 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query
Dec 15, 2022



We propose a sparse end-to-end multi-person pose regression framework, termed QueryPose, which can directly predict multi-person keypoint sequences from the input image. The existing end-to-end methods rely on dense representations to preserve the spatial detail and structure for precise keypoint localization. However, the dense paradigm introduces complex and redundant post-processes during inference. In our framework, each human instance is encoded by several learnable spatial-aware part-level queries associated with an instance-level query. First, we propose the Spatial Part Embedding Generation Module (SPEGM) that considers the local spatial attention mechanism to generate several spatial-sensitive part embeddings, which contain spatial details and structural information for enhancing the part-level queries. Second, we introduce the Selective Iteration Module (SIM) to adaptively update the sparse part-level queries via the generated spatial-sensitive part embeddings stage-by-stage. Based on the two proposed modules, the part-level queries are able to fully encode the spatial details and structural information for precise keypoint regression. With the bipartite matching, QueryPose avoids the hand-designed post-processes and surpasses the existing dense end-to-end methods with 73.6 AP on MS COCO mini-val set and 72.7 AP on CrowdPose test set. Code is available at https://github.com/buptxyb666/QueryPose.
AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression
Oct 08, 2022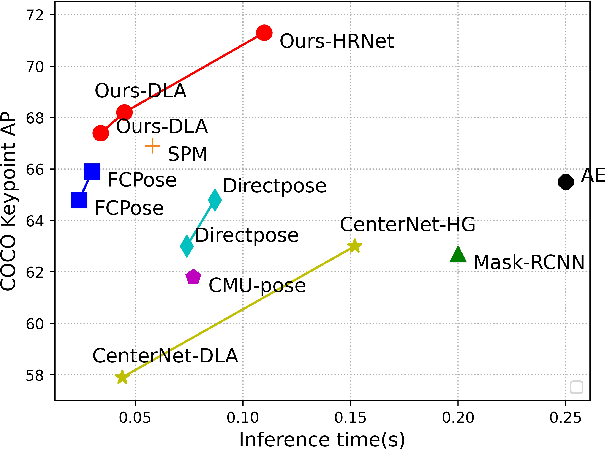

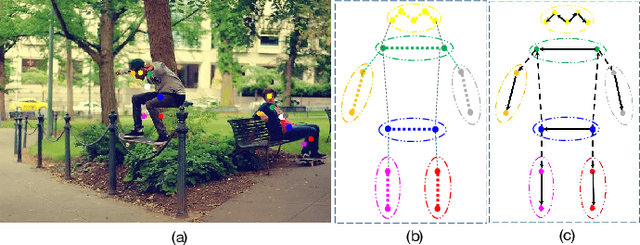
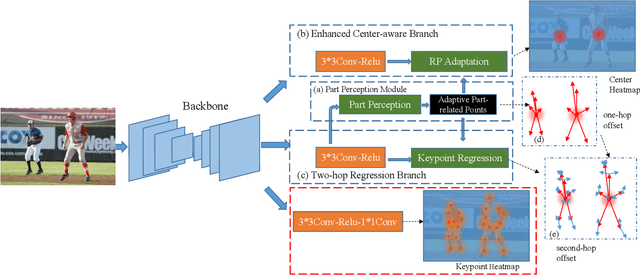
Multi-person pose estimation generally follows top-down and bottom-up paradigms. Both of them use an extra stage ($\boldsymbol{e.g.,}$ human detection in top-down paradigm or grouping process in bottom-up paradigm) to build the relationship between the human instance and corresponding keypoints, thus leading to the high computation cost and redundant two-stage pipeline. To address the above issue, we propose to represent the human parts as adaptive points and introduce a fine-grained body representation method. The novel body representation is able to sufficiently encode the diverse pose information and effectively model the relationship between the human instance and corresponding keypoints in a single-forward pass. With the proposed body representation, we further deliver a compact single-stage multi-person pose regression network, termed as AdaptivePose. During inference, our proposed network only needs a single-step decode operation to form the multi-person pose without complex post-processes and refinements. We employ AdaptivePose for both 2D/3D multi-person pose estimation tasks to verify the effectiveness of AdaptivePose. Without any bells and whistles, we achieve the most competitive performance on MS COCO and CrowdPose in terms of accuracy and speed. Furthermore, the outstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates the effectiveness and generalizability on 3D scenes. Code is available at https://github.com/buptxyb666/AdaptivePose.
