 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation
Paper and Code
Nov 30, 2022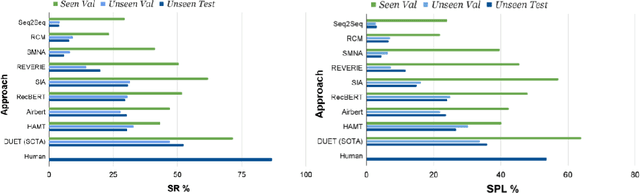
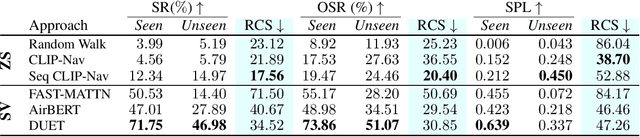


Household environments are visually diverse. Embodied agents performing Vision-and-Language Navigation (VLN) in the wild must be able to handle this diversity, while also following arbitrary language instructions. Recently, Vision-Language models like CLIP have shown great performance on the task of zero-shot object recognition. In this work, we ask if these models are also capable of zero-shot language grounding. In particular, we utilize CLIP to tackle the novel problem of zero-shot VLN using natural language referring expressions that describe target objects, in contrast to past work that used simple language templates describing object classes. We examine CLIP's capability in making sequential navigational decisions without any dataset-specific finetuning, and study how it influences the path that an agent takes. Our results on the coarse-grained instruction following task of REVERIE demonstrate the navigational capability of CLIP, surpassing the supervised baseline in terms of both success rate (SR) and success weighted by path length (SPL). More importantly, we quantitatively show that our CLIP-based zero-shot approach generalizes better to show consistent performance across environments when compared to SOTA, fully supervised learning approaches when evaluated via Relative Change in Success (RCS).