 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity
Dec 09, 2024How can we enable models to comprehend video anomalies occurring over varying temporal scales and contexts? Traditional Video Anomaly Understanding (VAU) methods focus on frame-level anomaly prediction, often missing the interpretability of complex and diverse real-world anomalies. Recent multimodal approaches leverage visual and textual data but lack hierarchical annotations that capture both short-term and long-term anomalies. To address this challenge, we introduce HIVAU-70k, a large-scale benchmark for hierarchical video anomaly understanding across any granularity. We develop a semi-automated annotation engine that efficiently scales high-quality annotations by combining manual video segmentation with recursive free-text annotation using large language models (LLMs). This results in over 70,000 multi-granular annotations organized at clip-level, event-level, and video-level segments. For efficient anomaly detection in long videos, we propose the Anomaly-focused Temporal Sampler (ATS). ATS integrates an anomaly scorer with a density-aware sampler to adaptively select frames based on anomaly scores, ensuring that the multimodal LLM concentrates on anomaly-rich regions, which significantly enhances both efficiency and accuracy. Extensive experiments demonstrate that our hierarchical instruction data markedly improves anomaly comprehension. The integrated ATS and visual-language model outperform traditional methods in processing long videos. Our benchmark and model are publicly available at https://github.com/pipixin321/HolmesVAU.
GlanceVAD: Exploring Glance Supervision for Label-efficient Video Anomaly Detection
Mar 12, 2024



In recent years, video anomaly detection has been extensively investigated in both unsupervised and weakly supervised settings to alleviate costly temporal labeling. Despite significant progress, these methods still suffer from unsatisfactory results such as numerous false alarms, primarily due to the absence of precise temporal anomaly annotation. In this paper, we present a novel labeling paradigm, termed "glance annotation", to achieve a better balance between anomaly detection accuracy and annotation cost. Specifically, glance annotation is a random frame within each abnormal event, which can be easily accessed and is cost-effective. To assess its effectiveness, we manually annotate the glance annotations for two standard video anomaly detection datasets: UCF-Crime and XD-Violence. Additionally, we propose a customized GlanceVAD method, that leverages gaussian kernels as the basic unit to compose the temporal anomaly distribution, enabling the learning of diverse and robust anomaly representations from the glance annotations. Through comprehensive analysis and experiments, we verify that the proposed labeling paradigm can achieve an excellent trade-off between annotation cost and model performance. Extensive experimental results also demonstrate the effectiveness of our GlanceVAD approach, which significantly outperforms existing advanced unsupervised and weakly supervised methods. Code and annotations will be publicly available at https://github.com/pipixin321/GlanceVAD.
FamilySeer: Towards Optimized Tensor Codes by Exploiting Computation Subgraph Similarity
Jan 01, 2022
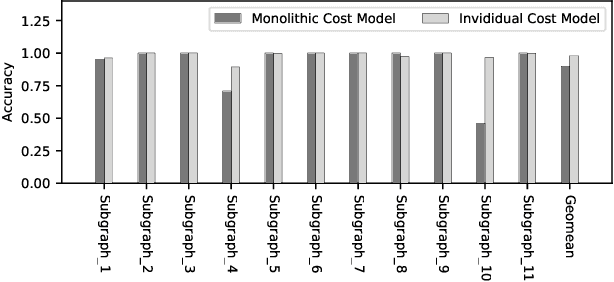
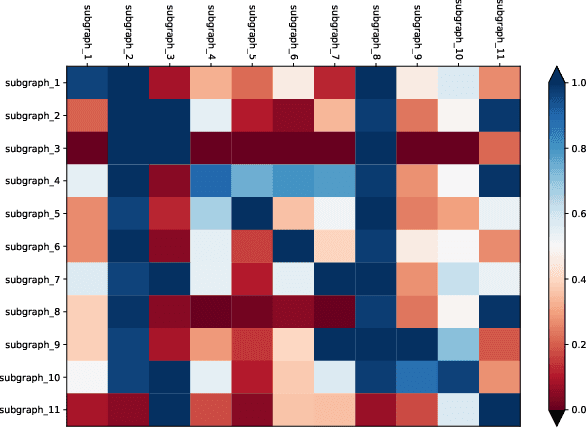

Deploying various deep learning (DL) models efficiently has boosted the research on DL compilers. The difficulty of generating optimized tensor codes drives DL compiler to ask for the auto-tuning approaches, and the increasing demands require increasing auto-tuning efficiency and quality. Currently, the DL compilers partition the input DL models into several subgraphs and leverage the auto-tuning to find the optimal tensor codes of these subgraphs. However, existing auto-tuning approaches usually regard subgraphs as individual ones and overlook the similarities across them, and thus fail to exploit better tensor codes under limited time budgets. We propose FamilySeer, an auto-tuning framework for DL compilers that can generate better tensor codes even with limited time budgets. FamilySeer exploits the similarities and differences among subgraphs can organize them into subgraph families, where the tuning of one subgraph can also improve other subgraphs within the same family. The cost model of each family gets more purified training samples generated by the family and becomes more accurate so that the costly measurements on real hardware can be replaced with the lightweight estimation through cost model. Our experiments show that FamilySeer can generate model codes with the same code performance more efficiently than state-of-the-art auto-tuning frameworks.