 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generation and Mitigation of Harmful Geometry in Image-to-3D Models
May 10, 2026Recent advances in image-to-3D models have significantly improved the fidelity and accessibility of 3D content creation. Such a powerful reconstruction capability that enables creative design can also be misused by the adversary to generate harmful geometries, which can be further fabricated via 3D printers and pose real-world risks. However, such risks are largely underexplored: it remains unclear how well current image-to-3D models can produce these harmful geometries, and whether existing safeguards can reliably prevent such generation. To fill this gap, we conduct a systematic measurement study of harmful geometry generation and mitigation. We first describe this risk through three kinds of unsafe categories: direct-use physical hazards, risky templates or components, and deceptive replicas. Each category is instantiated with representative objects. We evaluate both open-source and commercial image-to-3D models under original, degraded, viewpoint-shifted, and semantically camouflaged inputs. We consider different evaluation metrics, including geometric validity, multi-view VLM-based semantic scoring, targeted human validation, and controlled physical fabrication. The results reveal a concerning reality that current image-to-3D models can effectively reconstruct the harmful geometries, while fewer than 0.3% of such geometries trigger commercial moderation flags. As a first step toward mitigation, we evaluate three representative safeguard families, including input moderation, model-level benign alignment, and output-level filtering. We find that existing safeguards have distinct weaknesses. We further develop a stacked defense that can reduce harmful retention to <1%, but still at 11% overall false-positive cost. Taken together, our findings demonstrate that the risk in current system and encourage better geometry-aware safeguards for moderation.
Stego Battlefield: Evaluating Image Steganography Attacks and Steganalysis Defenses
May 07, 2026Image steganography is widely used to protect user privacy and enable covert communication. However, it can also be abused by the adversary as a covert channel to bypass content moderation, disseminate harmful semantics, and even hide malicious instructions in images to elicit dangerous outputs from large models, posing a practical security risk that continues to evolve. To address the lack of a unified and systematic evaluation framework, we propose SADBench, a systematic benchmark that assesses the adversary's ability to inject harmful secrets via steganography and the defender's ability to detect such threats through steganalysis. Crucially, SADBench comprises $4$ core tasks, namely steganography attack capability evaluation, steganalysis defense capability evaluation, efficiency evaluation, and transferability evaluation. It evaluates both image-payload and text-payload steganography across diverse cover distributions, utilizing harmful visual semantics and toxic instructions to simulate malicious attacks. Across a broad set of attacks and detectors, SADBench reveals that (i) INN and autoencoder-based methods demonstrate superior stability compared to other architectures, (ii) in-domain detection is near-perfect and cheaper than generation, (iii) a critical asymmetry exists in transferability where attacks robustly generalize to new distributions while detectors fail to adapt, and (iv) real-world threats persist on social media, where payloads either survive minimal compression or effectively adapt to aggressive compression via simulated training. Overall, SADBench establishes a systematic, reproducible, and extensible framework to quantify risks, paving the way for measurable and security-driven advancements in steganography defense.
CHASM: Unveiling Covert Advertisements on Chinese Social Media
Apr 22, 2026Current benchmarks for evaluating large language models (LLMs) in social media moderation completely overlook a serious threat: covert advertisements, which disguise themselves as regular posts to deceive and mislead consumers into making purchases, leading to significant ethical and legal concerns. In this paper, we present the CHASM, a first-of-its-kind dataset designed to evaluate the capability of Multimodal Large Language Models (MLLMs) in detecting covert advertisements on social media. CHASM is a high-quality, anonymized, manually curated dataset consisting of 4,992 instances, based on real-world scenarios from the Chinese social media platform Rednote. The dataset was collected and annotated under strict privacy protection and quality control protocols. It includes many product experience sharing posts that closely resemble covert advertisements, making the dataset particularly challenging.The results show that under both zero-shot and in-context learning settings, none of the current MLLMs are sufficiently reliable for detecting covert advertisements.Our further experiments revealed that fine-tuning open-source MLLMs on our dataset yielded noticeable performance gains. However, significant challenges persist, such as detecting subtle cues in comments and differences in visual and textual structures.We provide in-depth error analysis and outline future research directions. We hope our study can serve as a call for the research community and platform moderators to develop more precise defenses against this emerging threat.
