 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSongTrans: An unified song transcription and alignment method for lyrics and notes
Sep 22, 2024



The quantity of processed data is crucial for advancing the field of singing voice synthesis. While there are tools available for lyric or note transcription tasks, they all need pre-processed data which is relatively time-consuming (e.g., vocal and accompaniment separation). Besides, most of these tools are designed to address a single task and struggle with aligning lyrics and notes (i.e., identifying the corresponding notes of each word in lyrics). To address those challenges, we first design a pipeline by optimizing existing tools and annotating numerous lyric-note pairs of songs. Then, based on the annotated data, we train a unified SongTrans model that can directly transcribe lyrics and notes while aligning them simultaneously, without requiring pre-processing songs. Our SongTrans model consists of two modules: (1) the \textbf{Autoregressive module} predicts the lyrics, along with the duration and note number corresponding to each word in a lyric. (2) the \textbf{Non-autoregressive module} predicts the pitch and duration of the notes. Our experiments demonstrate that SongTrans achieves state-of-the-art (SOTA) results in both lyric and note transcription tasks. Furthermore, it is the first model capable of aligning lyrics with notes. Experimental results demonstrate that the SongTrans model can effectively adapt to different types of songs (e.g., songs with accompaniment), showcasing its versatility for real-world applications.
Qwen2 Technical Report
Jul 16, 2024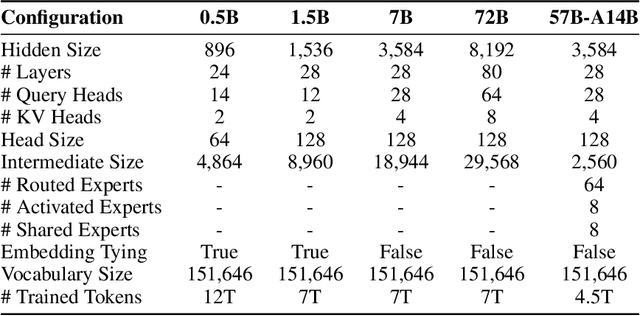
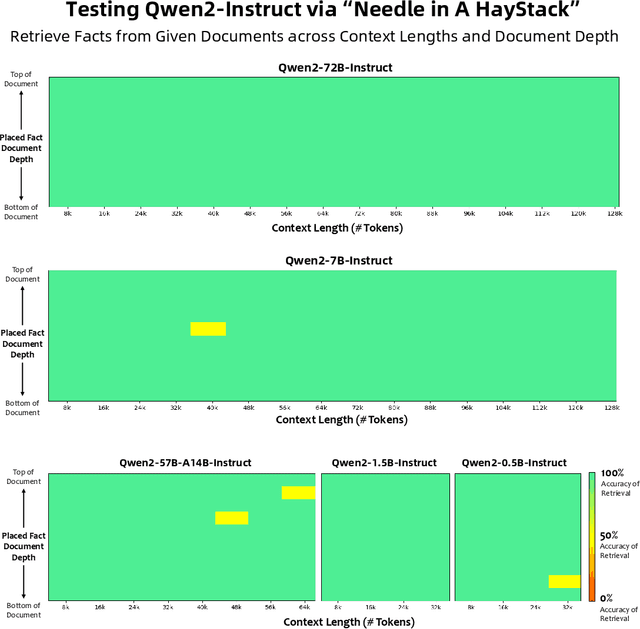
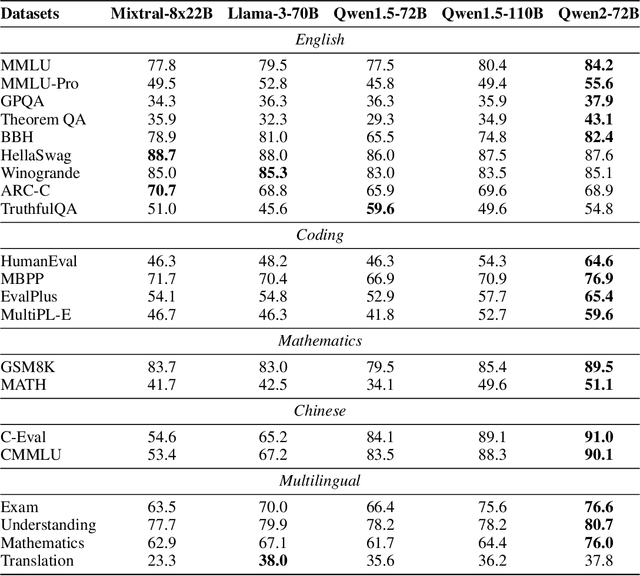
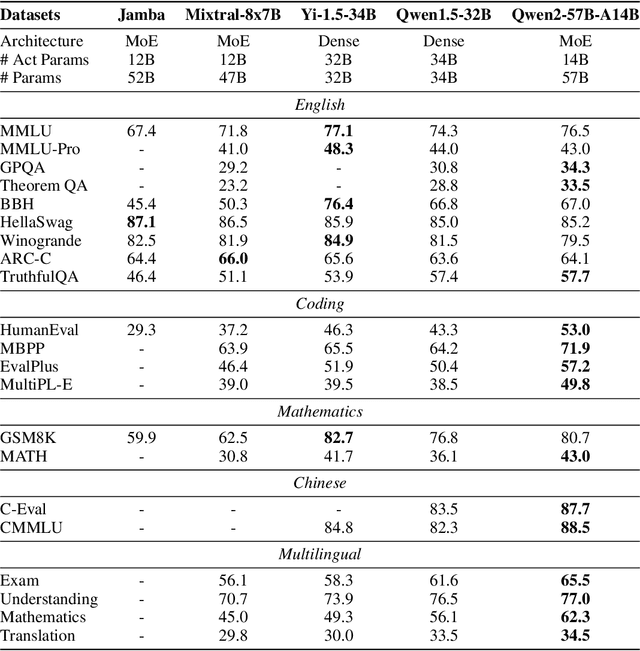
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Qwen2-Audio Technical Report
Jul 15, 2024We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. In contrast to complex hierarchical tags, we have simplified the pre-training process by utilizing natural language prompts for different data and tasks, and have further expanded the data volume. We have boosted the instruction-following capability of Qwen2-Audio and implemented two distinct