 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization Ability of Machine-Generated Text Detectors
Dec 23, 2024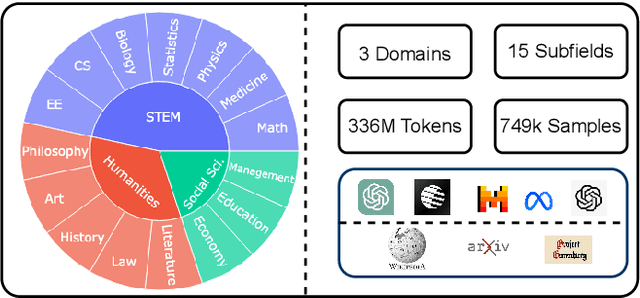
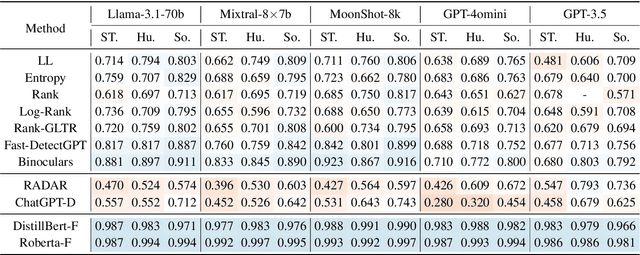

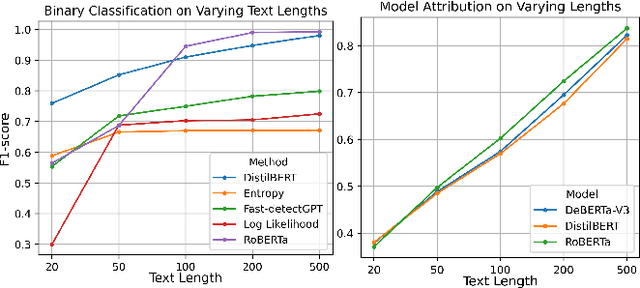
The rise of large language models (LLMs) has raised concerns about machine-generated text (MGT), including ethical and practical issues like plagiarism and misinformation. Building a robust and highly generalizable MGT detection system has become increasingly important. This work investigates the generalization capabilities of MGT detectors in three aspects: First, we construct MGTAcademic, a large-scale dataset focused on academic writing, featuring human-written texts (HWTs) and MGTs across STEM, Humanities, and Social Sciences, paired with an extensible code framework for efficient benchmarking. Second, we investigate the transferability of detectors across domains and LLMs, leveraging fine-grained datasets to reveal insights into domain transferring and implementing few-shot techniques to improve the performance by roughly 13.2%. Third, we introduce a novel attribution task where models must adapt to new classes over time without (or with very limited) access to prior training data and benchmark detectors. We implement several adapting techniques to improve the performance by roughly 10% and highlight the inherent complexity of the task. Our findings provide insights into the generalization ability of MGT detectors across diverse scenarios and lay the foundation for building robust, adaptive detection systems.
A Critical Perceptual Pre-trained Model for Complex Trajectory Recovery
Nov 05, 2023



The trajectory on the road traffic is commonly collected at a low sampling rate, and trajectory recovery aims to recover a complete and continuous trajectory from the sparse and discrete inputs. Recently, sequential language models have been innovatively adopted for trajectory recovery in a pre-trained manner: it learns road segment representation vectors, which will be used in the downstream tasks. However, existing methods are incapable of handling complex trajectories: when the trajectory crosses remote road segments or makes several turns, which we call critical nodes, the quality of learned representations deteriorates, and the recovered trajectories skip the critical nodes. This work is dedicated to offering a more robust trajectory recovery for complex trajectories. Firstly, we define the trajectory complexity based on the detour score and entropy score and construct the complexity-aware semantic graphs correspondingly. Then, we propose a Multi-view Graph and Complexity Aware Transformer (MGCAT) model to encode these semantics in trajectory pre-training from two aspects: 1) adaptively aggregate the multi-view graph features considering trajectory pattern, and 2) higher attention to critical nodes in a complex trajectory. Such that, our MGCAT is perceptual when handling the critical scenario of complex trajectories. Extensive experiments are conducted on large-scale datasets. The results prove that our method learns better representations for trajectory recovery, with 5.22% higher F1-score overall and 8.16% higher F1-score for complex trajectories particularly. The code is available at https://github.com/bonaldli/ComplexTraj.
Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Dec 22, 2021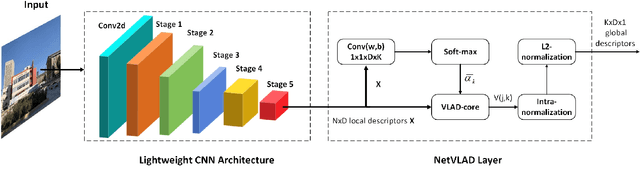
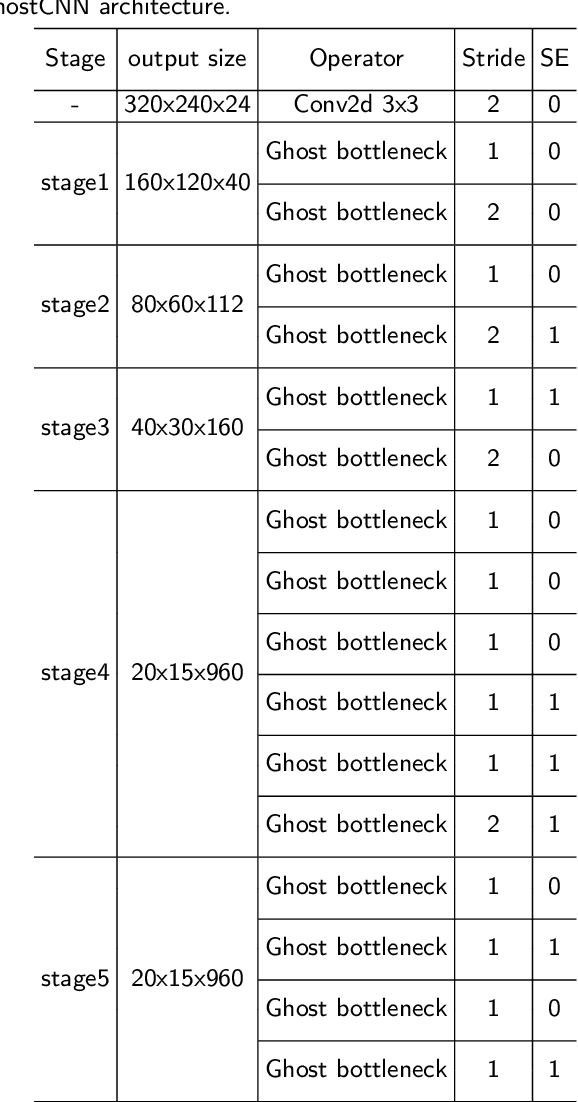
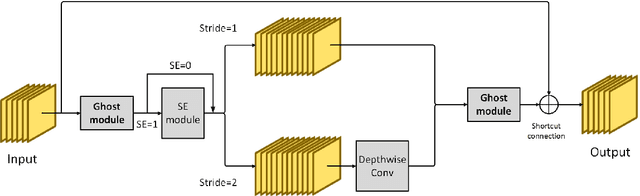
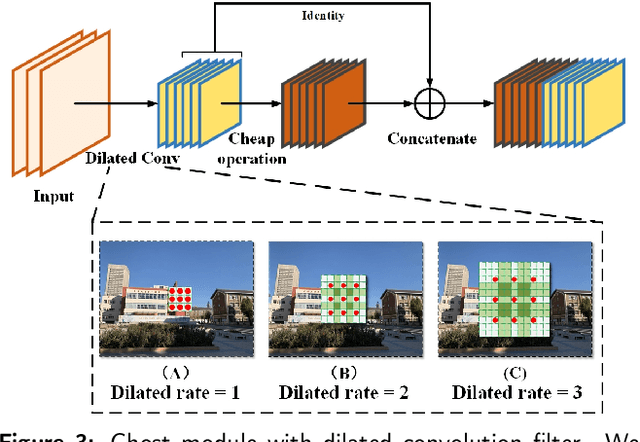
Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.