 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeATac: A Multimodal Tactile Finger with Taxelized Dynamic Sensing for Dexterous Manipulation
Oct 30, 2025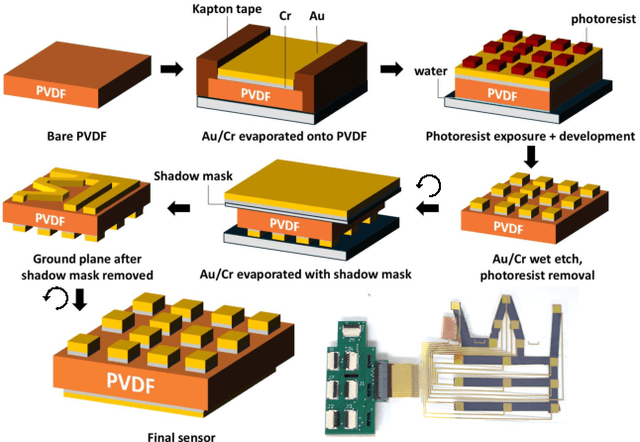
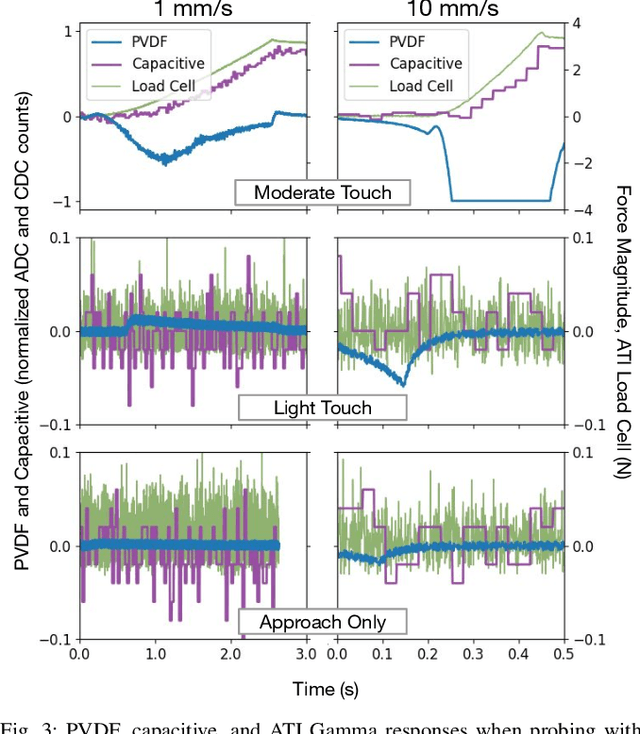
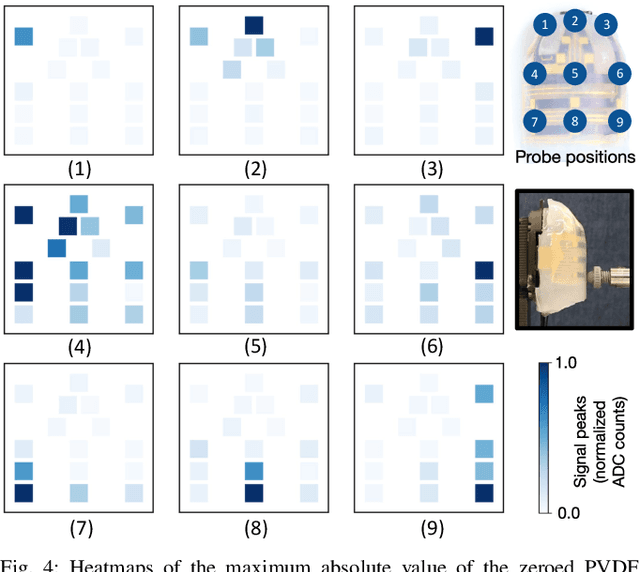
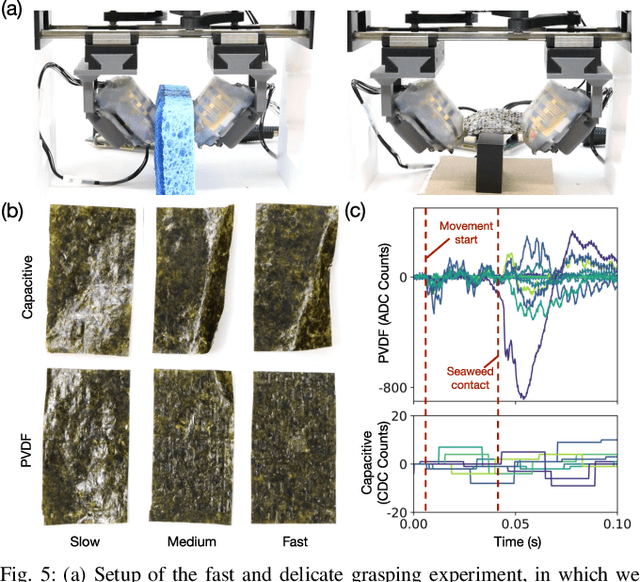
In this work, we introduce SpikeATac, a multimodal tactile finger combining a taxelized and highly sensitive dynamic response (PVDF) with a static transduction method (capacitive) for multimodal touch sensing. Named for its `spiky' response, SpikeATac's 16-taxel PVDF film sampled at 4 kHz provides fast, sensitive dynamic signals to the very onset and breaking of contact. We characterize the sensitivity of the different modalities, and show that SpikeATac provides the ability to stop quickly and delicately when grasping fragile, deformable objects. Beyond parallel grasping, we show that SpikeATac can be used in a learning-based framework to achieve new capabilities on a dexterous multifingered robot hand. We use a learning recipe that combines reinforcement learning from human feedback with tactile-based rewards to fine-tune the behavior of a policy to modulate force. Our hardware platform and learning pipeline together enable a difficult dexterous and contact-rich task that has not previously been achieved: in-hand manipulation of fragile objects. Videos are available at \href{https://roamlab.github.io/spikeatac/}{roamlab.github.io/spikeatac}.
MiniBEE: A New Form Factor for Compact Bimanual Dexterity
Oct 02, 2025Bimanual robot manipulators can achieve impressive dexterity, but typically rely on two full six- or seven- degree-of-freedom arms so that paired grippers can coordinate effectively. This traditional framework increases system complexity while only exploiting a fraction of the overall workspace for dexterous interaction. We introduce the MiniBEE (Miniature Bimanual End-effector), a compact system in which two reduced-mobility arms (3+ DOF each) are coupled into a kinematic chain that preserves full relative positioning between grippers. To guide our design, we formulate a kinematic dexterity metric that enlarges the dexterous workspace while keeping the mechanism lightweight and wearable. The resulting system supports two complementary modes: (i) wearable kinesthetic data collection with