 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLABOR-LLM: Language-Based Occupational Representations with Large Language Models
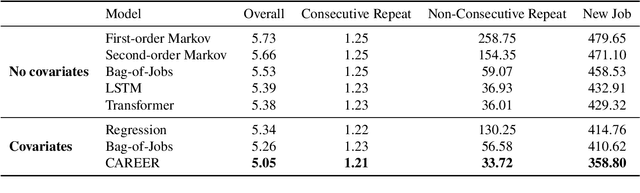
Jun 25, 2024Many empirical studies of labor market questions rely on estimating relatively simple predictive models using small, carefully constructed longitudinal survey datasets based on hand-engineered features. Large Language Models (LLMs), trained on massive datasets, encode vast quantities of world knowledge and can be used for the next job prediction problem. However, while an off-the-shelf LLM produces plausible career trajectories when prompted, the probability with which an LLM predicts a particular job transition conditional on career history will not, in general, align with the true conditional probability in a given population. Recently, Vafa et al. (2024) introduced a transformer-based "foundation model", CAREER, trained using a large, unrepresentative resume dataset, that predicts transitions between jobs; it further demonstrated how transfer learning techniques can be used to leverage the foundation model to build better predictive models of both transitions and wages that reflect conditional transition probabilities found in nationally representative survey datasets. This paper considers an alternative where the fine-tuning of the CAREER foundation model is replaced by fine-tuning LLMs. For the task of next job prediction, we demonstrate that models trained with our approach outperform several alternatives in terms of predictive performance on the survey data, including traditional econometric models, CAREER, and LLMs with in-context learning, even though the LLM can in principle predict job titles that are not allowed in the survey data. Further, we show that our fine-tuned LLM-based models' predictions are more representative of the career trajectories of various workforce subpopulations than off-the-shelf LLM models and CAREER. We conduct experiments and analyses that highlight the sources of the gains in the performance of our models for representative predictions.
Torch-Choice: A PyTorch Package for Large-Scale Choice Modelling with Python
Apr 04, 2023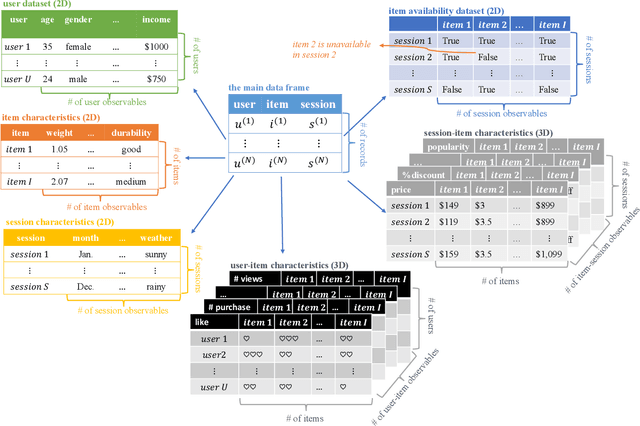

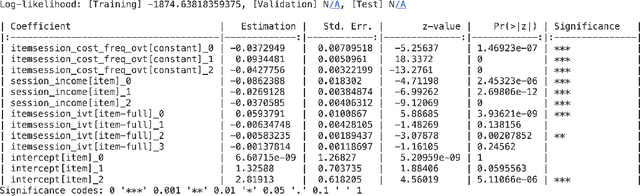
The $\texttt{torch-choice}$ is an open-source library for flexible, fast choice modeling with Python and PyTorch. $\texttt{torch-choice}$ provides a $\texttt{ChoiceDataset}$ data structure to manage databases flexibly and memory-efficiently. The paper demonstrates constructing a $\texttt{ChoiceDataset}$ from databases of various formats and functionalities of $\texttt{ChoiceDataset}$. The package implements two widely used models, namely the multinomial logit and nested logit models, and supports regularization during model estimation. The package incorporates the option to take advantage of GPUs for estimation, allowing it to scale to massive datasets while being computationally efficient. Models can be initialized using either R-style formula strings or Python dictionaries. We conclude with a comparison of the computational efficiencies of $\texttt{torch-choice}$ and $\texttt{mlogit}$ in R as (1) the number of observations increases, (2) the number of covariates increases, and (3) the expansion of item sets. Finally, we demonstrate the scalability of $\texttt{torch-choice}$ on large-scale datasets.
