 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent In-context Coordination via Decentralized Memory Retrieval
Nov 13, 2025



Large transformer models, trained on diverse datasets, have demonstrated impressive few-shot performance on previously unseen tasks without requiring parameter updates. This capability has also been explored in Reinforcement Learning (RL), where agents interact with the environment to retrieve context and maximize cumulative rewards, showcasing strong adaptability in complex settings. However, in cooperative Multi-Agent Reinforcement Learning (MARL), where agents must coordinate toward a shared goal, decentralized policy deployment can lead to mismatches in task alignment and reward assignment, limiting the efficiency of policy adaptation. To address this challenge, we introduce Multi-agent In-context Coordination via Decentralized Memory Retrieval (MAICC), a novel approach designed to enhance coordination by fast adaptation. Our method involves training a centralized embedding model to capture fine-grained trajectory representations, followed by decentralized models that approximate the centralized one to obtain team-level task information. Based on the learned embeddings, relevant trajectories are retrieved as context, which, combined with the agents' current sub-trajectories, inform decision-making. During decentralized execution, we introduce a novel memory mechanism that effectively balances test-time online data with offline memory. Based on the constructed memory, we propose a hybrid utility score that incorporates both individual- and team-level returns, ensuring credit assignment across agents. Extensive experiments on cooperative MARL benchmarks, including Level-Based Foraging (LBF) and SMAC (v1/v2), show that MAICC enables faster adaptation to unseen tasks compared to existing methods. Code is available at https://github.com/LAMDA-RL/MAICC.
DM$^3$Net: Dual-Camera Super-Resolution via Domain Modulation and Multi-scale Matching
Jun 08, 2025Dual-camera super-resolution is highly practical for smartphone photography that primarily super-resolve the wide-angle images using the telephoto image as a reference. In this paper, we propose DM$^3$Net, a novel dual-camera super-resolution network based on Domain Modulation and Multi-scale Matching. To bridge the domain gap between the high-resolution domain and the degraded domain, we learn two compressed global representations from image pairs corresponding to the two domains. To enable reliable transfer of high-frequency structural details from the reference image, we design a multi-scale matching module that conducts patch-level feature matching and retrieval across multiple receptive fields to improve matching accuracy and robustness. Moreover, we also introduce Key Pruning to achieve a significant reduction in memory usage and inference time with little model performance sacrificed. Experimental results on three real-world datasets demonstrate that our DM$^3$Net outperforms the state-of-the-art approaches.
Stable Continual Reinforcement Learning via Diffusion-based Trajectory Replay
Nov 16, 2024



Given the inherent non-stationarity prevalent in real-world applications, continual Reinforcement Learning (RL) aims to equip the agent with the capability to address a series of sequentially presented decision-making tasks. Within this problem setting, a pivotal challenge revolves around \textit{catastrophic forgetting} issue, wherein the agent is prone to effortlessly erode the decisional knowledge associated with past encountered tasks when learning the new one. In recent progresses, the \textit{generative replay} methods have showcased substantial potential by employing generative models to replay data distribution of past tasks. Compared to storing the data from past tasks directly, this category of methods circumvents the growing storage overhead and possible data privacy concerns. However, constrained by the expressive capacity of generative models, existing \textit{generative replay} methods face challenges in faithfully reconstructing the data distribution of past tasks, particularly in scenarios with a myriad of tasks or high-dimensional data. Inspired by the success of diffusion models in various generative tasks, this paper introduces a novel continual RL algorithm DISTR (Diffusion-based Trajectory Replay) that employs a diffusion model to memorize the high-return trajectory distribution of each encountered task and wakeups these distributions during the policy learning on new tasks. Besides, considering the impracticality of replaying all past data each time, a prioritization mechanism is proposed to prioritize the trajectory replay of pivotal tasks in our method. Empirical experiments on the popular continual RL benchmark \texttt{Continual World} demonstrate that our proposed method obtains a favorable balance between \textit{stability} and \textit{plasticity}, surpassing various existing continual RL baselines in average success rate.
Quality-Diversity with Limited Resources
Jun 06, 2024Quality-Diversity (QD) algorithms have emerged as a powerful optimization paradigm with the aim of generating a set of high-quality and diverse solutions. To achieve such a challenging goal, QD algorithms require maintaining a large archive and a large population in each iteration, which brings two main issues, sample and resource efficiency. Most advanced QD algorithms focus on improving the sample efficiency, while the resource efficiency is overlooked to some extent. Particularly, the resource overhead during the training process has not been touched yet, hindering the wider application of QD algorithms. In this paper, we highlight this important research question, i.e., how to efficiently train QD algorithms with limited resources, and propose a novel and effective method called RefQD to address it. RefQD decomposes a neural network into representation and decision parts, and shares the representation part with all decision parts in the archive to reduce the resource overhead. It also employs a series of strategies to address the mismatch issue between the old decision parts and the newly updated representation part. Experiments on different types of tasks from small to large resource consumption demonstrate the excellent performance of RefQD: it not only uses significantly fewer resources (e.g., 16\% GPU memories on QDax and 3.7\% on Atari) but also achieves comparable or better performance compared to sample-efficient QD algorithms. Our code is available at \url{https://github.com/lamda-bbo/RefQD}.
Efficient Human-AI Coordination via Preparatory Language-based Convention
Nov 01, 2023