audio interaction modes for voice chat and audio analysis. In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input. In the audio analysis mode, users could provide audio and text instructions for analysis during the interaction. Note that we do not use any system prompts to switch between voice chat and audio analysis modes. Qwen2-Audio is capable of intelligently comprehending the content within audio and following voice commands to respond appropriately. For instance, in an audio segment that simultaneously contains sounds, multi-speaker conversations, and a voice command, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio. Additionally, DPO has optimized the model's performance in terms of factuality and adherence to desired behavior. According to the evaluation results from AIR-Bench, Qwen2-Audio outperformed previous SOTAs, such as Gemini-1.5-pro, in tests focused on audio-centric instruction-following capabilities. Qwen2-Audio is open-sourced with the aim of fostering the advancement of the multi-modal language community.
A Multi-Scale Attentive Transformer for Multi-Instrument Symbolic Music Generation
May 26, 2023



Recently, multi-instrument music generation has become a hot topic. Different from single-instrument generation, multi-instrument generation needs to consider inter-track harmony besides intra-track coherence. This is usually achieved by composing note segments from different instruments into a signal sequence. This composition could be on different scales, such as note, bar, or track. Most existing work focuses on a particular scale, leading to a shortage in modeling music with diverse temporal and track dependencies. This paper proposes a multi-scale attentive Transformer model to improve the quality of multi-instrument generation. We first employ multiple Transformer decoders to learn multi-instrument representations of different scales and then design an attentive mechanism to fuse the multi-scale information. Experiments conducted on SOD and LMD datasets show that our model improves both quantitative and qualitative performance compared to models based on single-scale information. The source code and some generated samples can be found at https://github.com/HaRry-qaq/MSAT.