 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTac2Pose: A Unified Approach Learned in Simulation for Category-level Visuotactile In-hand Pose Estimation
Sep 19, 2025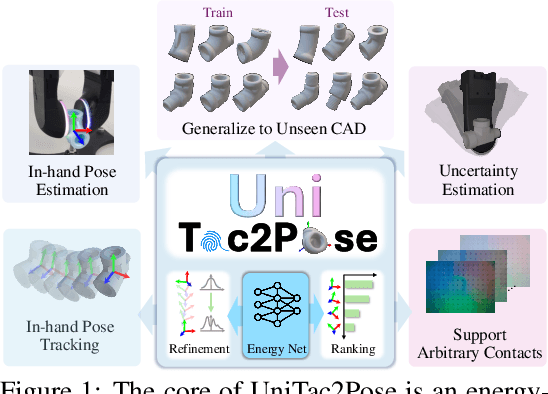
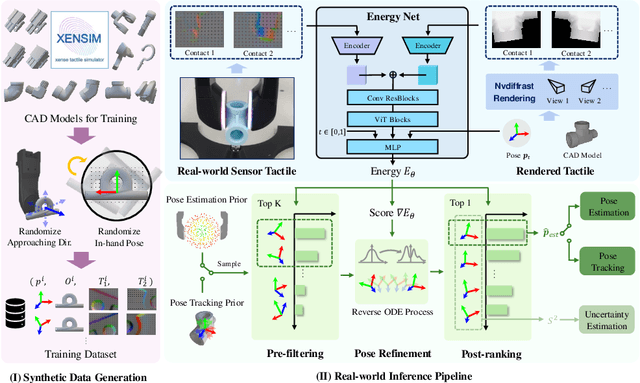

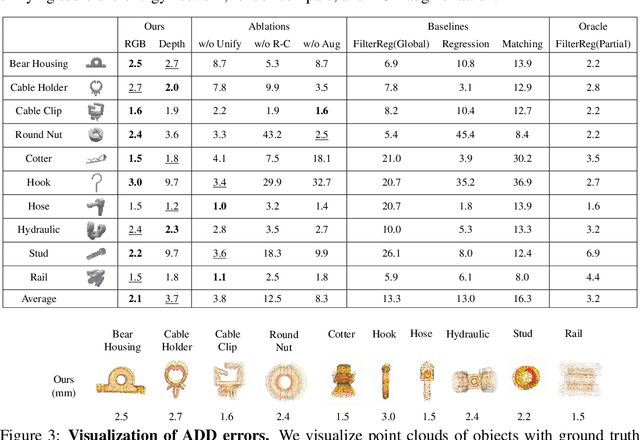
Accurate estimation of the in-hand pose of an object based on its CAD model is crucial in both industrial applications and everyday tasks, ranging from positioning workpieces and assembling components to seamlessly inserting devices like USB connectors. While existing methods often rely on regression, feature matching, or registration techniques, achieving high precision and generalizability to unseen CAD models remains a significant challenge. In this paper, we propose a novel three-stage framework for in-hand pose estimation. The first stage involves sampling and pre-ranking pose candidates, followed by iterative refinement of these candidates in the second stage. In the final stage, post-ranking is applied to identify the most likely pose candidates. These stages are governed by a unified energy-based diffusion model, which is trained solely on simulated data. This energy model simultaneously generates gradients to refine pose estimates and produces an energy scalar that quantifies the quality of the pose estimates. Additionally, borrowing the idea from the computer vision domain, we incorporate a render-compare architecture within the energy-based score network to significantly enhance sim-to-real performance, as demonstrated by our ablation studies. We conduct comprehensive experiments to show that our method outperforms conventional baselines based on regression, matching, and registration techniques, while also exhibiting strong intra-category generalization to previously unseen CAD models. Moreover, our approach integrates tactile object pose estimation, pose tracking, and uncertainty estimation into a unified framework, enabling robust performance across a variety of real-world conditions.
Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking
Jun 06, 2024
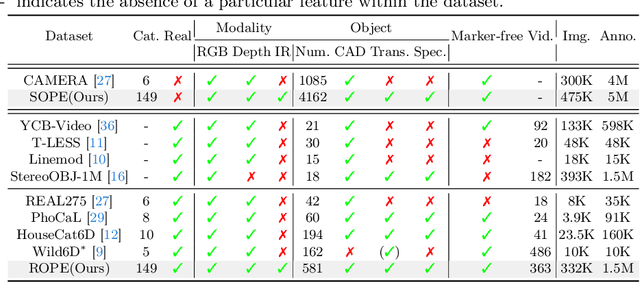

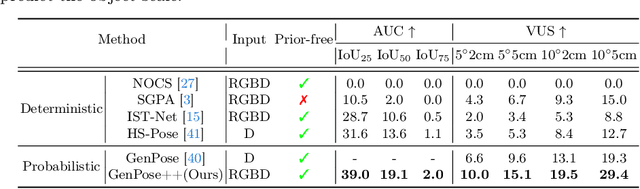
6D Object Pose Estimation is a crucial yet challenging task in computer vision, suffering from a significant lack of large-scale datasets. This scarcity impedes comprehensive evaluation of model performance, limiting research advancements. Furthermore, the restricted number of available instances or categories curtails its applications. To address these issues, this paper introduces Omni6DPose, a substantial dataset characterized by its diversity in object categories, large scale, and variety in object materials. Omni6DPose is divided into three main components: ROPE (Real 6D Object Pose Estimation Dataset), which includes 332K images annotated with over 1.5M annotations across 581 instances in 149 categories; SOPE(Simulated 6D Object Pose Estimation Dataset), consisting of 475K images created in a mixed reality setting with depth simulation, annotated with over 5M annotations across 4162 instances in the same 149 categories; and the manually aligned real scanned objects used in both ROPE and SOPE. Omni6DPose is inherently challenging due to the substantial variations and ambiguities. To address this challenge, we introduce GenPose++, an enhanced version of the SOTA category-level pose estimation framework, incorporating two pivotal improvements: Semantic-aware feature extraction and Clustering-based aggregation. Moreover, we provide a comprehensive benchmarking analysis to evaluate the performance of previous methods on this large-scale dataset in the realms of 6D object pose estimation and pose tracking.