self-tracked gripper poses, and (ii) deployment on a standard robot arm, extending dexterity across its entire workspace. We present kinematic analysis and design optimization methods for maximizing dexterous range, and demonstrate an end-to-end pipeline in which wearable demonstrations train imitation learning policies that perform robust, real-world bimanual manipulation.
Meta-World+: An Improved, Standardized, RL Benchmark
May 16, 2025Meta-World is widely used for evaluating multi-task and meta-reinforcement learning agents, which are challenged to master diverse skills simultaneously. Since its introduction however, there have been numerous undocumented changes which inhibit a fair comparison of algorithms. This work strives to disambiguate these results from the literature, while also leveraging the past versions of Meta-World to provide insights into multi-task and meta-reinforcement learning benchmark design. Through this process we release a new open-source version of Meta-World (https://github.com/Farama-Foundation/Metaworld/) that has full reproducibility of past results, is more technically ergonomic, and gives users more control over the tasks that are included in a task set.
VibeCheck: Using Active Acoustic Tactile Sensing for Contact-Rich Manipulation
Apr 22, 2025The acoustic response of an object can reveal a lot about its global state, for example its material properties or the extrinsic contacts it is making with the world. In this work, we build an active acoustic sensing gripper equipped with two piezoelectric fingers: one for generating signals, the other for receiving them. By sending an acoustic vibration from one finger to the other through an object, we gain insight into an object's acoustic properties and contact state. We use this system to classify objects, estimate grasping position, estimate poses of internal structures, and classify the types of extrinsic contacts an object is making with the environment. Using our contact type classification model, we tackle a standard long-horizon manipulation problem: peg insertion. We use a simple simulated transition model based on the performance of our sensor to train an imitation learning policy that is robust to imperfect predictions from the classifier. We finally demonstrate the policy on a UR5 robot with active acoustic sensing as the only feedback.