Developing intelligent agents capable of seamless coordination with humans is a critical step towards achieving artificial general intelligence. Existing methods for human-AI coordination typically train an agent to coordinate with a diverse set of policies or with human models fitted from real human data. However, the massively diverse styles of human behavior present obstacles for AI systems with constrained capacity, while high quality human data may not be readily available in real-world scenarios. In this study, we observe that prior to coordination, humans engage in communication to establish conventions that specify individual roles and actions, making their coordination proceed in an orderly manner. Building upon this observation, we propose employing the large language model (LLM) to develop an action plan (or equivalently, a convention) that effectively guides both human and AI. By inputting task requirements, human preferences, the number of agents, and other pertinent information into the LLM, it can generate a comprehensive convention that facilitates a clear understanding of tasks and responsibilities for all parties involved. Furthermore, we demonstrate that decomposing the convention formulation problem into sub-problems with multiple new sessions being sequentially employed and human feedback, will yield a more efficient coordination convention. Experimental evaluations conducted in the Overcooked-AI environment, utilizing a human proxy model, highlight the superior performance of our proposed method compared to existing learning-based approaches. When coordinating with real humans, our method achieves better alignment with human preferences and an average performance improvement of 15% compared to the state-of-the-art.
Robust multi-agent coordination via evolutionary generation of auxiliary adversarial attackers
May 10, 2023



