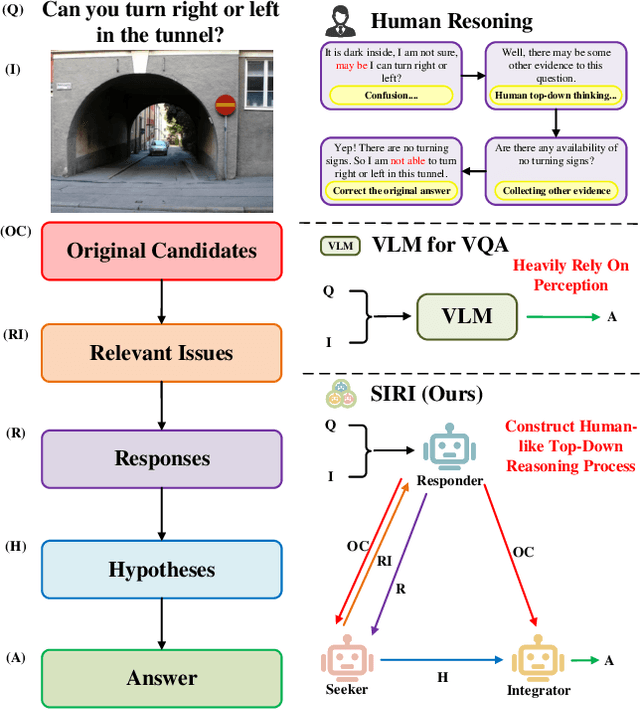

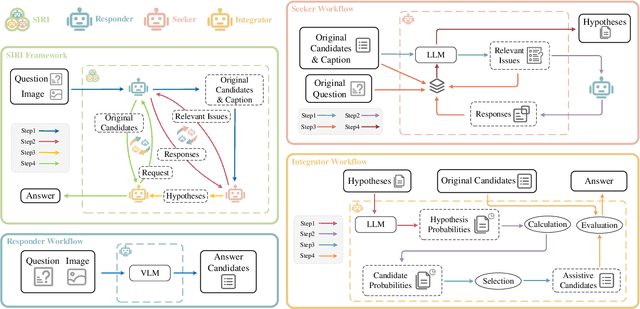

Recently, Vision Language Models (VLMs) have gained significant attention, exhibiting notable advancements across various tasks by leveraging extensive image-text paired data. However, prevailing VLMs often treat Visual Question Answering (VQA) as perception tasks, employing black-box models that overlook explicit modeling of relationships between different questions within the same visual scene. Moreover, the existing VQA methods that rely on Knowledge Bases (KBs) might frequently encounter biases from limited data and face challenges in relevant information indexing. Attempt to overcome these limitations, this paper introduces an explainable multi-agent collaboration framework by tapping into knowledge embedded in Large Language Models (LLMs) trained on extensive corpora. Inspired by human cognition, our framework uncovers latent information within the given question by employing three agents, i.e., Seeker, Responder, and Integrator, to perform a top-down reasoning process. The Seeker agent generates relevant issues related to the original question. The Responder agent, based on VLM, handles simple VQA tasks and provides candidate answers. The Integrator agent combines information from the Seeker agent and the Responder agent to produce the final VQA answer. Through the above collaboration mechanism, our framework explicitly constructs a multi-view knowledge base for a specific image scene, reasoning answers in a top-down processing manner. We extensively evaluate our method on diverse VQA datasets and VLMs, demonstrating its broad applicability and interpretability with comprehensive experimental results.