 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Distillation for Semantic Segmentation
Paper and Code
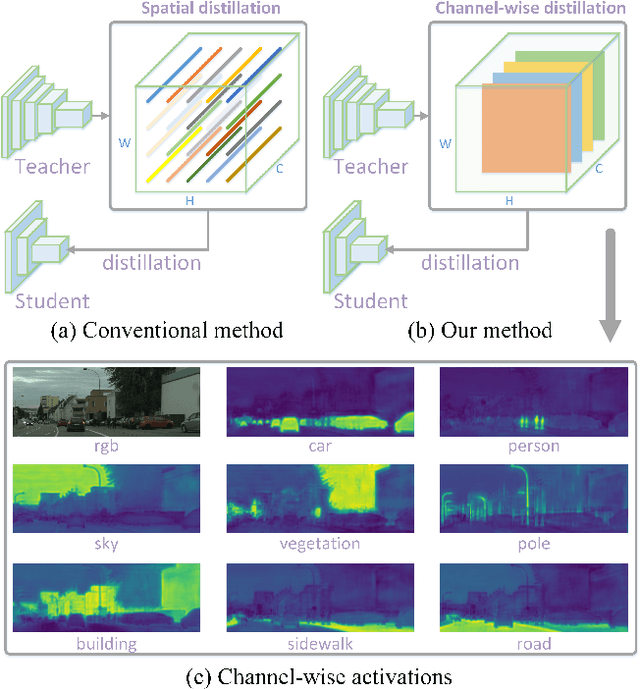

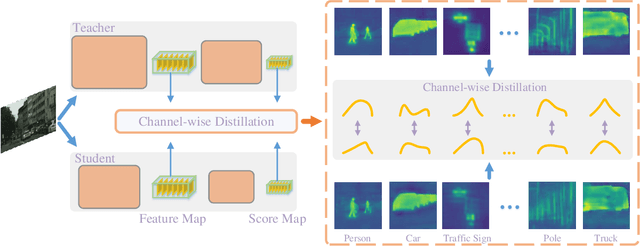
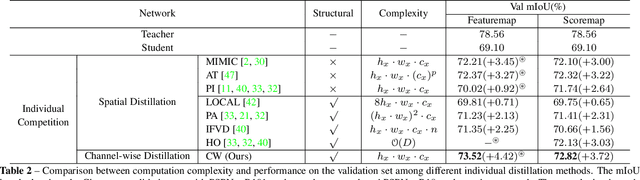
Knowledge distillation (KD) has been proven to be a simple and effective tool for training compact models. Almost all KD variants for semantic segmentation align the student and teacher networks' feature maps in the spatial domain, typically by minimizing point-wise and/or pair-wise discrepancy. Observing that in semantic segmentation, some layers' feature activations of each channel tend to encode saliency of scene categories (analogue to class activation mapping), we propose to align features channel-wise between the student and teacher networks. To this end, we first transform the feature map of each channel into a distribution using softmax normalization, and then minimize the Kullback-Leibler (KL) divergence of the corresponding channels of the two networks. By doing so, our method focuses on mimicking the soft distributions of channels between networks. In particular, the KL divergence enables learning to pay more attention to the most salient regions of the channel-wise maps, presumably corresponding to the most useful signals for semantic segmentation. Experiments demonstrate that our channel-wise distillation outperforms almost all existing spatial distillation methods for semantic segmentation considerably, and requires less computational cost during training. We consistently achieve superior performance on three benchmarks with various network structures. Code is available at: https://git.io/ChannelDis