Learning Quality-aware Representation for Multi-person Pose Regression
Jan 04, 2022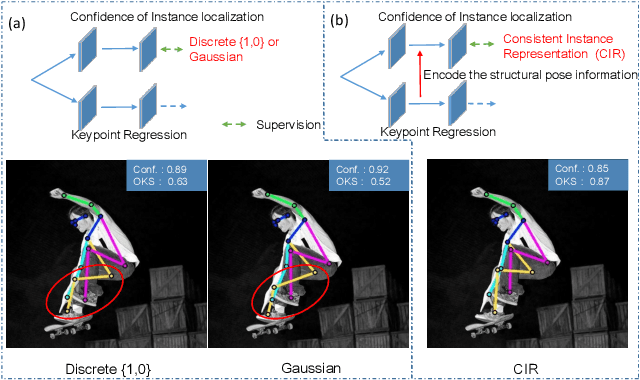

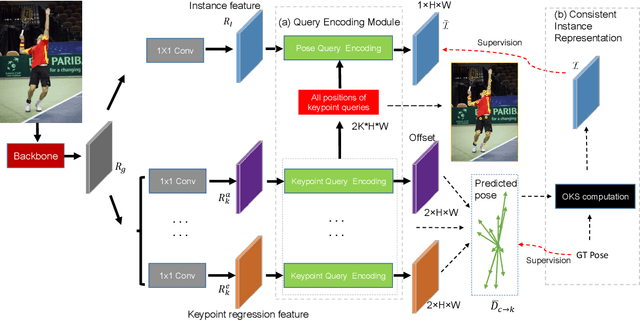
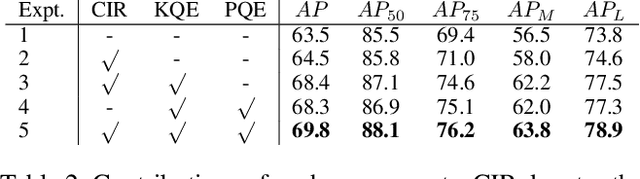
Off-the-shelf single-stage multi-person pose regression methods generally leverage the instance score (i.e., confidence of the instance localization) to indicate the pose quality for selecting the pose candidates. We consider that there are two gaps involved in existing paradigm:~1) The instance score is not well interrelated with the pose regression quality.~2) The instance feature representation, which is used for predicting the instance score, does not explicitly encode the structural pose information to predict the reasonable score that represents pose regression quality. To address the aforementioned issues, we propose to learn the pose regression quality-aware representation. Concretely, for the first gap, instead of using the previous instance confidence label (e.g., discrete {1,0} or Gaussian representation) to denote the position and confidence for person instance, we firstly introduce the Consistent Instance Representation (CIR) that unifies the pose regression quality score of instance and the confidence of background into a pixel-wise score map to calibrates the inconsistency between instance score and pose regression quality. To fill the second gap, we further present the Query Encoding Module (QEM) including the Keypoint Query Encoding (KQE) to encode the positional and semantic information for each keypoint and the Pose Query Encoding (PQE) which explicitly encodes the predicted structural pose information to better fit the Consistent Instance Representation (CIR). By using the proposed components, we significantly alleviate the above gaps. Our method outperforms previous single-stage regression-based even bottom-up methods and achieves the state-of-the-art result of 71.7 AP on MS COCO test-dev set.
