 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Meta-Learning-based Poisoning Attacks for Graph Link Prediction
Apr 08, 2025



Link prediction in graph data utilizes various algorithms and machine learning/deep learning models to predict potential relationships between graph nodes. This technique has found widespread use in numerous real-world applications, including recommendation systems, community networks, and biological structures. However, recent research has highlighted the vulnerability of link prediction models to adversarial attacks, such as poisoning and evasion attacks. Addressing the vulnerability of these models is crucial to ensure stable and robust performance in link prediction applications. While many works have focused on enhancing the robustness of the Graph Convolution Network (GCN) model, the Variational Graph Auto-Encoder (VGAE), a sophisticated model for link prediction, has not been thoroughly investigated in the context of graph adversarial attacks. To bridge this gap, this article proposes an unweighted graph poisoning attack approach using meta-learning techniques to undermine VGAE's link prediction performance. We conducted comprehensive experiments on diverse datasets to evaluate the proposed method and its parameters, comparing it with existing approaches in similar settings. Our results demonstrate that our approach significantly diminishes link prediction performance and outperforms other state-of-the-art methods.
Cross-Model Transferability of Adversarial Patches in Real-time Segmentation for Autonomous Driving
Feb 22, 2025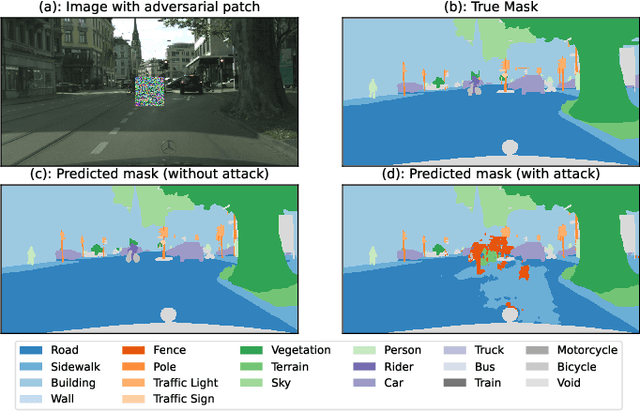
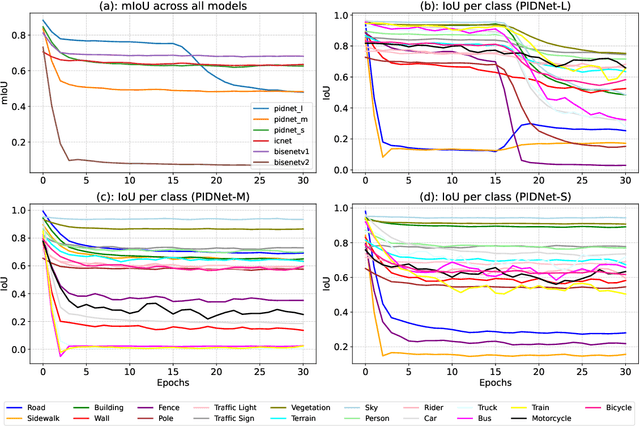


Adversarial attacks pose a significant threat to deep learning models, particularly in safety-critical applications like healthcare and autonomous driving. Recently, patch based attacks have demonstrated effectiveness in real-time inference scenarios owing to their 'drag and drop' nature. Following this idea for Semantic Segmentation (SS), here we propose a novel Expectation Over Transformation (EOT) based adversarial patch attack that is more realistic for autonomous vehicles. To effectively train this attack we also propose a 'simplified' loss function that is easy to analyze and implement. Using this attack as our basis, we investigate whether adversarial patches once optimized on a specific SS model, can fool other models or architectures. We conduct a comprehensive cross-model transferability analysis of adversarial patches trained on SOTA Convolutional Neural Network (CNN) models such PIDNet-S, PIDNet-M and PIDNet-L, among others. Additionally, we also include the Segformer model to study transferability to Vision Transformers (ViTs). All of our analysis is conducted on the widely used Cityscapes dataset. Our study reveals key insights into how model architectures (CNN vs CNN or CNN vs. Transformer-based) influence attack susceptibility. In particular, we conclude that although the transferability (effectiveness) of attacks on unseen images of any dimension is really high, the attacks trained against one particular model are minimally effective on other models. And this was found to be true for both ViT and CNN based models. Additionally our results also indicate that for CNN-based models, the repercussions of patch attacks are local, unlike ViTs. Per-class analysis reveals that simple-classes like 'sky' suffer less misclassification than others. The code for the project is available at: https://github.com/p-shekhar/adversarial-patch-transferability