Learning Transferrable Representations of Career Trajectories for Economic Prediction
Mar 10, 2022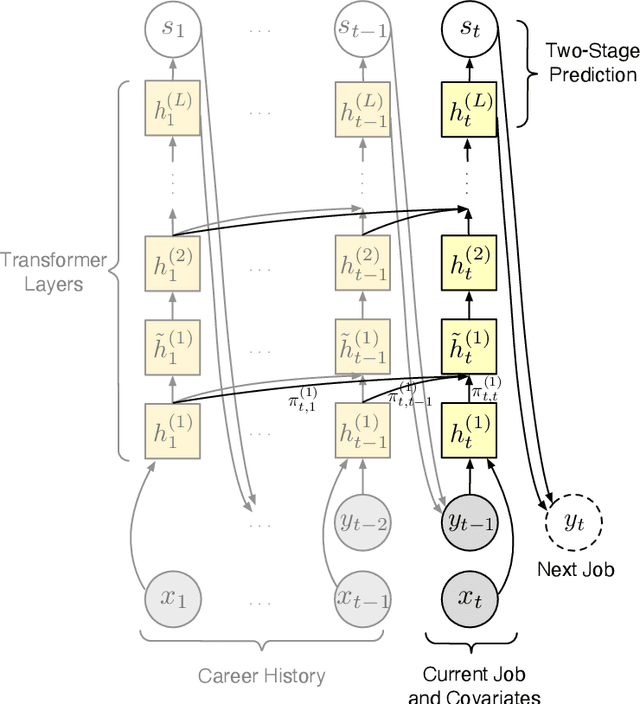

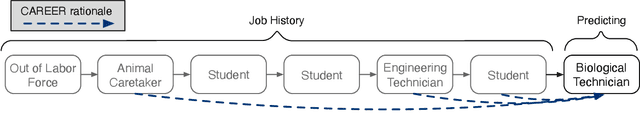
Understanding career trajectories -- the sequences of jobs that individuals hold over their working lives -- is important to economists for studying labor markets. In the past, economists have estimated relevant quantities by fitting predictive models to small surveys, but in recent years large datasets of online resumes have also become available. These new datasets provide job sequences of many more individuals, but they are too large and complex for standard econometric modeling. To this end, we adapt ideas from modern language modeling to the analysis of large-scale job sequence data. We develop CAREER, a transformer-based model that learns a low-dimensional representation of an individual's job history. This representation can be used to predict jobs directly on a large dataset, or can be "transferred" to represent jobs in smaller and better-curated datasets. We fit the model to a large dataset of resumes, 24 million people who are involved in more than a thousand unique occupations. It forms accurate predictions on held-out data, and it learns useful career representations that can be fine-tuned to make accurate predictions on common economics datasets.
Qualitative Analysis of POMDPs with Temporal Logic Specifications for Robotics Applications
Feb 18, 2015
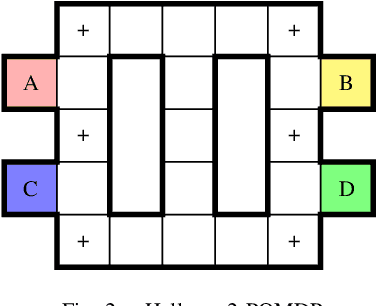
We consider partially observable Markov decision processes (POMDPs), that are a standard framework for robotics applications to model uncertainties present in the real world, with temporal logic specifications. All temporal logic specifications in linear-time temporal logic (LTL) can be expressed as parity objectives. We study the qualitative analysis problem for POMDPs with parity objectives that asks whether there is a controller (policy) to ensure that the objective holds with probability 1 (almost-surely). While the qualitative analysis of POMDPs with parity objectives is undecidable, recent results show that when restricted to finite-memory policies the problem is EXPTIME-complete. While the problem is intractable in theory, we present a practical approach to solve the qualitative analysis problem. We designed several heuristics to deal with the exponential complexity, and have used our implementation on a number of well-known POMDP examples for robotics applications. Our results provide the first practical approach to solve the qualitative analysis of robot motion planning with LTL properties in the presence of uncertainty.
Optimal Cost Almost-sure Reachability in POMDPs
Nov 14, 2014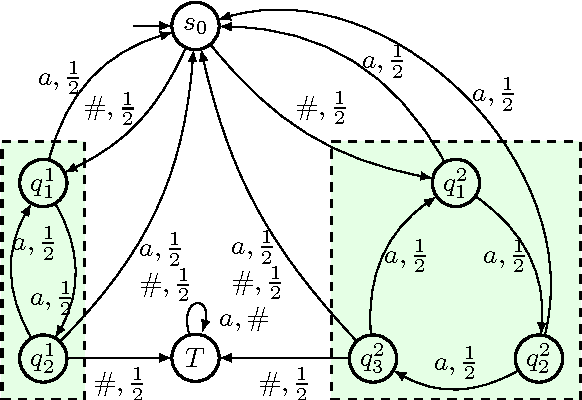
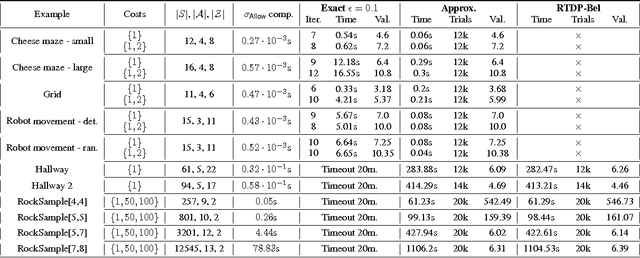
We consider partially observable Markov decision processes (POMDPs) with a set of target states and every transition is associated with an integer cost. The optimization objective we study asks to minimize the expected total cost till the target set is reached, while ensuring that the target set is reached almost-surely (with probability 1). We show that for integer costs approximating the optimal cost is undecidable. For positive costs, our results are as follows: (i) we establish matching lower and upper bounds for the optimal cost and the bound is double exponential; (ii) we show that the problem of approximating the optimal cost is decidable and present approximation algorithms developing on the existing algorithms for POMDPs with finite-horizon objectives. While the worst-case running time of our algorithm is double exponential, we also present efficient stopping criteria for the algorithm and show experimentally that it performs well in many examples of interest.