 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiMUS-0.3: Using Large Language Models to Model and Solve Optimization Problems at Scale
Jul 29, 2024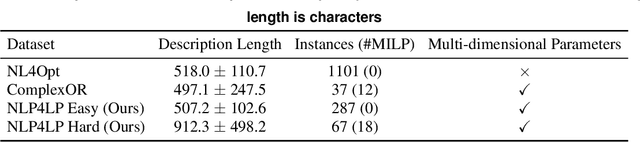
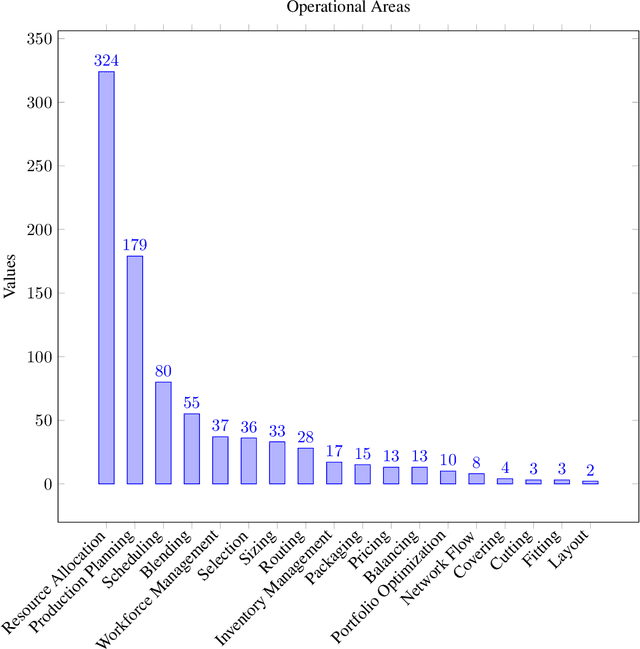
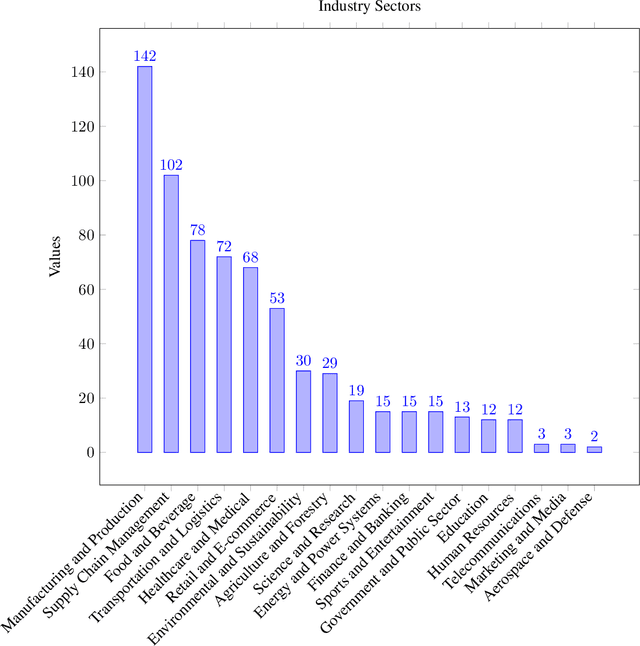
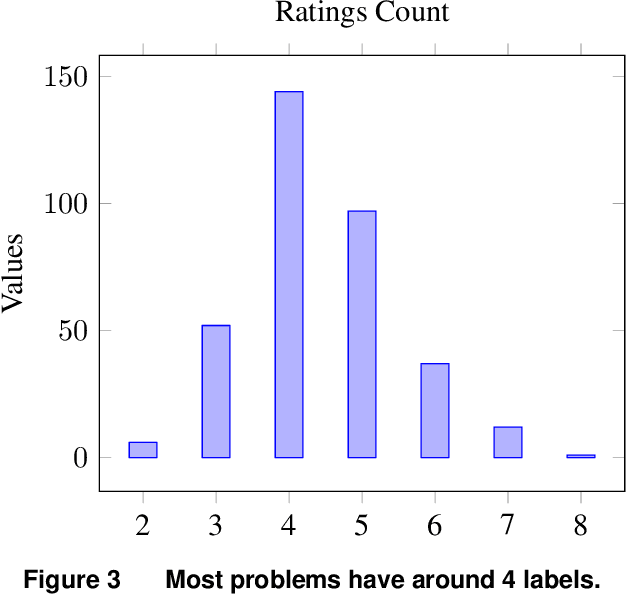
Optimization problems are pervasive in sectors from manufacturing and distribution to healthcare. However, most such problems are still solved heuristically by hand rather than optimally by state-of-the art solvers because the expertise required to formulate and solve these problems limits the widespread adoption of optimization tools and techniques. We introduce a Large Language Model (LLM)-based system designed to formulate and solve (mixed integer) linear programming problems from their natural language descriptions. Our system is capable of developing mathematical models, writing and debugging solver code, evaluating the generated solutions, and improving efficiency and correctness of its model and code based on these evaluations. OptiMUS-0.3 utilizes a modular structure to process problems, allowing it to handle problems with long descriptions and complex data without long prompts. Experiments demonstrate that OptiMUS-0.3 outperforms existing state-of-the-art methods on easy datasets by more than 12% and on hard datasets (including a new dataset, NLP4LP, released with this paper that features long and complex problems) by more than 8%.
LABOR-LLM: Language-Based Occupational Representations with Large Language Models
Jun 25, 2024Many empirical studies of labor market questions rely on estimating relatively simple predictive models using small, carefully constructed longitudinal survey datasets based on hand-engineered features. Large Language Models (LLMs), trained on massive datasets, encode vast quantities of world knowledge and can be used for the next job prediction problem. However, while an off-the-shelf LLM produces plausible career trajectories when prompted, the probability with which an LLM predicts a particular job transition conditional on career history will not, in general, align with the true conditional probability in a given population. Recently, Vafa et al. (2024) introduced a transformer-based "foundation model", CAREER, trained using a large, unrepresentative resume dataset, that predicts transitions between jobs; it further demonstrated how transfer learning techniques can be used to leverage the foundation model to build better predictive models of both transitions and wages that reflect conditional transition probabilities found in nationally representative survey datasets. This paper considers an alternative where the fine-tuning of the CAREER foundation model is replaced by fine-tuning LLMs. For the task of next job prediction, we demonstrate that models trained with our approach outperform several alternatives in terms of predictive performance on the survey data, including traditional econometric models, CAREER, and LLMs with in-context learning, even though the LLM can in principle predict job titles that are not allowed in the survey data. Further, we show that our fine-tuned LLM-based models' predictions are more representative of the career trajectories of various workforce subpopulations than off-the-shelf LLM models and CAREER. We conduct experiments and analyses that highlight the sources of the gains in the performance of our models for representative predictions.