 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuon-Accelerated Attention Distillation for Real-Time Edge Synthesis via Optimized Latent Diffusion
Apr 11, 2025Recent advances in visual synthesis have leveraged diffusion models and attention mechanisms to achieve high-fidelity artistic style transfer and photorealistic text-to-image generation. However, real-time deployment on edge devices remains challenging due to computational and memory constraints. We propose Muon-AD, a co-designed framework that integrates the Muon optimizer with attention distillation for real-time edge synthesis. By eliminating gradient conflicts through orthogonal parameter updates and dynamic pruning, Muon-AD achieves 3.2 times faster convergence compared to Stable Diffusion-TensorRT, while maintaining synthesis quality (15% lower FID, 4% higher SSIM). Our framework reduces peak memory to 7GB on Jetson Orin and enables 24FPS real-time generation through mixed-precision quantization and curriculum learning. Extensive experiments on COCO-Stuff and ImageNet-Texture demonstrate Muon-AD's Pareto-optimal efficiency-quality trade-offs. Here, we show a 65% reduction in communication overhead during distributed training and real-time 10s/image generation on edge GPUs. These advancements pave the way for democratizing high-quality visual synthesis in resource-constrained environments.
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Apr 17, 2024



Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
Referee-Meta-Learning for Fast Adaptation of Locational Fairness
Feb 20, 2024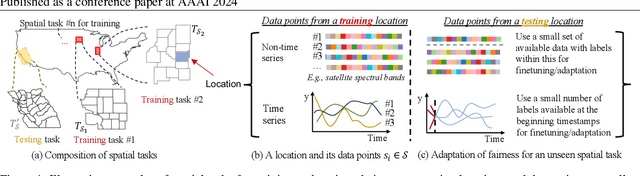
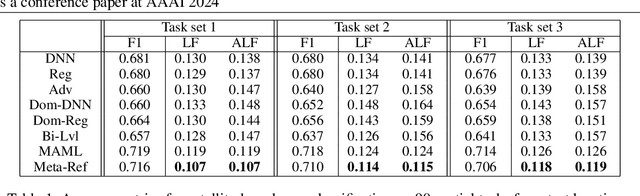
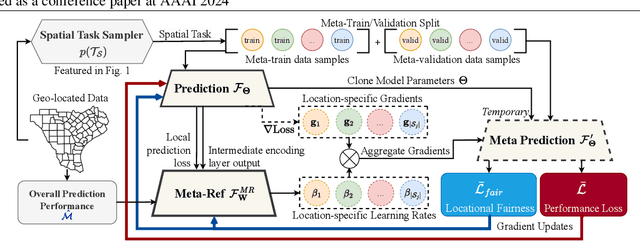
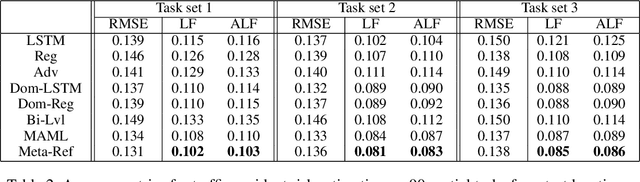
When dealing with data from distinct locations, machine learning algorithms tend to demonstrate an implicit preference of some locations over the others, which constitutes biases that sabotage the spatial fairness of the algorithm. This unfairness can easily introduce biases in subsequent decision-making given broad adoptions of learning-based solutions in practice. However, locational biases in AI are largely understudied. To mitigate biases over locations, we propose a locational meta-referee (Meta-Ref) to oversee the few-shot meta-training and meta-testing of a deep neural network. Meta-Ref dynamically adjusts the learning rates for training samples of given locations to advocate a fair performance across locations, through an explicit consideration of locational biases and the characteristics of input data. We present a three-phase training framework to learn both a meta-learning-based predictor and an integrated Meta-Ref that governs the fairness of the model. Once trained with a distribution of spatial tasks, Meta-Ref is applied to samples from new spatial tasks (i.e., regions outside the training area) to promote fairness during the fine-tune step. We carried out experiments with two case studies on crop monitoring and transportation safety, which show Meta-Ref can improve locational fairness while keeping the overall prediction quality at a similar level.
A Unified HDR Imaging Method with Pixel and Patch Level
Apr 17, 2023



Mapping Low Dynamic Range (LDR) images with different exposures to High Dynamic Range (HDR) remains nontrivial and challenging on dynamic scenes due to ghosting caused by object motion or camera jitting. With the success of Deep Neural Networks (DNNs), several DNNs-based methods have been proposed to alleviate ghosting, they cannot generate approving results when motion and saturation occur. To generate visually pleasing HDR images in various cases, we propose a hybrid HDR deghosting network, called HyHDRNet, to learn the complicated relationship between reference and non-reference images. The proposed HyHDRNet consists of a content alignment subnetwork and a Transformer-based fusion subnetwork. Specifically, to effectively avoid ghosting from the source, the content alignment subnetwork uses patch aggregation and ghost attention to integrate similar content from other non-reference images with patch level and suppress undesired components with pixel level. To achieve mutual guidance between patch-level and pixel-level, we leverage a gating module to sufficiently swap useful information both in ghosted and saturated regions. Furthermore, to obtain a high-quality HDR image, the Transformer-based fusion subnetwork uses a Residual Deformable Transformer Block (RDTB) to adaptively merge information for different exposed regions. We examined the proposed method on four widely used public HDR image deghosting datasets. Experiments demonstrate that HyHDRNet outperforms state-of-the-art methods both quantitatively and qualitatively, achieving appealing HDR visualization with unified textures and colors.
SMAE: Few-shot Learning for HDR Deghosting with Saturation-Aware Masked Autoencoders
Apr 14, 2023

