 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Paper and Code
Dec 22, 2021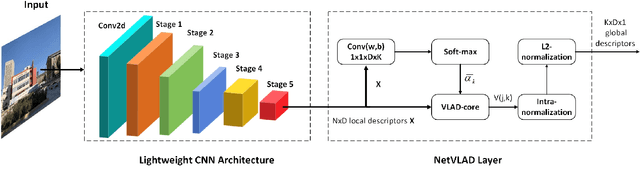
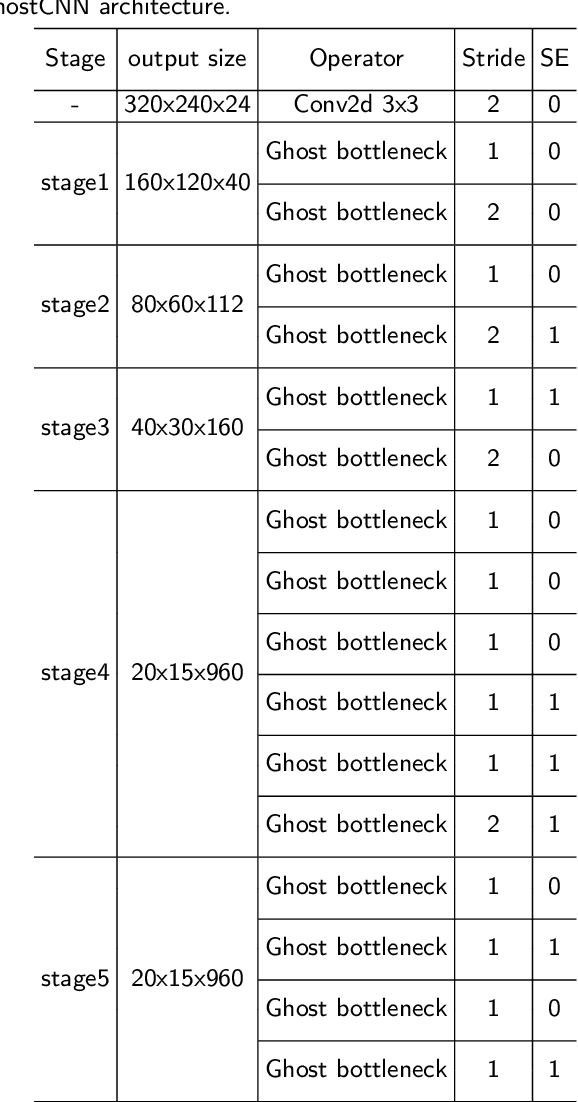
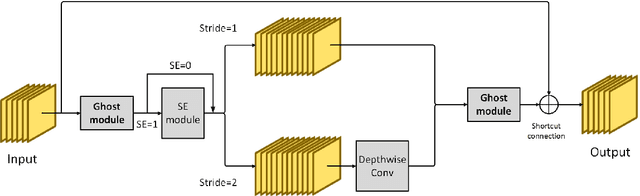
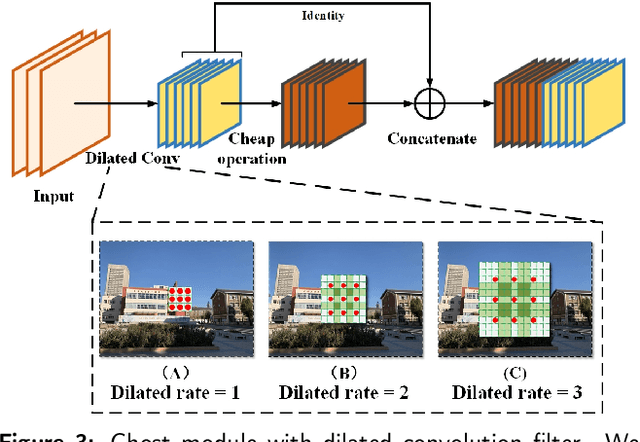
Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.