 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinkRec: Mitigating Semantic State Sink in Long Sequence Recommendation with Memory-Conditioned Gated Delta Networks
Jun 03, 2026Linear attention provides an efficient backbone for long-sequence recommendation by avoiding the quadratic cost of standard Transformers, but its compressed recurrent state can be dominated by repetitive behavior patterns. We identify this phenomenon as semantic state sink, where recurring semantics over-occupy the recurrent state and bias subsequent readouts. To mitigate semantic state sink, we propose SinkRec, a hybrid memory-transition looped architecture that decouples collaborative behavioral pattern storage from dynamic transition modeling. SinkRec externalizes recurring local patterns into a learnable conditional memory through residual vector quantization, reinjects the retrieved codes, and exposes memory key-value pairs to the attention block. It further introduces Temporal-Aware State-Relation Differential Gated DeltaNet (TDGD), which uses memory to purify recurrent writing and reading by suppressing memory-covered updates and removing memory-aligned readout responses. This design turns recurring semantics from state-competing signals into memory-retrievable patterns, allowing the recurrent state to focus on dynamic transitions and alleviating semantic state sink with linear-time efficiency. Experiments on public and industrial datasets demonstrate the effectiveness and efficiency of SinkRec.
Modality-Guided Mixture of Graph Experts with Entropy-Triggered Routing for Multimodal Recommendation
Feb 26, 2026Multimodal recommendation enhances ranking by integrating user-item interactions with item content, which is particularly effective under sparse feedback and long-tail distributions. However, multimodal signals are inherently heterogeneous and can conflict in specific contexts, making effective fusion both crucial and challenging. Existing approaches often rely on shared fusion pathways, leading to entangled representations and modality imbalance. To address these issues, we propose MAGNET, a Modality-Guided Mixture of Adaptive Graph Experts Network with Progressive Entropy-Triggered Routing for Multimodal Recommendation, designed to enhance controllability, stability, and interpretability in multimodal fusion. MAGNET couples interaction-conditioned expert routing with structure-aware graph augmentation, so that both what to fuse and how to fuse are explicitly controlled and interpretable. At the representation level, a dual-view graph learning module augments the interaction graph with content-induced edges, improving coverage for sparse and long-tail items while preserving collaborative structure via parallel encoding and lightweight fusion. At the fusion level, MAGNET employs structured experts with explicit modality roles-dominant, balanced, and complementary-enabling a more interpretable and adaptive combination of behavioral, visual, and textual cues. To further stabilize sparse routing and prevent expert collapse, we introduce a two-stage entropy-weighting mechanism that monitors routing entropy. This mechanism automatically transitions training from an early coverage-oriented regime to a later specialization-oriented regime, progressively balancing expert utilization and routing confidence. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines.
Cross-Modal Attention Network with Dual Graph Learning in Multimodal Recommendation
Jan 16, 2026Multimedia recommendation systems leverage user-item interactions and multimodal information to capture user preferences, enabling more accurate and personalized recommendations. Despite notable advancements, existing approaches still face two critical limitations: first, shallow modality fusion often relies on simple concatenation, failing to exploit rich synergic intra- and inter-modal relationships; second, asymmetric feature treatment-where users are only characterized by interaction IDs while items benefit from rich multimodal content-hinders the learning of a shared semantic space. To address these issues, we propose a Cross-modal Recursive Attention Network with dual graph Embedding (CRANE). To tackle shallow fusion, we design a core Recursive Cross-Modal Attention (RCA) mechanism that iteratively refines modality features based on cross-correlations in a joint latent space, effectively capturing high-order intra- and inter-modal dependencies. For symmetric multimodal learning, we explicitly construct users' multimodal profiles by aggregating features of their interacted items. Furthermore, CRANE integrates a symmetric dual-graph framework-comprising a heterogeneous user-item interaction graph and a homogeneous item-item semantic graph-unified by a self-supervised contrastive learning objective to fuse behavioral and semantic signals. Despite these complex modeling capabilities, CRANE maintains high computational efficiency. Theoretical and empirical analyses confirm its scalability and high practical efficiency, achieving faster convergence on small datasets and superior performance ceilings on large-scale ones. Comprehensive experiments on four public real-world datasets validate an average 5% improvement in key metrics over state-of-the-art baselines.
A Deep-Learning-Based Neural Decoding Framework for Emotional Brain-Computer Interfaces
Mar 08, 2023Reading emotions precisely from segments of neural activity is crucial for the development of emotional brain-computer interfaces. Among all neural decoding algorithms, deep learning (DL) holds the potential to become the most promising one, yet progress has been limited in recent years. One possible reason is that the efficacy of DL strongly relies on training samples, yet the neural data used for training are often from non-human primates and mixed with plenty of noise, which in turn mislead the training of DL models. Given it is difficult to accurately determine animals' emotions from humans' perspective, we assume the dominant noise in neural data representing different emotions is the labeling error. Here, we report the development and application of a neural decoding framework called Emo-Net that consists of a confidence learning (CL) component and a DL component. The framework is fully data-driven and is capable of decoding emotions from multiple datasets obtained from behaving monkeys. In addition to improving the decoding ability, Emo-Net significantly improves the performance of the base DL models, making emotion recognition in animal models possible. In summary, this framework may inspire novel understandings of the neural basis of emotion and drive the realization of close-loop emotional brain-computer interfaces.
Accurate and efficient video de-fencing using convolutional neural networks and temporal information
Jun 28, 2018
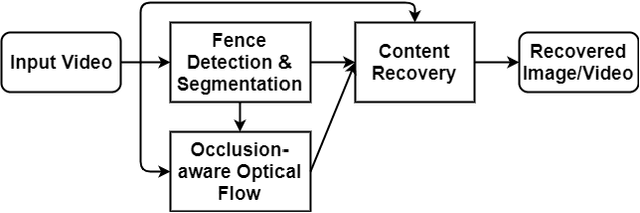
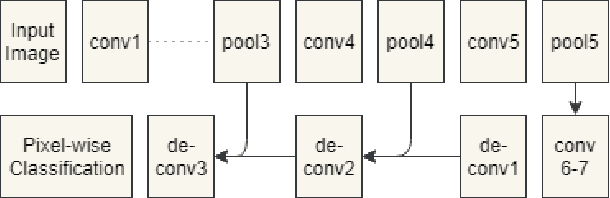

De-fencing is to eliminate the captured fence on an image or a video, providing a clear view of the scene. It has been applied for many purposes including assisting photographers and improving the performance of computer vision algorithms such as object detection and recognition. However, the state-of-the-art de-fencing methods have limited performance caused by the difficulty of fence segmentation and also suffer from the motion of the camera or objects. To overcome these problems, we propose a novel method consisting of segmentation using convolutional neural networks and a fast/robust recovery algorithm. The segmentation algorithm using convolutional neural network achieves significant improvement in the accuracy of fence segmentation. The recovery algorithm using optical flow produces plausible de-fenced images and videos. The proposed method is experimented on both our diverse and complex dataset and publicly available datasets. The experimental results demonstrate that the proposed method achieves the state-of-the-art performance for both segmentation and content recovery.