 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming OpenClaw: Security Analysis and Mitigation of Autonomous LLM Agent Threats
Mar 12, 2026Autonomous Large Language Model (LLM) agents, exemplified by OpenClaw, demonstrate remarkable capabilities in executing complex, long-horizon tasks. However, their tightly coupled instant-messaging interaction paradigm and high-privilege execution capabilities substantially expand the system attack surface. In this paper, we present a comprehensive security threat analysis of OpenClaw. To structure our analysis, we introduce a five-layer lifecycle-oriented security framework that captures key stages of agent operation, i.e., initialization, input, inference, decision, and execution, and systematically examine compound threats across the agent's operational lifecycle, including indirect prompt injection, skill supply chain contamination, memory poisoning, and intent drift. Through detailed case studies on OpenClaw, we demonstrate the prevalence and severity of these threats and analyze the limitations of existing defenses. Our findings reveal critical weaknesses in current point-based defense mechanisms when addressing cross-temporal and multi-stage systemic risks, highlighting the need for holistic security architectures for autonomous LLM agents. Within this framework, we further examine representative defense strategies at each lifecycle stage, including plugin vetting frameworks, context-aware instruction filtering, memory integrity validation protocols, intent verification mechanisms, and capability enforcement architectures.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
Behind the Tip of Efficiency: Uncovering the Submerged Threats of Jailbreak Attacks in Small Language Models
Feb 28, 2025Small language models (SLMs) have become increasingly prominent in the deployment on edge devices due to their high efficiency and low computational cost. While researchers continue to advance the capabilities of SLMs through innovative training strategies and model compression techniques, the security risks of SLMs have received considerably less attention compared to large language models (LLMs).To fill this gap, we provide a comprehensive empirical study to evaluate the security performance of 13 state-of-the-art SLMs under various jailbreak attacks. Our experiments demonstrate that most SLMs are quite susceptible to existing jailbreak attacks, while some of them are even vulnerable to direct harmful prompts.To address the safety concerns, we evaluate several representative defense methods and demonstrate their effectiveness in enhancing the security of SLMs. We further analyze the potential security degradation caused by different SLM techniques including architecture compression, quantization, knowledge distillation, and so on. We expect that our research can highlight the security challenges of SLMs and provide valuable insights to future work in developing more robust and secure SLMs.
