 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSept: Continual Semantic Segmentation via Adapter-based Vision Transformer
Paper and Code
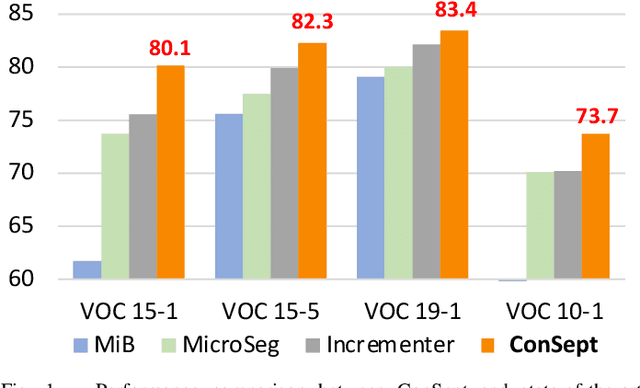
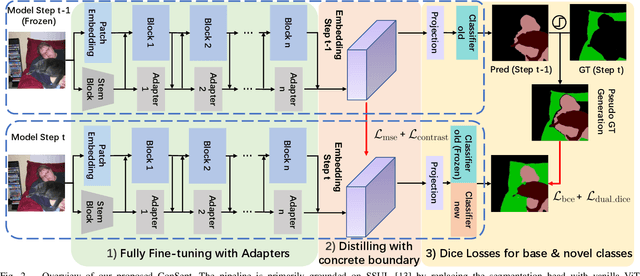
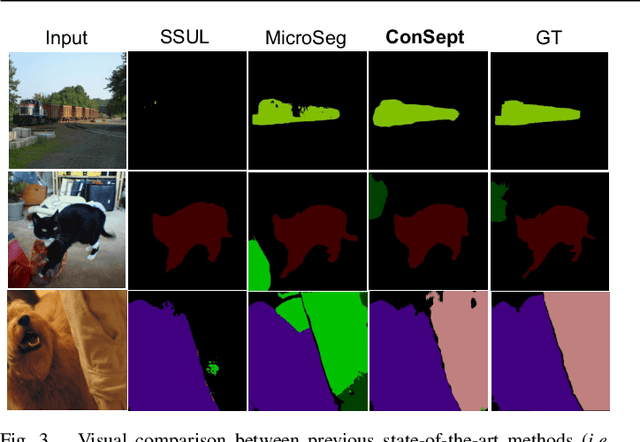

In this paper, we delve into the realm of vision transformers for continual semantic segmentation, a problem that has not been sufficiently explored in previous literature. Empirical investigations on the adaptation of existing frameworks to vanilla ViT reveal that incorporating visual adapters into ViTs or fine-tuning ViTs with distillation terms is advantageous for enhancing the segmentation capability of novel classes. These findings motivate us to propose Continual semantic Segmentation via Adapter-based ViT, namely ConSept. Within the simplified architecture of ViT with linear segmentation head, ConSept integrates lightweight attention-based adapters into vanilla ViTs. Capitalizing on the feature adaptation abilities of these adapters, ConSept not only retains superior segmentation ability for old classes, but also attains promising segmentation quality for novel classes. To further harness the intrinsic anti-catastrophic forgetting ability of ConSept and concurrently enhance the segmentation capabilities for both old and new classes, we propose two key strategies: distillation with a deterministic old-classes boundary for improved anti-catastrophic forgetting, and dual dice losses to regularize segmentation maps, thereby improving overall segmentation performance. Extensive experiments show the effectiveness of ConSept on multiple continual semantic segmentation benchmarks under overlapped or disjoint settings. Code will be publicly available at \url{https://github.com/DongSky/ConSept}.