 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Internet-Scale Training For Agents
Feb 10, 2025



The predominant approach for training web navigation agents gathers human demonstrations for a set of popular websites and hand-written tasks, but it is becoming clear that human data are an inefficient resource. We develop a pipeline to facilitate Internet-scale training for agents without laborious human annotations. In the first stage, an LLM generates tasks for 150k diverse websites. In the next stage, LLM agents complete tasks and produce trajectories. In the final stage, an LLM reviews the trajectories and judges their success. Language models are competitive with human annotators, detecting and filtering out harmful content with an accuracy of 97%, generating feasible tasks with an 89% rate, and judging successful trajectories with an 82.6% accuracy. Scaling the pipeline, agents based on Llama 3.1 70B solve 16.7% of tasks for 150k sites. Training on the data generated by our pipeline is competitive with training on human demonstrations. In data-limited settings derived from Mind2Web and WebLINX, we improve Step Accuracy by up to +89.5% and +122.1% respectively for agents trained on mixtures of data from our pipeline, and human data. When training agents with all available human data from these benchmarks, agents fail to generalize to diverse real sites, and adding our data improves their generalization by +149.0% for WebLINX and +156.3% for Mind2Web. Code will be available at: data-for-agents.github.io.
Unsupervised Melody-to-Lyric Generation
May 30, 2023



Automatic melody-to-lyric generation is a task in which song lyrics are generated to go with a given melody. It is of significant practical interest and more challenging than unconstrained lyric generation as the music imposes additional constraints onto the lyrics. The training data is limited as most songs are copyrighted, resulting in models that underfit the complicated cross-modal relationship between melody and lyrics. In this work, we propose a method for generating high-quality lyrics without training on any aligned melody-lyric data. Specifically, we design a hierarchical lyric generation framework that first generates a song outline and second the complete lyrics. The framework enables disentanglement of training (based purely on text) from inference (melody-guided text generation) to circumvent the shortage of parallel data. We leverage the segmentation and rhythm alignment between melody and lyrics to compile the given melody into decoding constraints as guidance during inference. The two-step hierarchical design also enables content control via the lyric outline, a much-desired feature for democratizing collaborative song creation. Experimental results show that our model can generate high-quality lyrics that are more on-topic, singable, intelligible, and coherent than strong baselines, for example SongMASS, a SOTA model trained on a parallel dataset, with a 24% relative overall quality improvement based on human ratings. O
Unsupervised Melody-Guided Lyrics Generation
May 26, 2023



Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation
Nov 30, 2022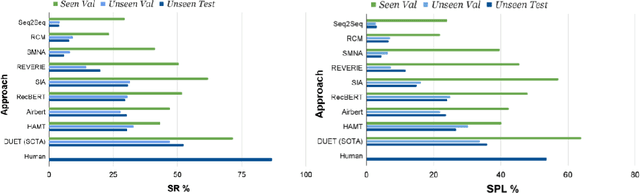
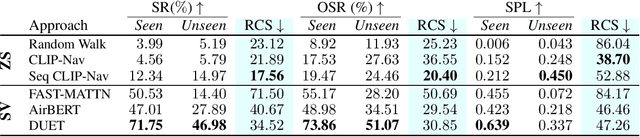


Household environments are visually diverse. Embodied agents performing Vision-and-Language Navigation (VLN) in the wild must be able to handle this diversity, while also following arbitrary language instructions. Recently, Vision-Language models like CLIP have shown great performance on the task of zero-shot object recognition. In this work, we ask if these models are also capable of zero-shot language grounding. In particular, we utilize CLIP to tackle the novel problem of zero-shot VLN using natural language referring expressions that describe target objects, in contrast to past work that used simple language templates describing object classes. We examine CLIP's capability in making sequential navigational decisions without any dataset-specific finetuning, and study how it influences the path that an agent takes. Our results on the coarse-grained instruction following task of REVERIE demonstrate the navigational capability of CLIP, surpassing the supervised baseline in terms of both success rate (SR) and success weighted by path length (SPL). More importantly, we quantitatively show that our CLIP-based zero-shot approach generalizes better to show consistent performance across environments when compared to SOTA, fully supervised learning approaches when evaluated via Relative Change in Success (RCS).
A Simple Approach for Visual Rearrangement: 3D Mapping and Semantic Search
Jun 21, 2022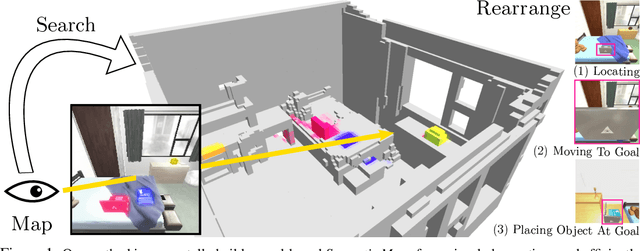
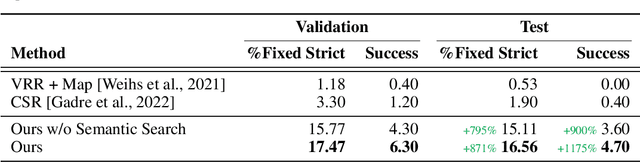
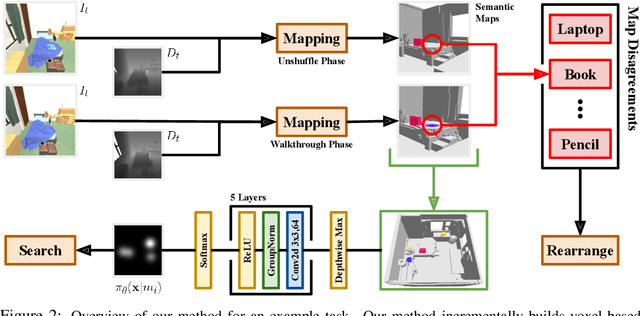
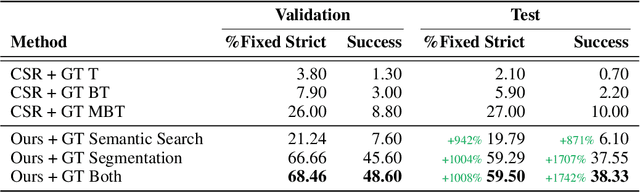
Physically rearranging objects is an important capability for embodied agents. Visual room rearrangement evaluates an agent's ability to rearrange objects in a room to a desired goal based solely on visual input. We propose a simple yet effective method for this problem: (1) search for and map which objects need to be rearranged, and (2) rearrange each object until the task is complete. Our approach consists of an off-the-shelf semantic segmentation model, voxel-based semantic map, and semantic search policy to efficiently find objects that need to be rearranged. On the AI2-THOR Rearrangement Challenge, our method improves on current state-of-the-art end-to-end reinforcement learning-based methods that learn visual rearrangement policies from 0.53% correct rearrangement to 16.56%, using only 2.7% as many samples from the environment.