 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRPO Privacy Is at Risk: A Membership Inference Attack Against Reinforcement Learning With Verifiable Rewards
Nov 18, 2025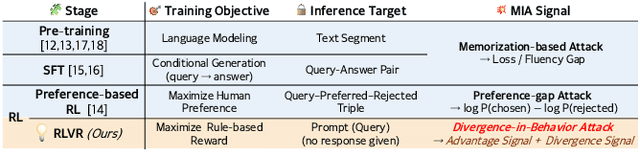
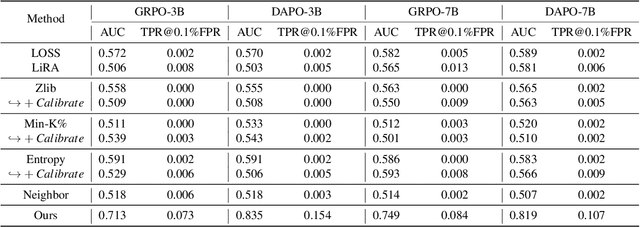
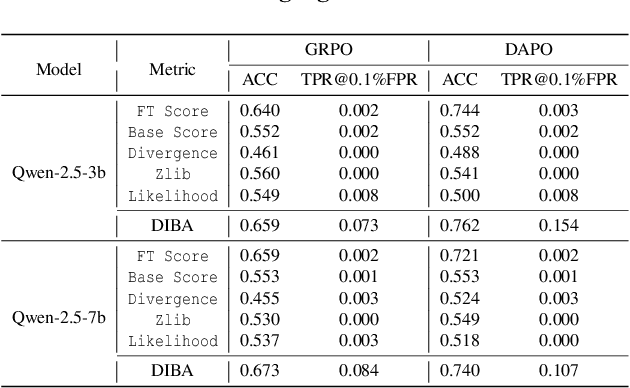
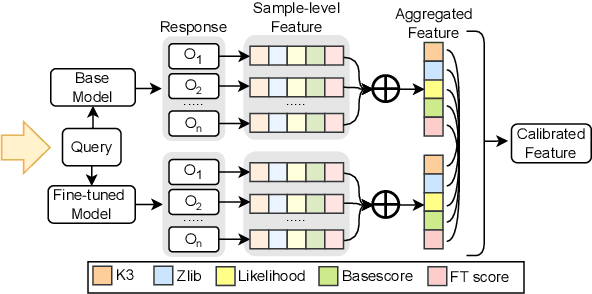
Membership inference attacks (MIAs) on large language models (LLMs) pose significant privacy risks across various stages of model training. Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have brought a profound paradigm shift in LLM training, particularly for complex reasoning tasks. However, the on-policy nature of RLVR introduces a unique privacy leakage pattern: since training relies on self-generated responses without fixed ground-truth outputs, membership inference must now determine whether a given prompt (independent of any specific response) is used during fine-tuning. This creates a threat where leakage arises not from answer memorization. To audit this novel privacy risk, we propose Divergence-in-Behavior Attack (DIBA), the first membership inference framework specifically designed for RLVR. DIBA shifts the focus from memorization to behavioral change, leveraging measurable shifts in model behavior across two axes: advantage-side improvement (e.g., correctness gain) and logit-side divergence (e.g., policy drift). Through comprehensive evaluations, we demonstrate that DIBA significantly outperforms existing baselines, achieving around 0.8 AUC and an order-of-magnitude higher TPR@0.1%FPR. We validate DIBA's superiority across multiple settings--including in-distribution, cross-dataset, cross-algorithm, black-box scenarios, and extensions to vision-language models. Furthermore, our attack remains robust under moderate defensive measures. To the best of our knowledge, this is the first work to systematically analyze privacy vulnerabilities in RLVR, revealing that even in the absence of explicit supervision, training data exposure can be reliably inferred through behavioral traces.
SoK: Benchmarking Poisoning Attacks and Defenses in Federated Learning
Feb 06, 2025



Federated learning (FL) enables collaborative model training while preserving data privacy, but its decentralized nature exposes it to client-side data poisoning attacks (DPAs) and model poisoning attacks (MPAs) that degrade global model performance. While numerous proposed defenses claim substantial effectiveness, their evaluation is typically done in isolation with limited attack strategies, raising concerns about their validity. Additionally, existing studies overlook the mutual effectiveness of defenses against both DPAs and MPAs, causing fragmentation in this field. This paper aims to provide a unified benchmark and analysis of defenses against DPAs and MPAs, clarifying the distinction between these two similar but slightly distinct domains. We present a systematic taxonomy of poisoning attacks and defense strategies, outlining their design, strengths, and limitations. Then, a unified comparative evaluation across FL algorithms and data heterogeneity is conducted to validate their individual and mutual effectiveness and derive key insights for design principles and future research. Along with the analysis, we frame our work to a unified benchmark, FLPoison, with high modularity and scalability to evaluate 15 representative poisoning attacks and 17 defense strategies, facilitating future research in this domain. Code is available at https://github.com/vio1etus/FLPoison.
Qibo: A Large Language Model for Traditional Chinese Medicine
Mar 24, 2024



In the field of Artificial Intelligence, Large Language Models (LLMs) have demonstrated significant advances in user intent understanding and response in a number of specialized domains, including medicine, law, and finance. However, in the unique domain of traditional Chinese medicine (TCM), the performance enhancement of LLMs is challenged by the essential differences between its theories and modern medicine, as well as the lack of specialized corpus resources. In this paper, we aim to construct and organize a professional corpus in the field of TCM, to endow the large model with professional knowledge that is characteristic of TCM theory, and to successfully develop the Qibo model based on LLaMA, which is the first LLM in the field of TCM to undergo a complete training process from pre-training to Supervised Fine-Tuning (SFT). Furthermore, we develop the Qibo-benchmark, a specialized tool for evaluating the performance of LLMs, which is a specialized tool for evaluating the performance of LLMs in the TCM domain. This tool will provide an important basis for quantifying and comparing the understanding and application capabilities of different models in the field of traditional Chinese medicine, and provide guidance for future research directions and practical applications of intelligent assistants for traditional Chinese medicine. Finally, we conducted sufficient experiments to prove that Qibo has good performance in the field of traditional Chinese medicine.