 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROI-based Deep Image Compression with Implicit Bit Allocation
Nov 12, 2025Region of Interest (ROI)-based image compression has rapidly developed due to its ability to maintain high fidelity in important regions while reducing data redundancy. However, existing compression methods primarily apply masks to suppress background information before quantization. This explicit bit allocation strategy, which uses hard gating, significantly impacts the statistical distribution of the entropy model, thereby limiting the coding performance of the compression model. In response, this work proposes an efficient ROI-based deep image compression model with implicit bit allocation. To better utilize ROI masks for implicit bit allocation, this paper proposes a novel Mask-Guided Feature Enhancement (MGFE) module, comprising a Region-Adaptive Attention (RAA) block and a Frequency-Spatial Collaborative Attention (FSCA) block. This module allows for flexible bit allocation across different regions while enhancing global and local features through frequencyspatial domain collaboration. Additionally, we use dual decoders to separately reconstruct foreground and background images, enabling the coding network to optimally balance foreground enhancement and background quality preservation in a datadriven manner. To the best of our knowledge, this is the first work to utilize implicit bit allocation for high-quality regionadaptive coding. Experiments on the COCO2017 dataset show that our implicit-based image compression method significantly outperforms explicit bit allocation approaches in rate-distortion performance, achieving optimal results while maintaining satisfactory visual quality in the reconstructed background regions.
Enhancing Quality of Pose-varied Face Restoration with Local Weak Feature Sensing and GAN Prior
May 28, 2022
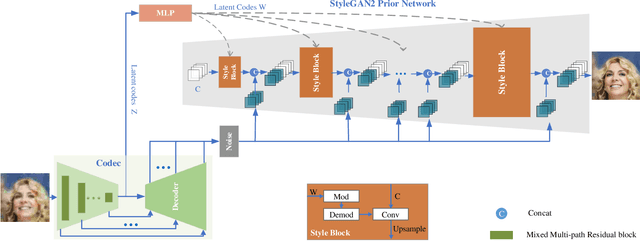
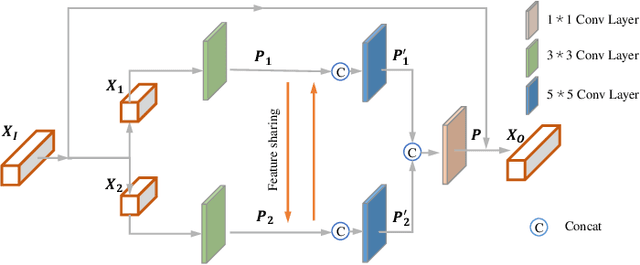

Facial semantic guidance (facial landmarks, facial parsing maps, facial heatmaps, etc.) and facial generative adversarial networks (GAN) prior have been widely used in blind face restoration (BFR) in recent years. Although existing BFR methods have achieved good performance in ordinary cases, these solutions have limited resilience when applied to face images with serious degradation and pose-varied (look up, look down, laugh, etc.) in real-world scenarios. In this work, we propose a well-designed blind face restoration network with generative facial prior. The proposed network is mainly comprised of an asymmetric codec and StyleGAN2 prior network. In the asymmetric codec, we adopt a mixed multi-path residual block (MMRB) to gradually extract weak texture features of input images, which can improve the texture integrity and authenticity of our networks. Furthermore, the MMRB block can also be plug-and-play in any other network. Besides, a novel self-supervised training strategy is specially designed for face restoration tasks to fit the distribution closer to the target and maintain training stability. Extensive experiments over synthetic and real-world datasets demonstrate that our model achieves superior performance to the prior art for face restoration and face super-resolution tasks and can tackle seriously degraded face images in diverse poses and expressions.
Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Dec 22, 2021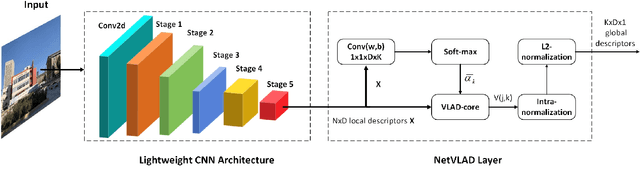
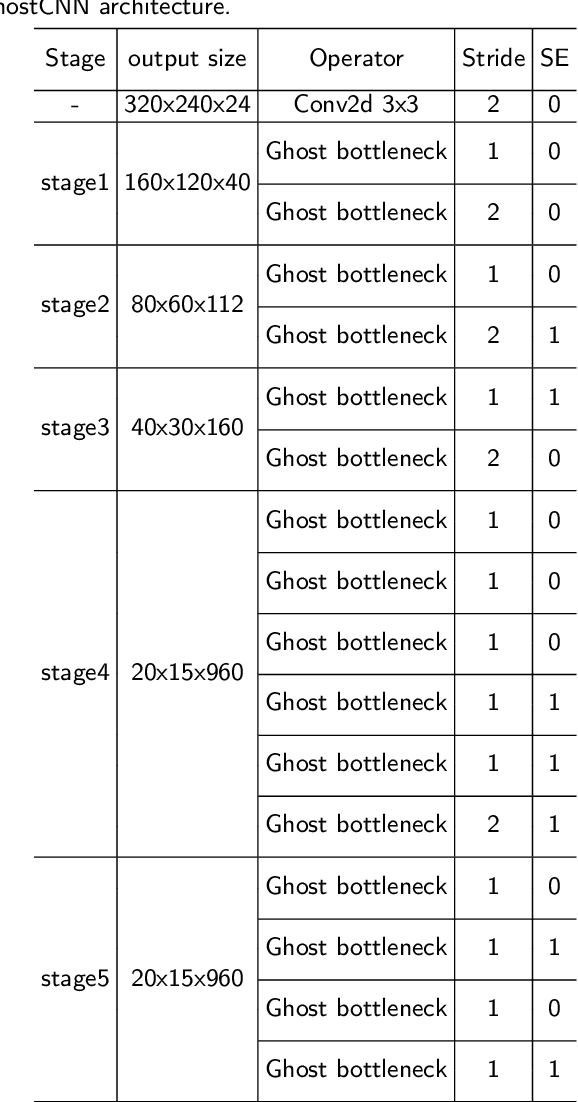
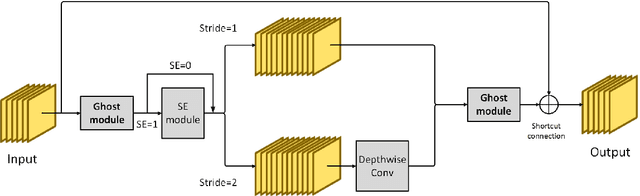
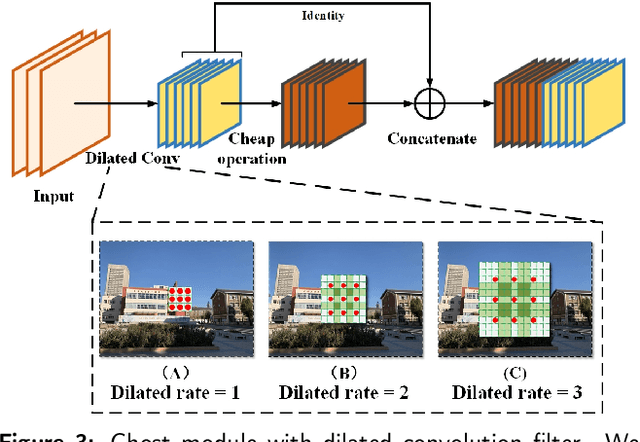
Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.