 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMPNet: Universal Manipulation Policy Network for Articulated Objects
Paper and Code
Sep 19, 2021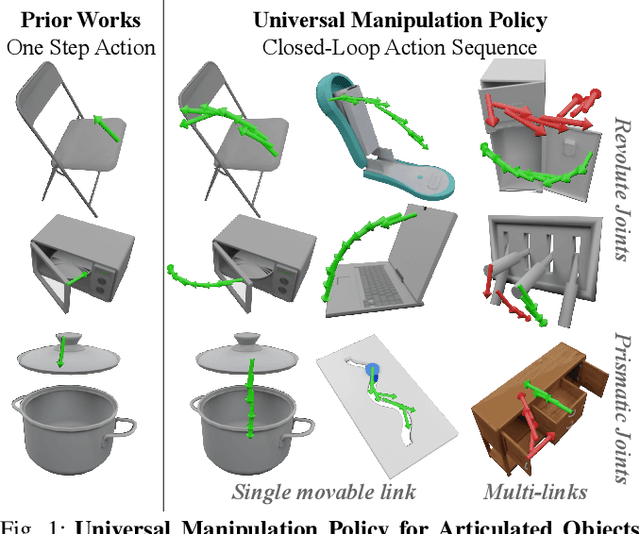
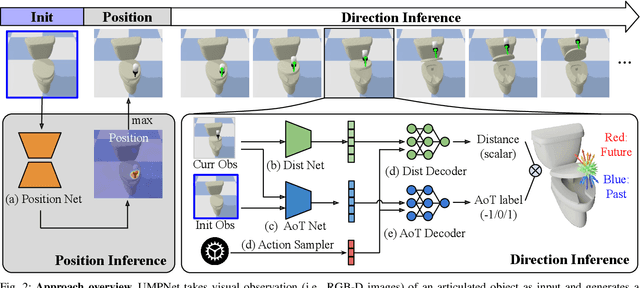


We introduce the Universal Manipulation Policy Network (UMPNet) -- a single image-based policy network that infers closed-loop action sequences for manipulating arbitrary articulated objects. To infer a wide range of action trajectories, the policy supports 6DoF action representation and varying trajectory length. To handle a diverse set of objects, the policy learns from objects with different articulation structures and generalizes to unseen objects or categories. The policy is trained with self-guided exploration without any human demonstrations, scripted policy, or pre-defined goal conditions. To support effective multi-step interaction, we introduce a novel Arrow-of-Time action attribute that indicates whether an action will change the object state back to the past or forward into the future. With the Arrow-of-Time inference at each interaction step, the learned policy is able to select actions that consistently lead towards or away from a given state, thereby, enabling both effective state exploration and goal-conditioned manipulation. Video is available at https://youtu.be/KqlvcL9RqKM