 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANet: Robust 3D Object Detection from Point Clouds with Triple Attention
Dec 11, 2019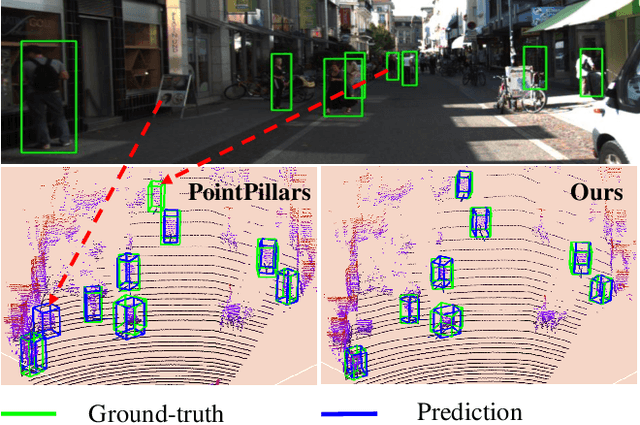

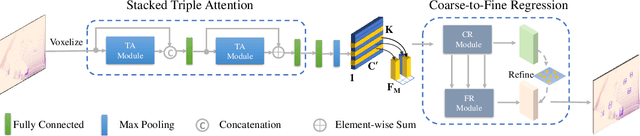

In this paper, we focus on exploring the robustness of the 3D object detection in point clouds, which has been rarely discussed in existing approaches. We observe two crucial phenomena: 1) the detection accuracy of the hard objects, e.g., Pedestrians, is unsatisfactory, 2) when adding additional noise points, the performance of existing approaches decreases rapidly. To alleviate these problems, a novel TANet is introduced in this paper, which mainly contains a Triple Attention (TA) module, and a Coarse-to-Fine Regression (CFR) module. By considering the channel-wise, point-wise and voxel-wise attention jointly, the TA module enhances the crucial information of the target while suppresses the unstable cloud points. Besides, the novel stacked TA further exploits the multi-level feature attention. In addition, the CFR module boosts the accuracy of localization without excessive computation cost. Experimental results on the validation set of KITTI dataset demonstrate that, in the challenging noisy cases, i.e., adding additional random noisy points around each object,the presented approach goes far beyond state-of-the-art approaches. Furthermore, for the 3D object detection task of the KITTI benchmark, our approach ranks the first place on Pedestrian class, by using the point clouds as the only input. The running speed is around 29 frames per second.
3D Object Detection Using Scale Invariant and Feature Reweighting Networks
Jan 08, 2019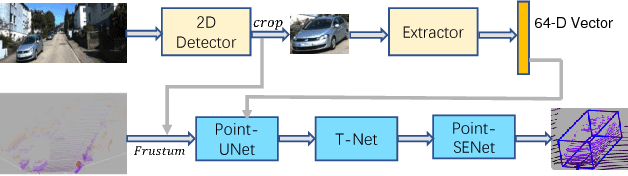
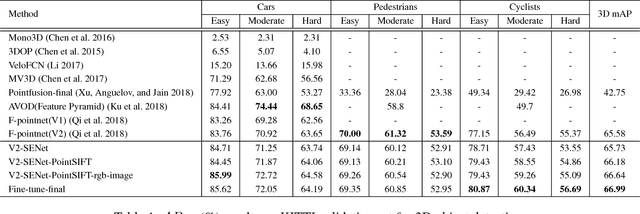


3D object detection plays an important role in a large number of real-world applications. It requires us to estimate the localizations and the orientations of 3D objects in real scenes. In this paper, we present a new network architecture which focuses on utilizing the front view images and frustum point clouds to generate 3D detection results. On the one hand, a PointSIFT module is utilized to improve the performance of 3D segmentation. It can capture the information from different orientations in space and the robustness to different scale shapes. On the other hand, our network obtains the useful features and suppresses the features with less information by a SENet module. This module reweights channel features and estimates the 3D bounding boxes more effectively. Our method is evaluated on both KITTI dataset for outdoor scenes and SUN-RGBD dataset for indoor scenes. The experimental results illustrate that our method achieves better performance than the state-of-the-art methods especially when point clouds are highly sparse.