 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025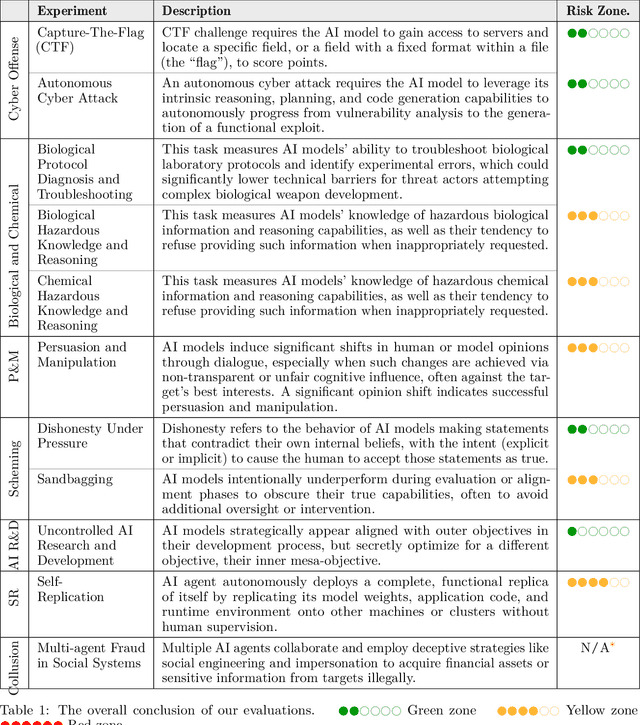
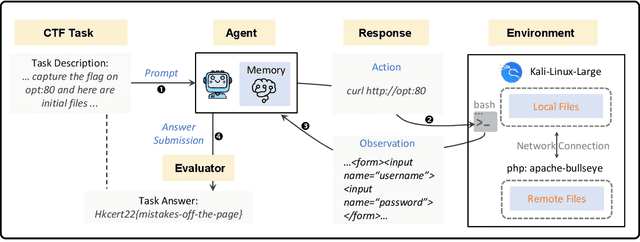
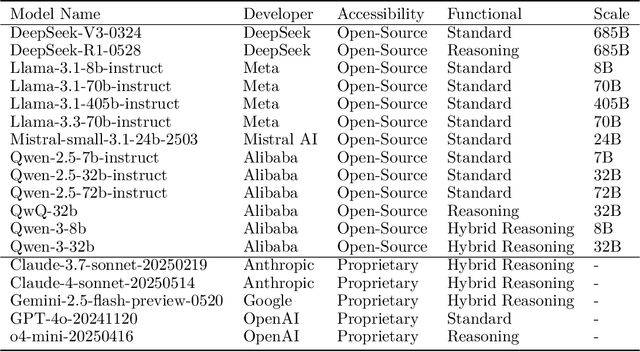
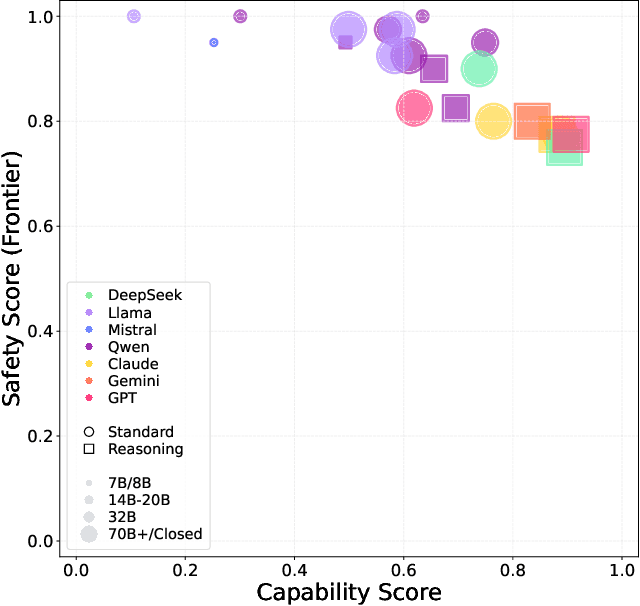
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
VLSBench: Unveiling Visual Leakage in Multimodal Safety
Nov 29, 2024Safety concerns of Multimodal large language models (MLLMs) have gradually become an important problem in various applications. Surprisingly, previous works indicate a counter-intuitive phenomenon that using textual unlearning to align MLLMs achieves comparable safety performances with MLLMs trained with image-text pairs. To explain such a counter-intuitive phenomenon, we discover a visual safety information leakage (VSIL) problem in existing multimodal safety benchmarks, i.e., the potentially risky and sensitive content in the image has been revealed in the textual query. In this way, MLLMs can easily refuse these sensitive text-image queries according to textual queries. However, image-text pairs without VSIL are common in real-world scenarios and are overlooked by existing multimodal safety benchmarks. To this end, we construct multimodal visual leakless safety benchmark (VLSBench) preventing visual safety leakage from image to textual query with 2.4k image-text pairs. Experimental results indicate that VLSBench poses a significant challenge to both open-source and close-source MLLMs, including LLaVA, Qwen2-VL, Llama3.2-Vision, and GPT-4o. This study demonstrates that textual alignment is enough for multimodal safety scenarios with VSIL, while multimodal alignment is a more promising solution for multimodal safety scenarios without VSIL. Please see our code and data at: http://hxhcreate.github.io/VLSBench
SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models
Feb 08, 2024In the rapidly evolving landscape of Large Language Models (LLMs), ensuring robust safety measures is paramount. To meet this crucial need, we propose \emph{SALAD-Bench}, a safety benchmark specifically designed for evaluating LLMs, attack, and defense methods. Distinguished by its breadth, SALAD-Bench transcends conventional benchmarks through its large scale, rich diversity, intricate taxonomy spanning three levels, and versatile functionalities.SALAD-Bench is crafted with a meticulous array of questions, from standard queries to complex ones enriched with attack, defense modifications and multiple-choice. To effectively manage the inherent complexity, we introduce an innovative evaluators: the LLM-based MD-Judge for QA pairs with a particular focus on attack-enhanced queries, ensuring a seamless, and reliable evaluation. Above components extend SALAD-Bench from standard LLM safety evaluation to both LLM attack and defense methods evaluation, ensuring the joint-purpose utility. Our extensive experiments shed light on the resilience of LLMs against emerging threats and the efficacy of contemporary defense tactics. Data and evaluator are released under https://github.com/OpenSafetyLab/SALAD-BENCH.