 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREPAIR: Rank Correlation and Noisy Pair Half-replacing with Memory for Noisy Correspondence
Mar 13, 2024



The presence of noise in acquired data invariably leads to performance degradation in cross-modal matching. Unfortunately, obtaining precise annotations in the multimodal field is expensive, which has prompted some methods to tackle the mismatched data pair issue in cross-modal matching contexts, termed as noisy correspondence. However, most of these existing noisy correspondence methods exhibit the following limitations: a) the problem of self-reinforcing error accumulation, and b) improper handling of noisy data pair. To tackle the two problems, we propose a generalized framework termed as Rank corrElation and noisy Pair hAlf-replacing wIth memoRy (REPAIR), which benefits from maintaining a memory bank for features of matched pairs. Specifically, we calculate the distances between the features in the memory bank and those of the target pair for each respective modality, and use the rank correlation of these two sets of distances to estimate the soft correspondence label of the target pair. Estimating soft correspondence based on memory bank features rather than using a similarity network can avoid the accumulation of errors due to incorrect network identifications. For pairs that are completely mismatched, REPAIR searches the memory bank for the most matching feature to replace one feature of one modality, instead of using the original pair directly or merely discarding the mismatched pair. We conduct experiments on three cross-modal datasets, i.e., Flickr30K, MSCOCO, and CC152K, proving the effectiveness and robustness of our REPAIR on synthetic and real-world noise.
Spatial Cascaded Clustering and Weighted Memory for Unsupervised Person Re-identification
Mar 01, 2024



Recent unsupervised person re-identification (re-ID) methods achieve high performance by leveraging fine-grained local context. These methods are referred to as part-based methods. However, most part-based methods obtain local contexts through horizontal division, which suffer from misalignment due to various human poses. Additionally, the misalignment of semantic information in part features restricts the use of metric learning, thus affecting the effectiveness of part-based methods. The two issues mentioned above result in the under-utilization of part features in part-based methods. We introduce the Spatial Cascaded Clustering and Weighted Memory (SCWM) method to address these challenges. SCWM aims to parse and align more accurate local contexts for different human body parts while allowing the memory module to balance hard example mining and noise suppression. Specifically, we first analyze the foreground omissions and spatial confusions issues in the previous method. Then, we propose foreground and space corrections to enhance the completeness and reasonableness of the human parsing results. Next, we introduce a weighted memory and utilize two weighting strategies. These strategies address hard sample mining for global features and enhance noise resistance for part features, which enables better utilization of both global and part features. Extensive experiments on Market-1501 and MSMT17 validate the proposed method's effectiveness over many state-of-the-art methods.
Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection Approach
Nov 01, 2023

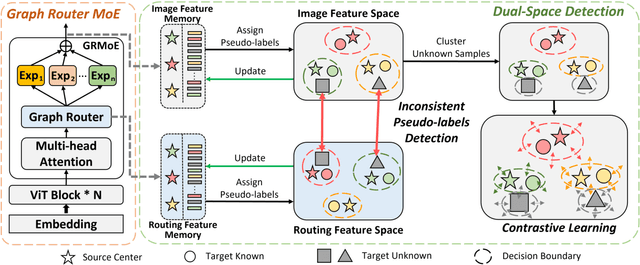

Open Set Domain Adaptation (OSDA) aims to cope with the distribution and label shifts between the source and target domains simultaneously, performing accurate classification for known classes while identifying unknown class samples in the target domain. Most existing OSDA approaches, depending on the final image feature space of deep models, require manually-tuned thresholds, and may easily misclassify unknown samples as known classes. Mixture-of-Expert (MoE) could be a remedy. Within an MoE, different experts address different input features, producing unique expert routing patterns for different classes in a routing feature space. As a result, unknown class samples may also display different expert routing patterns to known classes. This paper proposes Dual-Space Detection, which exploits the inconsistencies between the image feature space and the routing feature space to detect unknown class samples without any threshold. Graph Router is further introduced to better make use of the spatial information among image patches. Experiments on three different datasets validated the effectiveness and superiority of our approach. The code will come soon.