 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTCBench: Can Vision-Language Models Understand Long Context with Vision-Text Compression?
Dec 23, 2025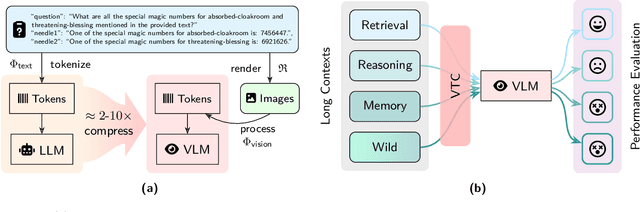

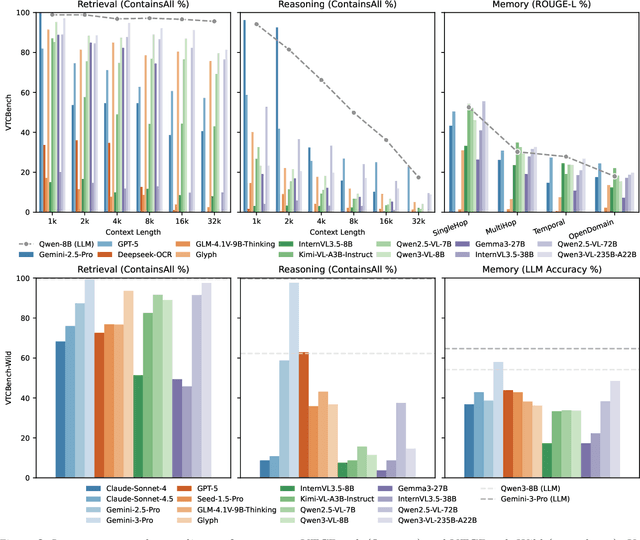
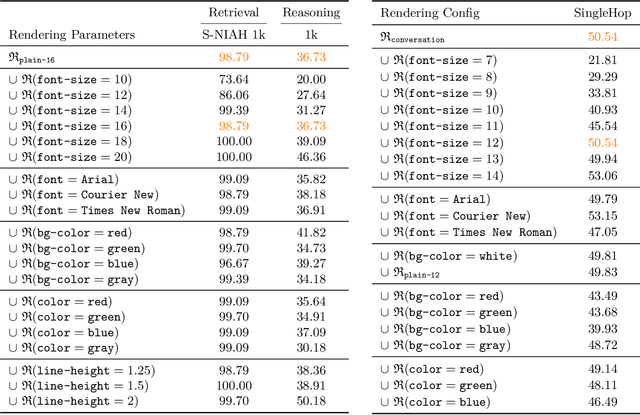
The computational and memory overheads associated with expanding the context window of LLMs severely limit their scalability. A noteworthy solution is vision-text compression (VTC), exemplified by frameworks like DeepSeek-OCR and Glyph, which convert long texts into dense 2D visual representations, thereby achieving token compression ratios of 3x-20x. However, the impact of this high information density on the core long-context capabilities of vision-language models (VLMs) remains under-investigated. To address this gap, we introduce the first benchmark for VTC and systematically assess the performance of VLMs across three long-context understanding settings: VTC-Retrieval, which evaluates the model's ability to retrieve and aggregate information; VTC-Reasoning, which requires models to infer latent associations to locate facts with minimal lexical overlap; and VTC-Memory, which measures comprehensive question answering within long-term dialogue memory. Furthermore, we establish the VTCBench-Wild to simulate diverse input scenarios.We comprehensively evaluate leading open-source and proprietary models on our benchmarks. The results indicate that, despite being able to decode textual information (e.g., OCR) well, most VLMs exhibit a surprisingly poor long-context understanding ability with VTC-processed information, failing to capture long associations or dependencies in the context.This study provides a deep understanding of VTC and serves as a foundation for designing more efficient and scalable VLMs.
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.
Token Transforming: A Unified and Training-Free Token Compression Framework for Vision Transformer Acceleration
Jun 06, 2025Vision transformers have been widely explored in various vision tasks. Due to heavy computational cost, much interest has aroused for compressing vision transformer dynamically in the aspect of tokens. Current methods mainly pay attention to token pruning or merging to reduce token numbers, in which tokens are compressed exclusively, causing great information loss and therefore post-training is inevitably required to recover the performance. In this paper, we rethink token reduction and unify the process as an explicit form of token matrix transformation, in which all existing methods are constructing special forms of matrices within the framework. Furthermore, we propose a many-to-many Token Transforming framework that serves as a generalization of all existing methods and reserves the most information, even enabling training-free acceleration. We conduct extensive experiments to validate our framework. Specifically, we reduce 40% FLOPs and accelerate DeiT-S by $\times$1.5 with marginal 0.1% accuracy drop. Furthermore, we extend the method to dense prediction tasks including segmentation, object detection, depth estimation, and language model generation. Results demonstrate that the proposed method consistently achieves substantial improvements, offering a better computation-performance trade-off, impressive budget reduction and inference acceleration.