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Jul 05, 2024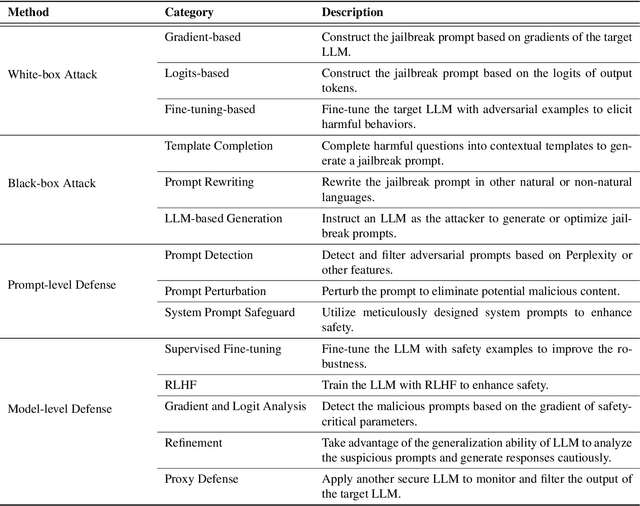
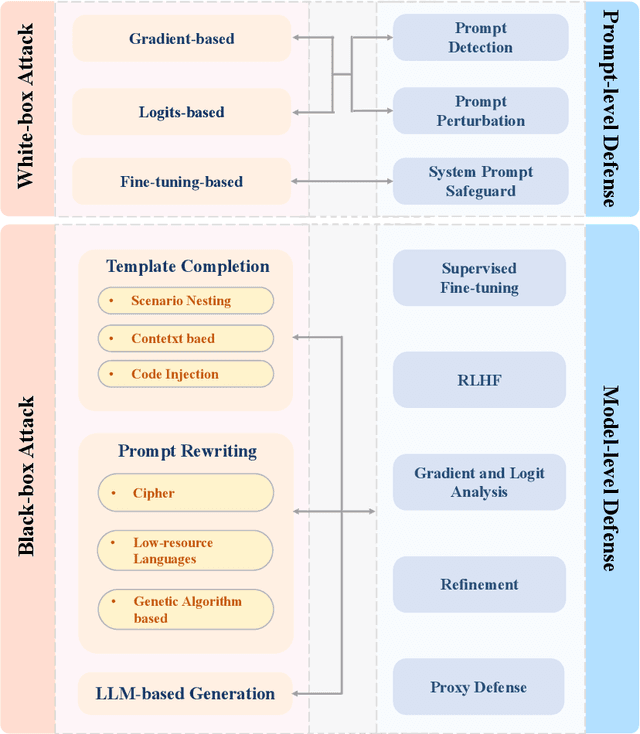
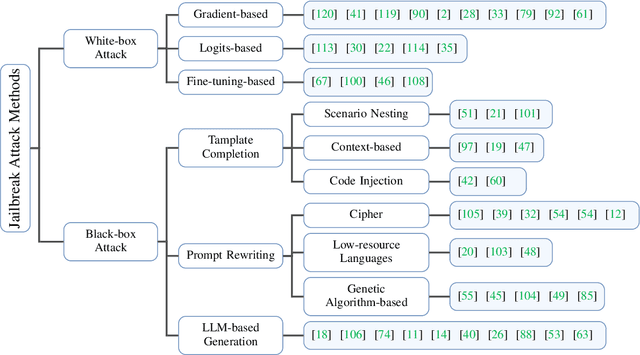
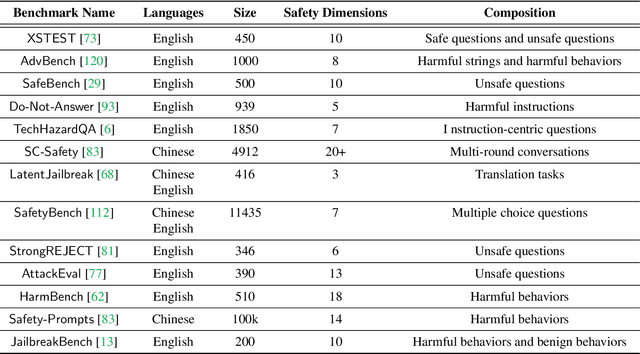
Large Language Models (LLMs) have performed exceptionally in various text-generative tasks, including question answering, translation, code completion, etc. However, the over-assistance of LLMs has raised the challenge of "jailbreaking", which induces the model to generate malicious responses against the usage policy and society by designing adversarial prompts. With the emergence of jailbreak attack methods exploiting different vulnerabilities in LLMs, the corresponding safety alignment measures are also evolving. In this paper, we propose a comprehensive and detailed taxonomy of jailbreak attack and defense methods. For instance, the attack methods are divided into black-box and white-box attacks based on the transparency of the target model. Meanwhile, we classify defense methods into prompt-level and model-level defenses. Additionally, we further subdivide these attack and defense methods into distinct sub-classes and present a coherent diagram illustrating their relationships. We also conduct an investigation into the current evaluation methods and compare them from different perspectives. Our findings aim to inspire future research and practical implementations in safeguarding LLMs against adversarial attacks. Above all, although jailbreak remains a significant concern within the community, we believe that our work enhances the understanding of this domain and provides a foundation for developing more secure LLMs.
Optimal Mixture Weights for Off-Policy Evaluation with Multiple Behavior Policies
Nov 29, 2020


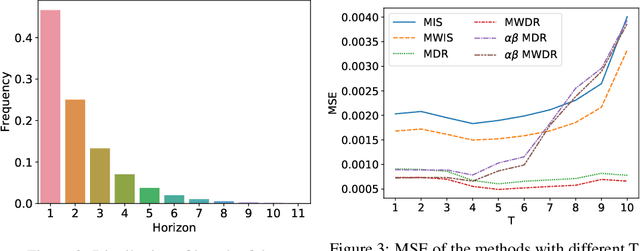
Off-policy evaluation is a key component of reinforcement learning which evaluates a target policy with offline data collected from behavior policies. It is a crucial step towards safe reinforcement learning and has been used in advertisement, recommender systems and many other applications. In these applications, sometimes the offline data is collected from multiple behavior policies. Previous works regard data from different behavior policies equally. Nevertheless, some behavior policies are better at producing good estimators while others are not. This paper starts with discussing how to correctly mix estimators produced by different behavior policies. We propose three ways to reduce the variance of the mixture estimator when all sub-estimators are unbiased or asymptotically unbiased. Furthermore, experiments on simulated recommender systems show that our methods are effective in reducing the Mean-Square Error of estimation.