AdaptivePose: Human Parts as Adaptive Points
Dec 27, 2021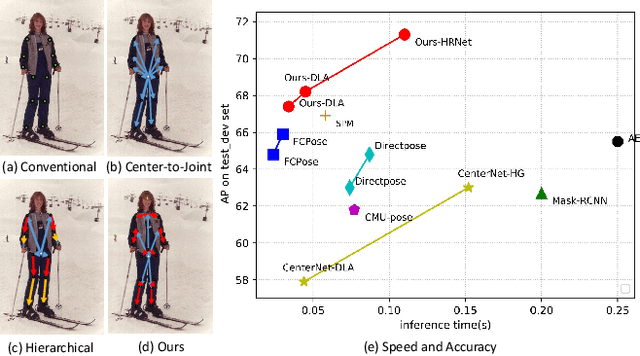
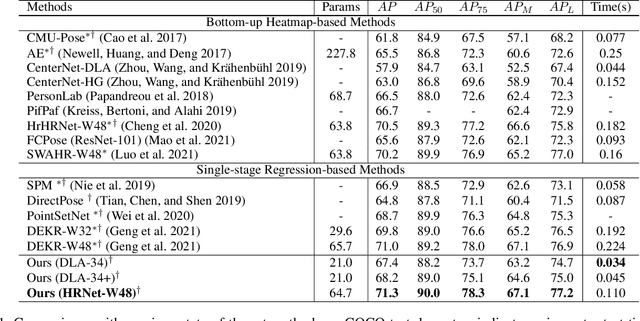
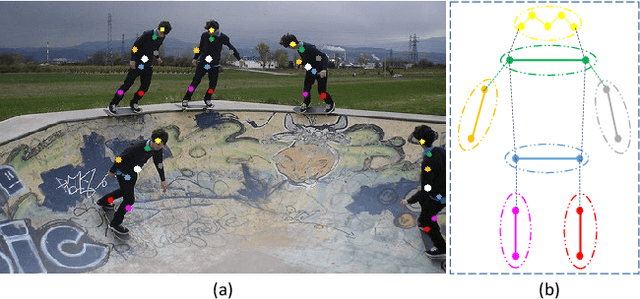
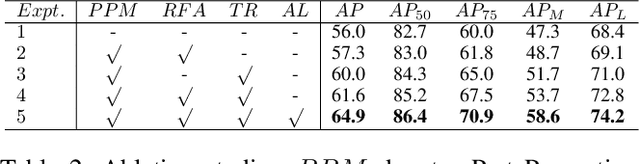
Multi-person pose estimation methods generally follow top-down and bottom-up paradigms, both of which can be considered as two-stage approaches thus leading to the high computation cost and low efficiency. Towards a compact and efficient pipeline for multi-person pose estimation task, in this paper, we propose to represent the human parts as points and present a novel body representation, which leverages an adaptive point set including the human center and seven human-part related points to represent the human instance in a more fine-grained manner. The novel representation is more capable of capturing the various pose deformation and adaptively factorizes the long-range center-to-joint displacement thus delivers a single-stage differentiable network to more precisely regress multi-person pose, termed as AdaptivePose. For inference, our proposed network eliminates the grouping as well as refinements and only needs a single-step disentangling process to form multi-person pose. Without any bells and whistles, we achieve the best speed-accuracy trade-offs of 67.4% AP / 29.4 fps with DLA-34 and 71.3% AP / 9.1 fps with HRNet-W48 on COCO test-dev dataset.
SPCNet:Spatial Preserve and Content-aware Network for Human Pose Estimation
Apr 13, 2020
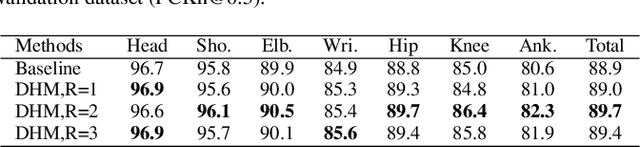
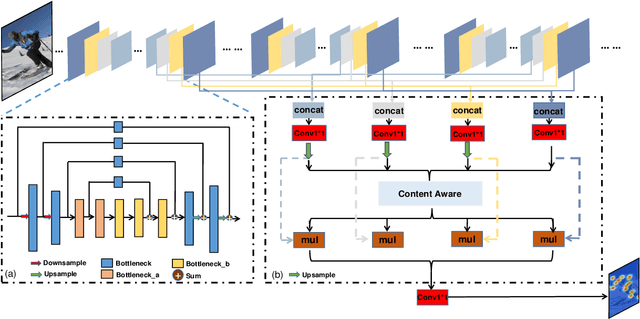
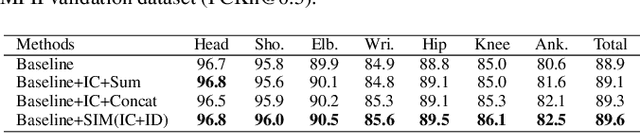
Human pose estimation is a fundamental yet challenging task in computer vision. Although deep learning techniques have made great progress in this area, difficult scenarios (e.g., invisible keypoints, occlusions, complex multi-person scenarios, and abnormal poses) are still not well-handled. To alleviate these issues, we propose a novel Spatial Preserve and Content-aware Network(SPCNet), which includes two effective modules: Dilated Hourglass Module(DHM) and Selective Information Module(SIM). By using the Dilated Hourglass Module, we can preserve the spatial resolution along with large receptive field. Similar to Hourglass Network, we stack the DHMs to get the multi-stage and multi-scale information. Then, a Selective Information Module is designed to select relatively important features from different levels under a sufficient consideration of spatial content-aware mechanism and thus considerably improves the performance. Extensive experiments on MPII, LSP and FLIC human pose estimation benchmarks demonstrate the effectiveness of our network. In particular, we exceed previous methods and achieve the state-of-the-art performance on three aforementioned benchmark datasets.