Cooperative multi-agent reinforcement learning (CMARL) has shown to be promising for many real-world applications. Previous works mainly focus on improving coordination ability via solving MARL-specific challenges (e.g., non-stationarity, credit assignment, scalability), but ignore the policy perturbation issue when testing in a different environment. This issue hasn't been considered in problem formulation or efficient algorithm design. To address this issue, we firstly model the problem as a limited policy adversary Dec-POMDP (LPA-Dec-POMDP), where some coordinators from a team might accidentally and unpredictably encounter a limited number of malicious action attacks, but the regular coordinators still strive for the intended goal. Then, we propose Robust Multi-Agent Coordination via Evolutionary Generation of Auxiliary Adversarial Attackers (ROMANCE), which enables the trained policy to encounter diversified and strong auxiliary adversarial attacks during training, thus achieving high robustness under various policy perturbations. Concretely, to avoid the ego-system overfitting to a specific attacker, we maintain a set of attackers, which is optimized to guarantee the attackers high attacking quality and behavior diversity. The goal of quality is to minimize the ego-system coordination effect, and a novel diversity regularizer based on sparse action is applied to diversify the behaviors among attackers. The ego-system is then paired with a population of attackers selected from the maintained attacker set, and alternately trained against the constantly evolving attackers. Extensive experiments on multiple scenarios from SMAC indicate our ROMANCE provides comparable or better robustness and generalization ability than other baselines.
Multi-agent Continual Coordination via Progressive Task Contextualization
May 07, 2023Cooperative Multi-agent Reinforcement Learning (MARL) has attracted significant attention and played the potential for many real-world applications. Previous arts mainly focus on facilitating the coordination ability from different aspects (e.g., non-stationarity, credit assignment) in single-task or multi-task scenarios, ignoring the stream of tasks that appear in a continual manner. This ignorance makes the continual coordination an unexplored territory, neither in problem formulation nor efficient algorithms designed. Towards tackling the mentioned issue, this paper proposes an approach Multi-Agent Continual Coordination via Progressive Task Contextualization, dubbed MACPro. The key point lies in obtaining a factorized policy, using shared feature extraction layers but separated independent task heads, each specializing in a specific class of tasks. The task heads can be progressively expanded based on the learned task contextualization. Moreover, to cater to the popular CTDE paradigm in MARL, each agent learns to predict and adopt the most relevant policy head based on local information in a decentralized manner. We show in multiple multi-agent benchmarks that existing continual learning methods fail, while MACPro is able to achieve close-to-optimal performance. More results also disclose the effectiveness of MACPro from multiple aspects like high generalization ability.
Efficient Communication via Self-supervised Information Aggregation for Online and Offline Multi-agent Reinforcement Learning
Feb 19, 2023Utilizing messages from teammates can improve coordination in cooperative Multi-agent Reinforcement Learning (MARL). Previous works typically combine raw messages of teammates with local information as inputs for policy. However, neglecting message aggregation poses significant inefficiency for policy learning. Motivated by recent advances in representation learning, we argue that efficient message aggregation is essential for good coordination in cooperative MARL. In this paper, we propose Multi-Agent communication via Self-supervised Information Aggregation (MASIA), where agents can aggregate the received messages into compact representations with high relevance to augment the local policy. Specifically, we design a permutation invariant message encoder to generate common information-aggregated representation from messages and optimize it via reconstructing and shooting future information in a self-supervised manner. Hence, each agent would utilize the most relevant parts of the aggregated representation for decision-making by a novel message extraction mechanism. Furthermore, considering the potential of offline learning for real-world applications, we build offline benchmarks for multi-agent communication, which is the first as we know. Empirical results demonstrate the superiority of our method in both online and offline settings. We also release the built offline benchmarks in this paper as a testbed for communication ability validation to facilitate further future research.
Heterogeneous Multi-agent Zero-Shot Coordination by Coevolution
Aug 09, 2022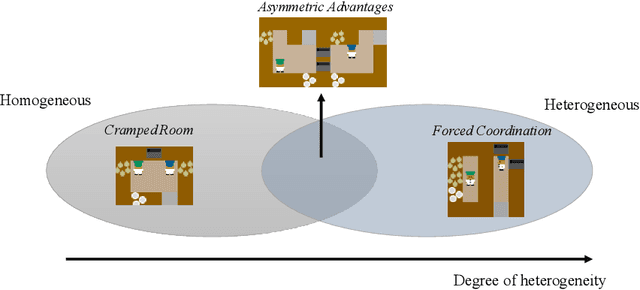
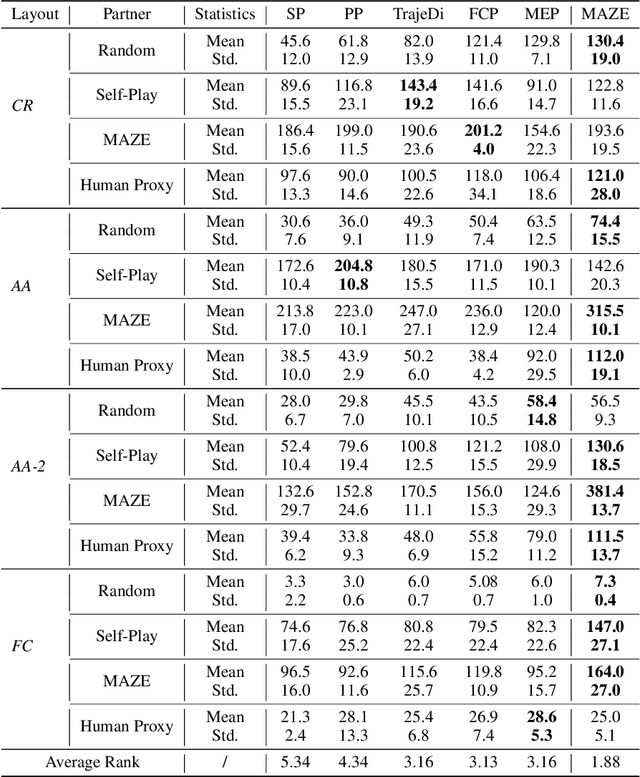

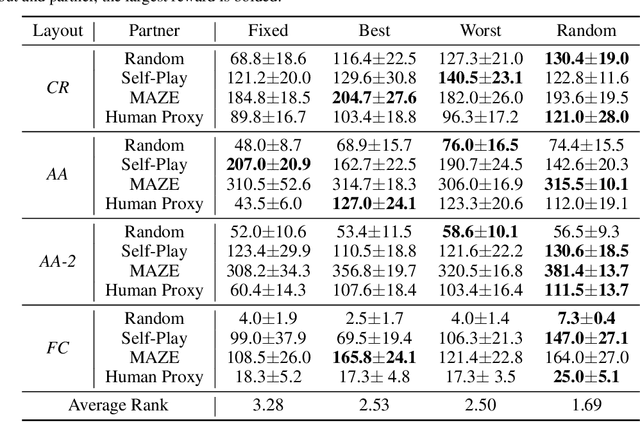
Generating agents that can achieve Zero-Shot Coordination (ZSC) with unseen partners is a new challenge in cooperative Multi-Agent Reinforcement Learning (MARL). Recently, some studies have made progress in ZSC by exposing the agents to diverse partners during the training process. They usually involve self-play when training the partners, implicitly assuming that the tasks are homogeneous. However, many real-world tasks are heterogeneous, and hence previous methods may fail. In this paper, we study the heterogeneous ZSC problem for the first time and propose a general method based on coevolution, which coevolves two populations of agents and partners through three sub-processes: pairing, updating and selection. Experimental results on a collaborative cooking task show the necessity of considering the heterogeneous setting and illustrate that our proposed method is a promising solution for heterogeneous cooperative MARL.