Task-Based Design and Policy Co-Optimization for Tendon-driven Underactuated Kinematic Chains
May 23, 2024



Underactuated manipulators reduce the number of bulky motors, thereby enabling compact and mechanically robust designs. However, fewer actuators than joints means that the manipulator can only access a specific manifold within the joint space, which is particular to a given hardware configuration and can be low-dimensional and/or discontinuous. Determining an appropriate set of hardware parameters for this class of mechanisms, therefore, is difficult - even for traditional task-based co-optimization methods. In this paper, our goal is to implement a task-based design and policy co-optimization method for underactuated, tendon-driven manipulators. We first formulate a general model for an underactuated, tendon-driven transmission. We then use this model to co-optimize a three-link, two-actuator kinematic chain using reinforcement learning. We demonstrate that our optimized tendon transmission and control policy can be transferred reliably to physical hardware with real-world reaching experiments.
MORPH: Design Co-optimization with Reinforcement Learning via a Differentiable Hardware Model Proxy
Sep 29, 2023

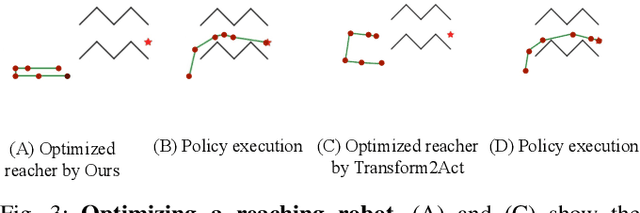

We introduce MORPH, a method for co-optimization of hardware design parameters and control policies in simulation using reinforcement learning. Like most co-optimization methods, MORPH relies on a model of the hardware being optimized, usually simulated based on the laws of physics. However, such a model is often difficult to integrate into an effective optimization routine. To address this, we introduce a proxy hardware model, which is always differentiable and enables efficient co-optimization alongside a long-horizon control policy using RL. MORPH is designed to ensure that the optimized hardware proxy remains as close as possible to its realistic counterpart, while still enabling task completion. We demonstrate our approach on simulated 2D reaching and 3D multi-fingered manipulation tasks.
Pick2Place: Task-aware 6DoF Grasp Estimation via Object-Centric Perspective Affordance
Apr 08, 2023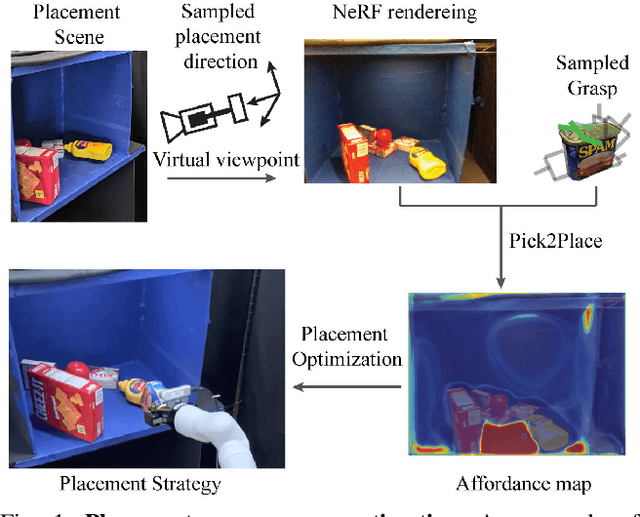
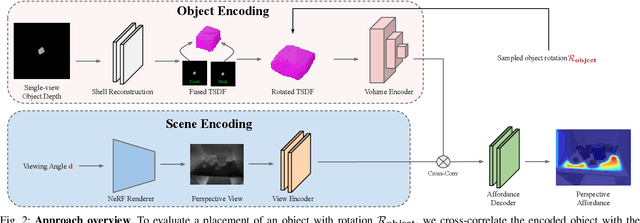
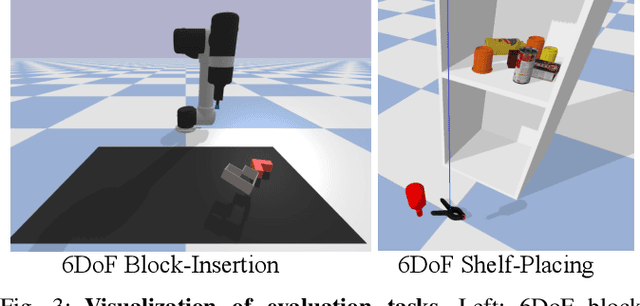

