 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics-Aligned Shared Hypernetworks for Zero-Shot Actuator Inversion
Feb 06, 2026Zero-shot generalization in contextual reinforcement learning remains a core challenge, particularly when the context is latent and must be inferred from data. A canonical failure mode is actuator inversion, where identical actions produce opposite physical effects under a latent binary context. We propose DMA*-SH, a framework where a single hypernetwork, trained solely via dynamics prediction, generates a small set of adapter weights shared across the dynamics model, policy, and action-value function. This shared modulation imparts an inductive bias matched to actuator inversion, while input/output normalization and random input masking stabilize context inference, promoting directionally concentrated representations. We provide theoretical support via an expressivity separation result for hypernetwork modulation, and a variance decomposition with policy-gradient variance bounds that formalize how within-mode compression improves learning under actuator inversion. For evaluation, we introduce the Actuator Inversion Benchmark (AIB), a suite of environments designed to isolate discontinuous context-to-dynamics interactions. On AIB's held-out actuator-inversion tasks, DMA*-SH achieves zero-shot generalization, outperforming domain randomization by 111.8% and surpassing a standard context-aware baseline by 16.1%.
Meta-World+: An Improved, Standardized, RL Benchmark
May 16, 2025Meta-World is widely used for evaluating multi-task and meta-reinforcement learning agents, which are challenged to master diverse skills simultaneously. Since its introduction however, there have been numerous undocumented changes which inhibit a fair comparison of algorithms. This work strives to disambiguate these results from the literature, while also leveraging the past versions of Meta-World to provide insights into multi-task and meta-reinforcement learning benchmark design. Through this process we release a new open-source version of Meta-World (https://github.com/Farama-Foundation/Metaworld/) that has full reproducibility of past results, is more technically ergonomic, and gives users more control over the tasks that are included in a task set.
Scilab-RL: A software framework for efficient reinforcement learning and cognitive modeling research
Jan 25, 2024One problem with researching cognitive modeling and reinforcement learning (RL) is that researchers spend too much time on setting up an appropriate computational framework for their experiments. Many open source implementations of current RL algorithms exist, but there is a lack of a modular suite of tools combining different robotic simulators and platforms, data visualization, hyperparameter optimization, and baseline experiments. To address this problem, we present Scilab-RL, a software framework for efficient research in cognitive modeling and reinforcement learning for robotic agents. The framework focuses on goal-conditioned reinforcement learning using Stable Baselines 3 and the OpenAI gym interface. It enables native possibilities for experiment visualizations and hyperparameter optimization. We describe how these features enable researchers to conduct experiments with minimal time effort, thus maximizing research output.
Language-Conditioned Reinforcement Learning to Solve Misunderstandings with Action Corrections
Nov 18, 2022

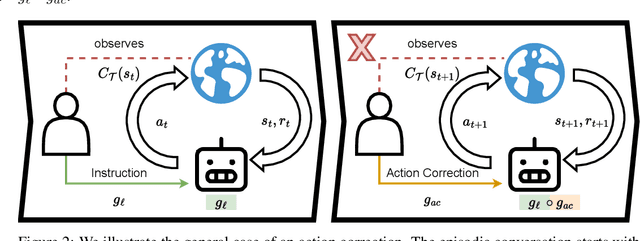
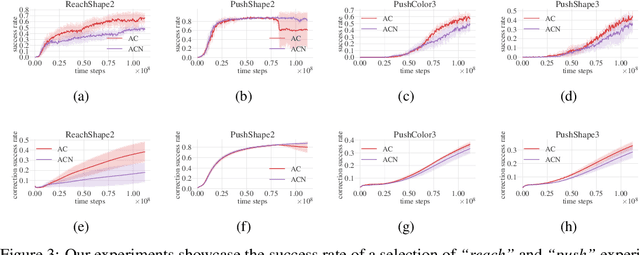
Human-to-human conversation is not just talking and listening. It is an incremental process where participants continually establish a common understanding to rule out misunderstandings. Current language understanding methods for intelligent robots do not consider this. There exist numerous approaches considering non-understandings, but they ignore the incremental process of resolving misunderstandings. In this article, we present a first formalization and experimental validation of incremental action-repair for robotic instruction-following based on reinforcement learning. To evaluate our approach, we propose a collection of benchmark environments for action correction in language-conditioned reinforcement learning, utilizing a synthetic instructor to generate language goals and their corresponding corrections. We show that a reinforcement learning agent can successfully learn to understand incremental corrections of misunderstood instructions.
Grounding Hindsight Instructions in Multi-Goal Reinforcement Learning for Robotics
Apr 08, 2022

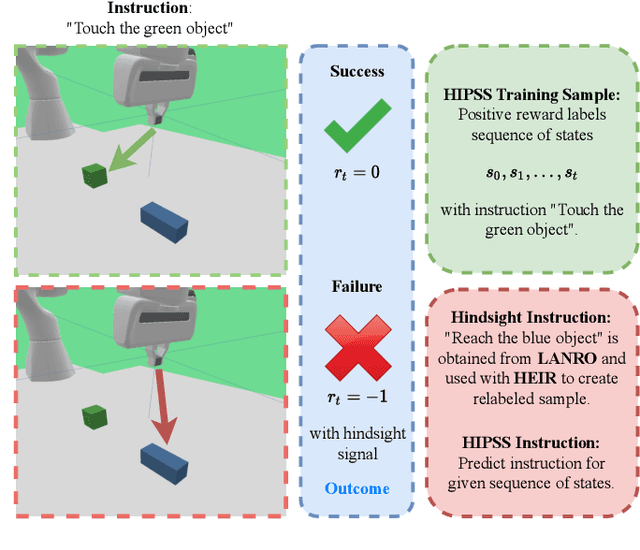
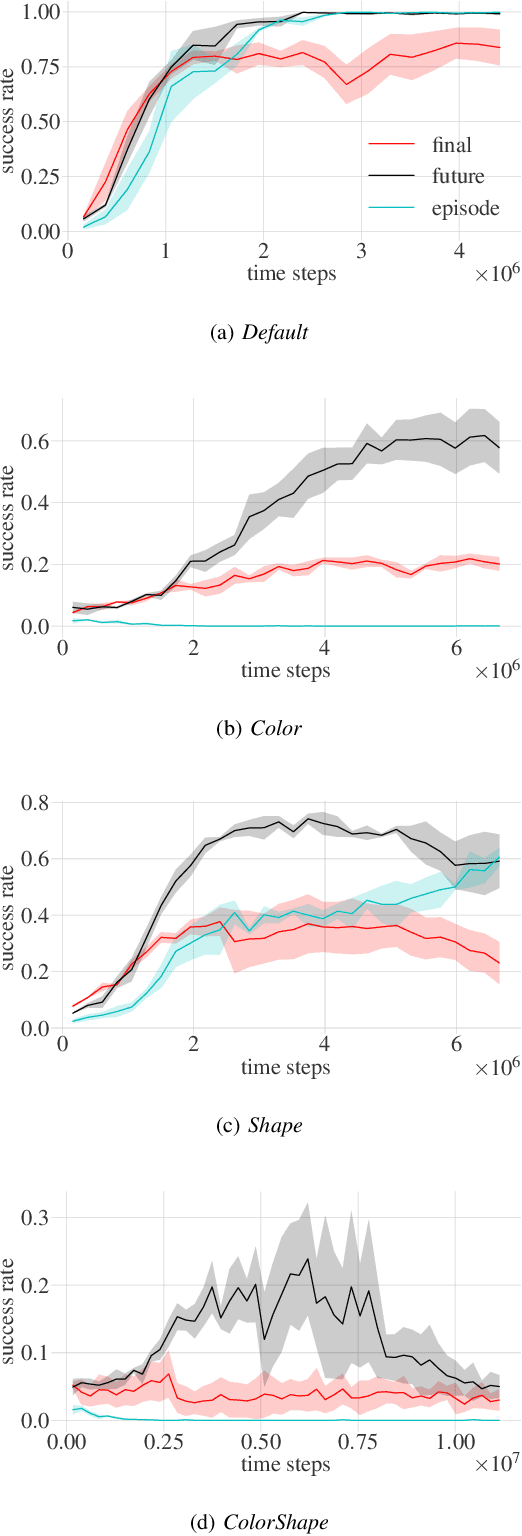
This paper focuses on robotic reinforcement learning with sparse rewards for natural language goal representations. An open problem is the sample-inefficiency that stems from the compositionality of natural language, and from the grounding of language in sensory data and actions. We address these issues with three contributions. We first present a mechanism for hindsight instruction replay utilizing expert feedback. Second, we propose a seq2seq model to generate linguistic hindsight instructions. Finally, we present a novel class of language-focused learning tasks. We show that hindsight instructions improve the learning performance, as expected. In addition, we also provide an unexpected result: We show that the learning performance of our agent can be improved by one third if, in a sense, the agent learns to talk to itself in a self-supervised manner. We achieve this by learning to generate linguistic instructions that would have been appropriate as a natural language goal for an originally unintended behavior. Our results indicate that the performance gain increases with the task-complexity.
Curious Hierarchical Actor-Critic Reinforcement Learning
May 27, 2020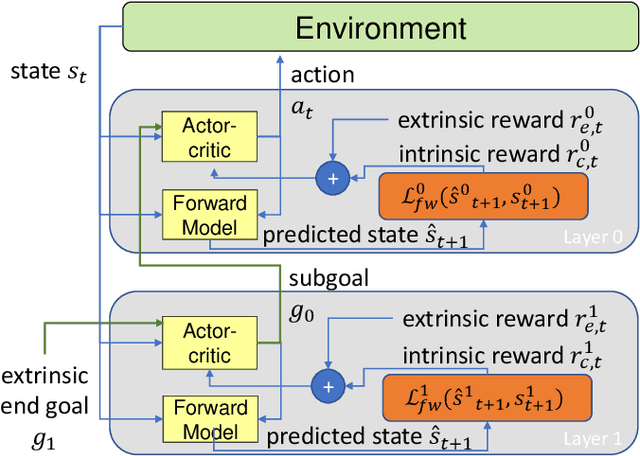
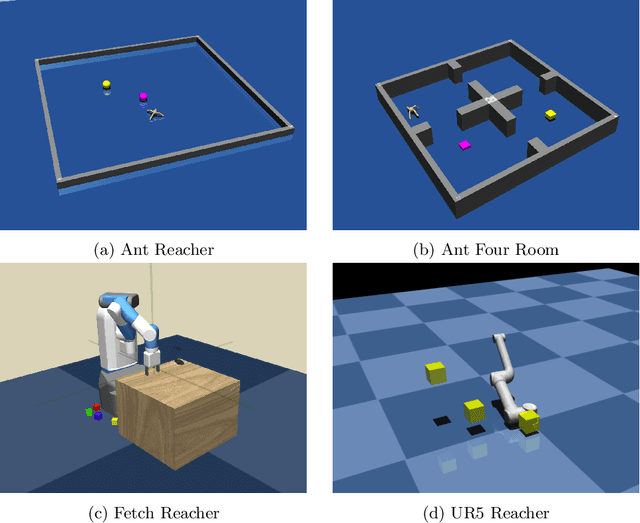
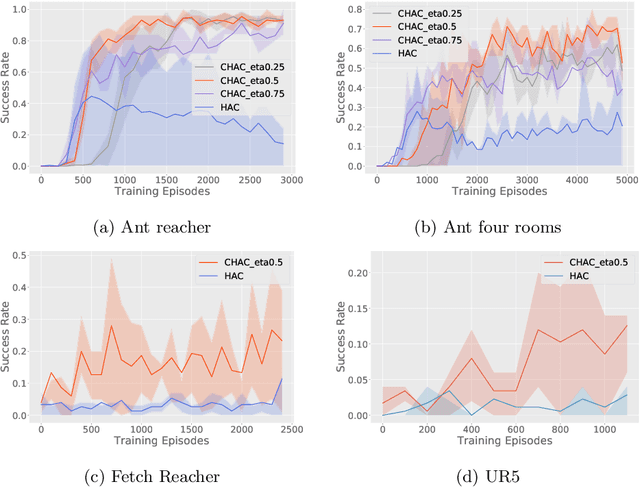
Hierarchical abstraction and curiosity-driven exploration are two common paradigms in current reinforcement learning approaches to break down difficult problems into a sequence of simpler ones and to overcome reward sparsity. However, there is a lack of approaches that combine these paradigms, and it is currently unknown whether curiosity also helps to perform the hierarchical abstraction. As a novelty and scientific contribution, we tackle this issue and develop a method that combines hierarchical reinforcement learning with curiosity. Herein, we extend a contemporary hierarchical actor-critic approach with a forward model to develop a hierarchical notion of curiosity. We demonstrate in several continuous-space environments that curiosity approximately doubles the learning performance and success rates for most of the investigated benchmarking problems.