AtomEval: Atomic Evaluation of Adversarial Claims in Fact Verification
Apr 09, 2026Adversarial claim rewriting is widely used to test fact-checking systems, but standard metrics fail to capture truth-conditional consistency and often label semantically corrupted rewrites as successful. We introduce AtomEval, a validity-aware evaluation framework that decomposes claims into subject-relation-object-modifier (SROM) atoms and scores adversarial rewrites with Atomic Validity Scoring (AVS), enabling detection of factual corruption beyond surface similarity. Experiments on the FEVER dataset across representative attack strategies and LLM generators show that AtomEval provides more reliable evaluation signals in our experiments. Using AtomEval, we further analyze LLM-based adversarial generators and observe that stronger models do not necessarily produce more effective adversarial claims under validity-aware evaluation, highlighting previously overlooked limitations in current adversarial evaluation practices.
Chain-of-Authorization: Internalizing Authorization into Large Language Models via Reasoning Trajectories
Mar 24, 2026Large Language Models (LLMs) have become core cognitive components in modern artificial intelligence (AI) systems, combining internal knowledge with external context to perform complex tasks. However, LLMs typically treat all accessible data indiscriminately, lacking inherent awareness of knowledge ownership and access boundaries. This deficiency heightens risks of sensitive data leakage and adversarial manipulation, potentially enabling unauthorized system access and severe security crises. Existing protection strategies rely on rigid, uniform defense that prevent dynamic authorization. Structural isolation methods faces scalability bottlenecks, while prompt guidance methods struggle with fine-grained permissions distinctions. Here, we propose the Chain-of-Authorization (CoA) framework, a secure training and reasoning paradigm that internalizes authorization logic into LLMs' core capabilities. Unlike passive external defneses, CoA restructures the model's information flow: it embeds permission context at input and requires generating explicit authorization reasoning trajectory that includes resource review, identity resolution, and decision-making stages before final response. Through supervised fine-tuning on data covering various authorization status, CoA integrates policy execution with task responses, making authorization a causal prerequisite for substantive responses. Extensive evaluations show that CoA not only maintains comparable utility in authorized scenarios but also overcomes the cognitive confusion when permissions mismatches. It exhibits high rejection rates against various unauthorized and adversarial access. This mechanism leverages LLMs' reasoning capability to perform dynamic authorization, using natural language understanding as a proactive security mechanism for deploying reliable LLMs in modern AI systems.
GRPO Privacy Is at Risk: A Membership Inference Attack Against Reinforcement Learning With Verifiable Rewards
Nov 18, 2025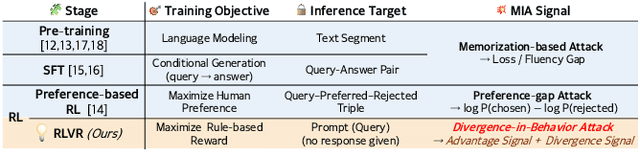
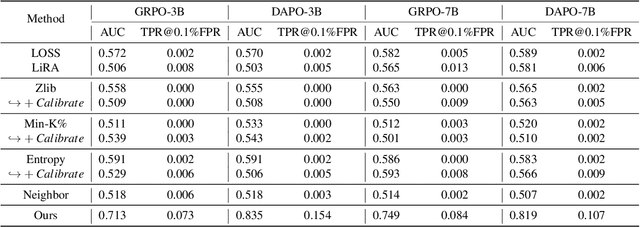
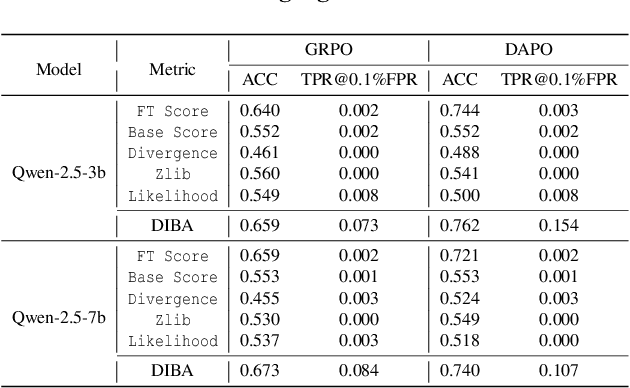
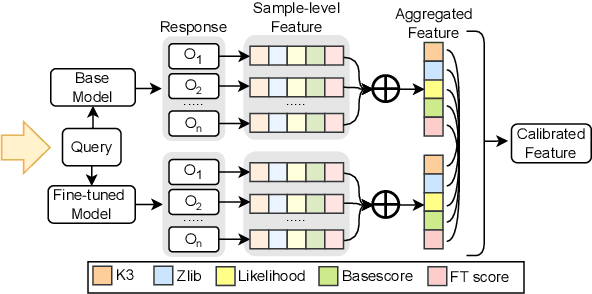