The choice of a grasp plays a critical role in the success of downstream manipulation tasks. Consider a task of placing an object in a cluttered scene; the majority of possible grasps may not be suitable for the desired placement. In this paper, we study the synergy between the picking and placing of an object in a cluttered scene to develop an algorithm for task-aware grasp estimation. We present an object-centric action space that encodes the relationship between the geometry of the placement scene and the object to be placed in order to provide placement affordance maps directly from perspective views of the placement scene. This action space enables the computation of a one-to-one mapping between the placement and picking actions allowing the robot to generate a diverse set of pick-and-place proposals and to optimize for a grasp under other task constraints such as robot kinematics and collision avoidance. With experiments both in simulation and on a real robot we demonstrate that with our method, the robot is able to successfully complete the task of placement-aware grasping with over 89% accuracy in such a way that generalizes to novel objects and scenes.
Decision Making for Human-in-the-loop Robotic Agents via Uncertainty-Aware Reinforcement Learning
Mar 14, 2023In a Human-in-the-Loop paradigm, a robotic agent is able to act mostly autonomously in solving a task, but can request help from an external expert when needed. However, knowing when to request such assistance is critical: too few requests can lead to the robot making mistakes, but too many requests can overload the expert. In this paper, we present a Reinforcement Learning based approach to this problem, where a semi-autonomous agent asks for external assistance when it has low confidence in the eventual success of the task. The confidence level is computed by estimating the variance of the return from the current state. We show that this estimate can be iteratively improved during training using a Bellman-like recursion. On discrete navigation problems with both fully- and partially-observable state information, we show that our method makes effective use of a limited budget of expert calls at run-time, despite having no access to the expert at training time.
Discovering Synergies for Robot Manipulation with Multi-Task Reinforcement Learning
Oct 04, 2021
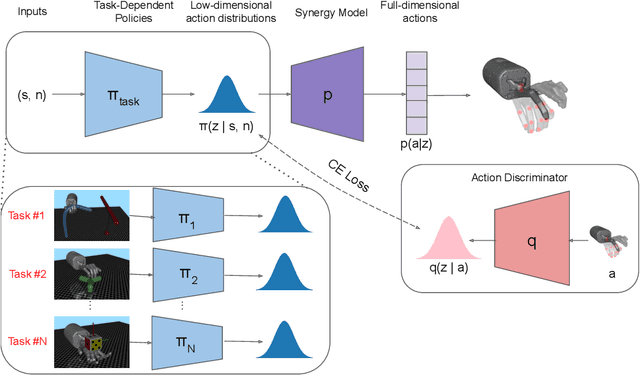
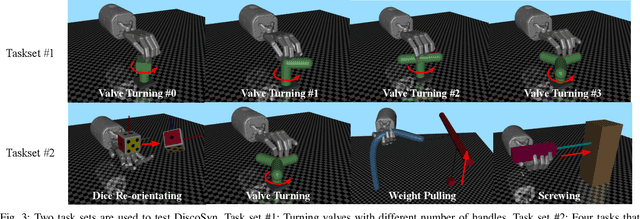
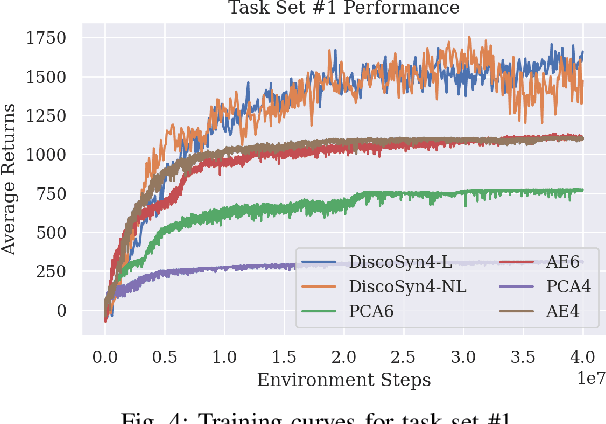
Controlling robotic manipulators with high-dimensional action spaces for dexterous tasks is a challenging problem. Inspired by human manipulation, researchers have studied generating and using postural synergies for robot hands to accomplish manipulation tasks, leveraging the lower dimensional nature of synergistic action spaces. However, many of these works require pre-collected data from an existing controller in order to derive such a subspace by means of dimensionality reduction. In this paper, we present a framework that simultaneously discovers a synergy space and a multi-task policy that operates on this low-dimensional action space to accomplish diverse manipulation tasks. We demonstrate that our end-to-end method is able to perform multiple tasks using few synergies, and outperforms sequential methods that apply dimensionality reduction to independently collected data. We also show that deriving synergies using multiple tasks can lead to a subspace that enables robots to efficiently learn new manipulation tasks and interactions with new objects.
UMPNet: Universal Manipulation Policy Network for Articulated Objects
Sep 19, 2021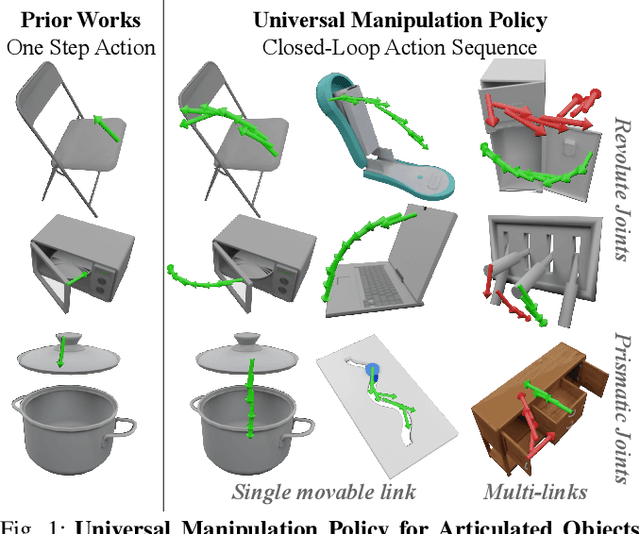
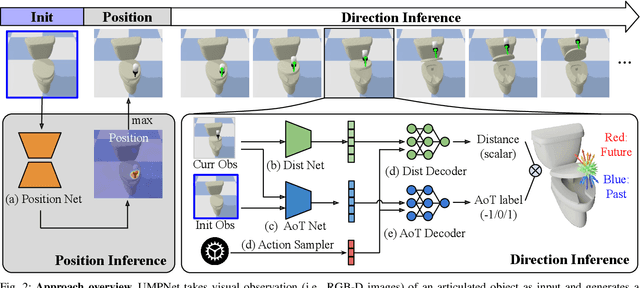


We introduce the Universal Manipulation Policy Network (UMPNet) -- a single image-based policy network that infers closed-loop action sequences for manipulating arbitrary articulated objects. To infer a wide range of action trajectories, the policy supports 6DoF action representation and varying trajectory length. To handle a diverse set of objects, the policy learns from objects with different articulation structures and generalizes to unseen objects or categories. The policy is trained with self-guided exploration without any human demonstrations, scripted policy, or pre-defined goal conditions. To support effective multi-step interaction, we introduce a novel Arrow-of-Time action attribute that indicates whether an action will change the object state back to the past or forward into the future. With the Arrow-of-Time inference at each interaction step, the learned policy is able to select actions that consistently lead towards or away from a given state, thereby, enabling both effective state exploration and goal-conditioned manipulation. Video is available at https://youtu.be/KqlvcL9RqKM