 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models
Paper and Code


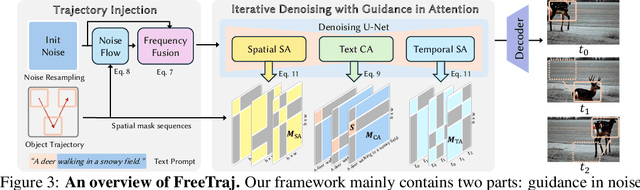
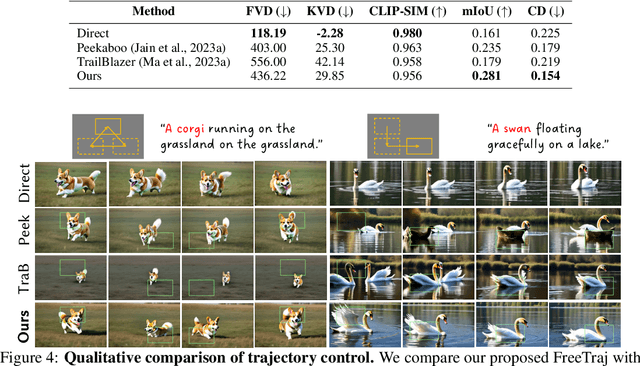
Diffusion model has demonstrated remarkable capability in video generation, which further sparks interest in introducing trajectory control into the generation process. While existing works mainly focus on training-based methods (e.g., conditional adapter), we argue that diffusion model itself allows decent control over the generated content without requiring any training. In this study, we introduce a tuning-free framework to achieve trajectory-controllable video generation, by imposing guidance on both noise construction and attention computation. Specifically, 1) we first show several instructive phenomenons and analyze how initial noises influence the motion trajectory of generated content. 2) Subsequently, we propose FreeTraj, a tuning-free approach that enables trajectory control by modifying noise sampling and attention mechanisms. 3) Furthermore, we extend FreeTraj to facilitate longer and larger video generation with controllable trajectories. Equipped with these designs, users have the flexibility to provide trajectories manually or opt for trajectories automatically generated by the LLM trajectory planner. Extensive experiments validate the efficacy of our approach in enhancing the trajectory controllability of video diffusion models.