Membership inference attacks (MIAs) on large language models (LLMs) pose significant privacy risks across various stages of model training. Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have brought a profound paradigm shift in LLM training, particularly for complex reasoning tasks. However, the on-policy nature of RLVR introduces a unique privacy leakage pattern: since training relies on self-generated responses without fixed ground-truth outputs, membership inference must now determine whether a given prompt (independent of any specific response) is used during fine-tuning. This creates a threat where leakage arises not from answer memorization. To audit this novel privacy risk, we propose Divergence-in-Behavior Attack (DIBA), the first membership inference framework specifically designed for RLVR. DIBA shifts the focus from memorization to behavioral change, leveraging measurable shifts in model behavior across two axes: advantage-side improvement (e.g., correctness gain) and logit-side divergence (e.g., policy drift). Through comprehensive evaluations, we demonstrate that DIBA significantly outperforms existing baselines, achieving around 0.8 AUC and an order-of-magnitude higher TPR@0.1%FPR. We validate DIBA's superiority across multiple settings--including in-distribution, cross-dataset, cross-algorithm, black-box scenarios, and extensions to vision-language models. Furthermore, our attack remains robust under moderate defensive measures. To the best of our knowledge, this is the first work to systematically analyze privacy vulnerabilities in RLVR, revealing that even in the absence of explicit supervision, training data exposure can be reliably inferred through behavioral traces.
ZPD-SCA: Unveiling the Blind Spots of LLMs in Assessing Students' Cognitive Abilities
Aug 20, 2025


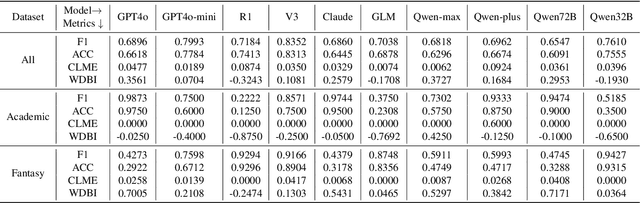
Large language models (LLMs) have demonstrated potential in educational applications, yet their capacity to accurately assess the cognitive alignment of reading materials with students' developmental stages remains insufficiently explored. This gap is particularly critical given the foundational educational principle of the Zone of Proximal Development (ZPD), which emphasizes the need to match learning resources with Students' Cognitive Abilities (SCA). Despite the importance of this alignment, there is a notable absence of comprehensive studies investigating LLMs' ability to evaluate reading comprehension difficulty across different student age groups, especially in the context of Chinese language education. To fill this gap, we introduce ZPD-SCA, a novel benchmark specifically designed to assess stage-level Chinese reading comprehension difficulty. The benchmark is annotated by 60 Special Grade teachers, a group that represents the top 0.15% of all in-service teachers nationwide. Experimental results reveal that LLMs perform poorly in zero-shot learning scenarios, with Qwen-max and GLM even falling below the probability of random guessing. When provided with in-context examples, LLMs performance improves substantially, with some models achieving nearly double the accuracy of their zero-shot baselines. These results reveal that LLMs possess emerging abilities to assess reading difficulty, while also exposing limitations in their current training for educationally aligned judgment. Notably, even the best-performing models display systematic directional biases, suggesting difficulties in accurately aligning material difficulty with SCA. Furthermore, significant variations in model performance across different genres underscore the complexity of task. We envision that ZPD-SCA can provide a foundation for evaluating and improving LLMs in cognitively aligned educational applications.
Evaluation Hallucination in Multi-Round Incomplete Information Lateral-Driven Reasoning Tasks
May 28, 2025


Multi-round incomplete information tasks are crucial for evaluating the lateral thinking capabilities of large language models (LLMs). Currently, research primarily relies on multiple benchmarks and automated evaluation metrics to assess these abilities. However, our study reveals novel insights into the limitations of existing methods, as they often yield misleading results that fail to uncover key issues, such as shortcut-taking behaviors, rigid patterns, and premature task termination. These issues obscure the true reasoning capabilities of LLMs and undermine the reliability of evaluations. To address these limitations, we propose a refined set of evaluation standards, including inspection of reasoning paths, diversified assessment metrics, and comparative analyses with human performance.
JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models
May 23, 2025


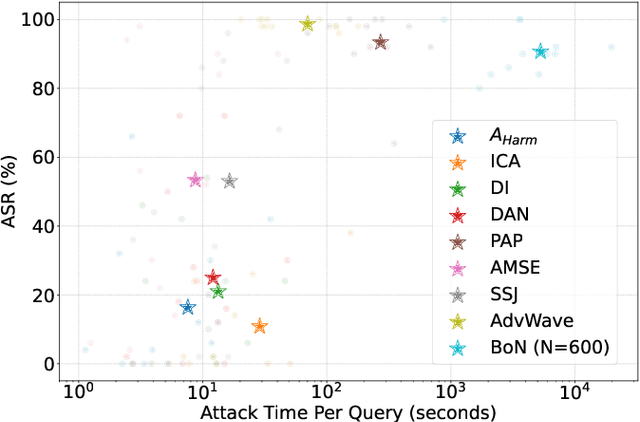
Audio Language Models (ALMs) have made significant progress recently. These models integrate the audio modality directly into the model, rather than converting speech into text and inputting text to Large Language Models (LLMs). While jailbreak attacks on LLMs have been extensively studied, the security of ALMs with audio modalities remains largely unexplored. Currently, there is a lack of an adversarial audio dataset and a unified framework specifically designed to evaluate and compare attacks and ALMs. In this paper, we present JALMBench, the \textit{first} comprehensive benchmark to assess the safety of ALMs against jailbreak attacks. JALMBench includes a dataset containing 2,200 text samples and 51,381 audio samples with over 268 hours. It supports 12 mainstream ALMs, 4 text-transferred and 4 audio-originated attack methods, and 5 defense methods. Using JALMBench, we provide an in-depth analysis of attack efficiency, topic sensitivity, voice diversity, and attack representations. Additionally, we explore mitigation strategies for the attacks at both the prompt level and the response level.
Humanizing LLMs: A Survey of Psychological Measurements with Tools, Datasets, and Human-Agent Applications
Apr 30, 2025



As large language models (LLMs) are increasingly used in human-centered tasks, assessing their psychological traits is crucial for understanding their social impact and ensuring trustworthy AI alignment. While existing reviews have covered some aspects of related research, several important areas have not been systematically discussed, including detailed discussions of diverse psychological tests, LLM-specific psychological datasets, and the applications of LLMs with psychological traits. To address this gap, we systematically review six key dimensions of applying psychological theories to LLMs: (1) assessment tools; (2) LLM-specific datasets; (3) evaluation metrics (consistency and stability); (4) empirical findings; (5) personality simulation methods; and (6) LLM-based behavior simulation. Our analysis highlights both the strengths and limitations of current methods. While some LLMs exhibit reproducible personality patterns under specific prompting schemes, significant variability remains across tasks and settings. Recognizing methodological challenges such as mismatches between psychological tools and LLMs' capabilities, as well as inconsistencies in evaluation practices, this study aims to propose future directions for developing more interpretable, robust, and generalizable psychological assessment frameworks for LLMs.