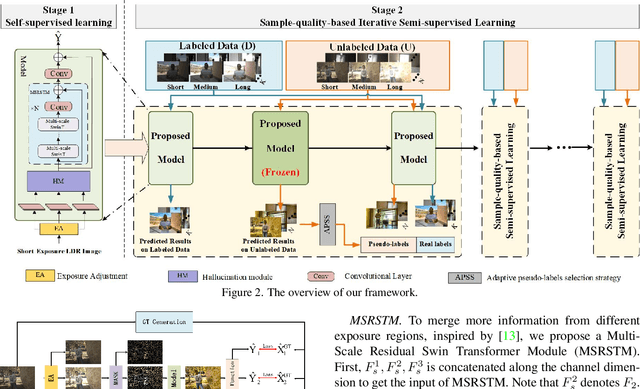

Generating a high-quality High Dynamic Range (HDR) image from dynamic scenes has recently been extensively studied by exploiting Deep Neural Networks (DNNs). Most DNNs-based methods require a large amount of training data with ground truth, requiring tedious and time-consuming work. Few-shot HDR imaging aims to generate satisfactory images with limited data. However, it is difficult for modern DNNs to avoid overfitting when trained on only a few images. In this work, we propose a novel semi-supervised approach to realize few-shot HDR imaging via two stages of training, called SSHDR. Unlikely previous methods, directly recovering content and removing ghosts simultaneously, which is hard to achieve optimum, we first generate content of saturated regions with a self-supervised mechanism and then address ghosts via an iterative semi-supervised learning framework. Concretely, considering that saturated regions can be regarded as masking Low Dynamic Range (LDR) input regions, we design a Saturated Mask AutoEncoder (SMAE) to learn a robust feature representation and reconstruct a non-saturated HDR image. We also propose an adaptive pseudo-label selection strategy to pick high-quality HDR pseudo-labels in the second stage to avoid the effect of mislabeled samples. Experiments demonstrate that SSHDR outperforms state-of-the-art methods quantitatively and qualitatively within and across different datasets, achieving appealing HDR visualization with few labeled samples.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022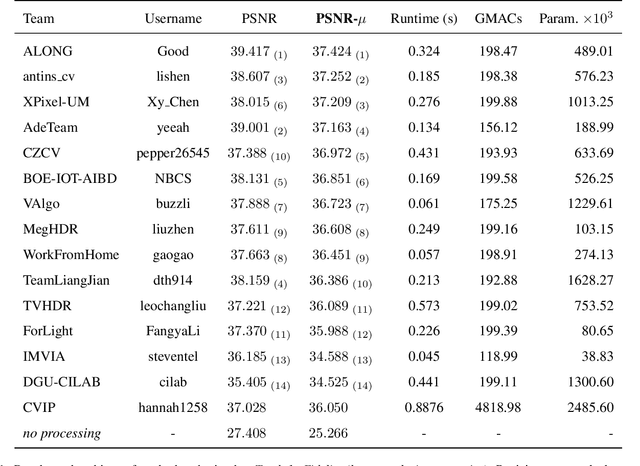
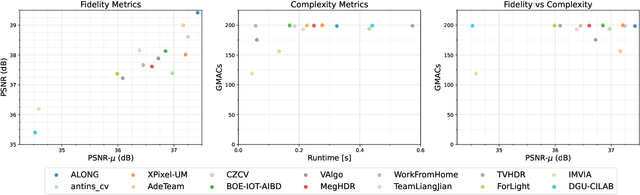
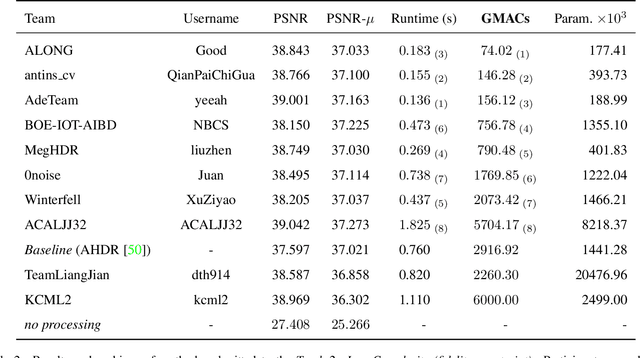
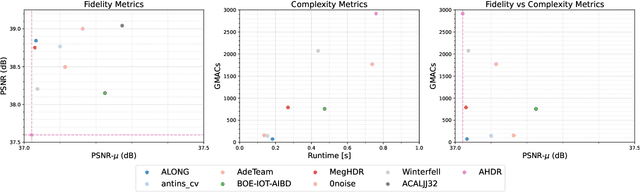
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables