 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Conditioned Reinforcement Learning to Solve Misunderstandings with Action Corrections
Paper and Code


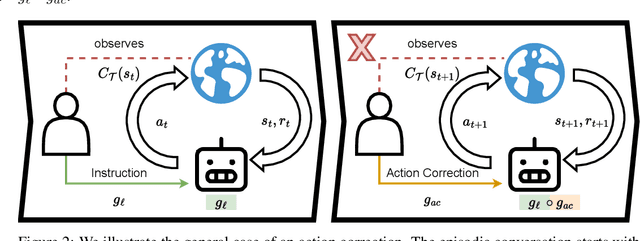
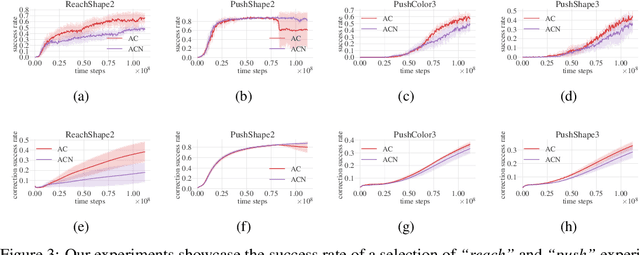
Human-to-human conversation is not just talking and listening. It is an incremental process where participants continually establish a common understanding to rule out misunderstandings. Current language understanding methods for intelligent robots do not consider this. There exist numerous approaches considering non-understandings, but they ignore the incremental process of resolving misunderstandings. In this article, we present a first formalization and experimental validation of incremental action-repair for robotic instruction-following based on reinforcement learning. To evaluate our approach, we propose a collection of benchmark environments for action correction in language-conditioned reinforcement learning, utilizing a synthetic instructor to generate language goals and their corresponding corrections. We show that a reinforcement learning agent can successfully learn to understand incremental corrections of misunderstood instructions.