Token Reduction Should Go Beyond Efficiency in Generative Models -- From Vision, Language to Multimodality
May 23, 2025In Transformer architectures, tokens\textemdash discrete units derived from raw data\textemdash are formed by segmenting inputs into fixed-length chunks. Each token is then mapped to an embedding, enabling parallel attention computations while preserving the input's essential information. Due to the quadratic computational complexity of transformer self-attention mechanisms, token reduction has primarily been used as an efficiency strategy. This is especially true in single vision and language domains, where it helps balance computational costs, memory usage, and inference latency. Despite these advances, this paper argues that token reduction should transcend its traditional efficiency-oriented role in the era of large generative models. Instead, we position it as a fundamental principle in generative modeling, critically influencing both model architecture and broader applications. Specifically, we contend that across vision, language, and multimodal systems, token reduction can: (i) facilitate deeper multimodal integration and alignment, (ii) mitigate "overthinking" and hallucinations, (iii) maintain coherence over long inputs, and (iv) enhance training stability, etc. We reframe token reduction as more than an efficiency measure. By doing so, we outline promising future directions, including algorithm design, reinforcement learning-guided token reduction, token optimization for in-context learning, and broader ML and scientific domains. We highlight its potential to drive new model architectures and learning strategies that improve robustness, increase interpretability, and better align with the objectives of generative modeling.
ChartEdit: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs' Capability via Chart Editing
May 17, 2025Although multimodal large language models (MLLMs) show promise in generating chart rendering code, chart editing presents a greater challenge. This difficulty stems from its nature as a labor-intensive task for humans that also demands MLLMs to integrate chart understanding, complex reasoning, and precise intent interpretation. While many MLLMs claim such editing capabilities, current assessments typically rely on limited case studies rather than robust evaluation methodologies, highlighting the urgent need for a comprehensive evaluation framework. In this work, we propose ChartEdit, a new high-quality benchmark designed for chart editing tasks. This benchmark comprises $1,405$ diverse editing instructions applied to $233$ real-world charts, with each instruction-chart instance having been manually annotated and validated for accuracy. Utilizing ChartEdit, we evaluate the performance of 10 mainstream MLLMs across two types of experiments, assessing them at both the code and chart levels. The results suggest that large-scale models can generate code to produce images that partially match the reference images. However, their ability to generate accurate edits according to the instructions remains limited. The state-of-the-art (SOTA) model achieves a score of only $59.96$, highlighting significant challenges in precise modification. In contrast, small-scale models, including chart-domain models, struggle both with following editing instructions and generating overall chart images, underscoring the need for further development in this area. Code is available at https://github.com/xxlllz/ChartEdit.
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Apr 17, 2025Video Anomaly Detection~(VAD) focuses on identifying anomalies within videos. Supervised methods require an amount of in-domain training data and often struggle to generalize to unseen anomalies. In contrast, training-free methods leverage the intrinsic world knowledge of large language models (LLMs) to detect anomalies but face challenges in localizing fine-grained visual transitions and diverse events. Therefore, we propose EventVAD, an event-aware video anomaly detection framework that combines tailored dynamic graph architectures and multimodal LLMs through temporal-event reasoning. Specifically, EventVAD first employs dynamic spatiotemporal graph modeling with time-decay constraints to capture event-aware video features. Then, it performs adaptive noise filtering and uses signal ratio thresholding to detect event boundaries via unsupervised statistical features. The statistical boundary detection module reduces the complexity of processing long videos for MLLMs and improves their temporal reasoning through event consistency. Finally, it utilizes a hierarchical prompting strategy to guide MLLMs in performing reasoning before determining final decisions. We conducted extensive experiments on the UCF-Crime and XD-Violence datasets. The results demonstrate that EventVAD with a 7B MLLM achieves state-of-the-art (SOTA) in training-free settings, outperforming strong baselines that use 7B or larger MLLMs.
Towards Efficient and General-Purpose Few-Shot Misclassification Detection for Vision-Language Models
Mar 26, 2025Reliable prediction by classifiers is crucial for their deployment in high security and dynamically changing situations. However, modern neural networks often exhibit overconfidence for misclassified predictions, highlighting the need for confidence estimation to detect errors. Despite the achievements obtained by existing methods on small-scale datasets, they all require training from scratch and there are no efficient and effective misclassification detection (MisD) methods, hindering practical application towards large-scale and ever-changing datasets. In this paper, we pave the way to exploit vision language model (VLM) leveraging text information to establish an efficient and general-purpose misclassification detection framework. By harnessing the power of VLM, we construct FSMisD, a Few-Shot prompt learning framework for MisD to refrain from training from scratch and therefore improve tuning efficiency. To enhance misclassification detection ability, we use adaptive pseudo sample generation and a novel negative loss to mitigate the issue of overconfidence by pushing category prompts away from pseudo features. We conduct comprehensive experiments with prompt learning methods and validate the generalization ability across various datasets with domain shift. Significant and consistent improvement demonstrates the effectiveness, efficiency and generalizability of our approach.
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Mar 17, 2025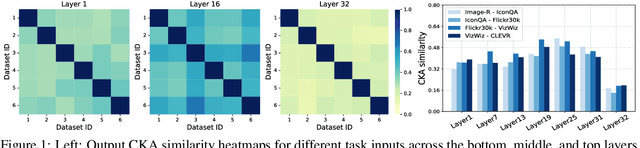
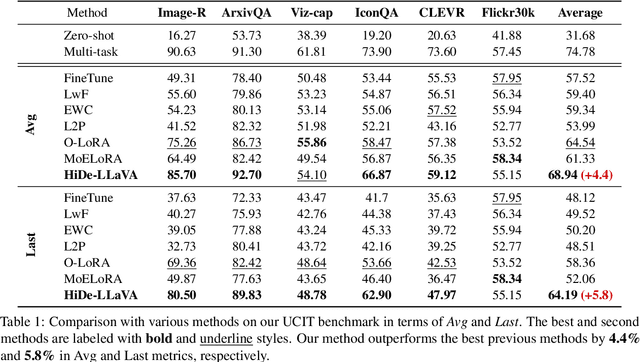
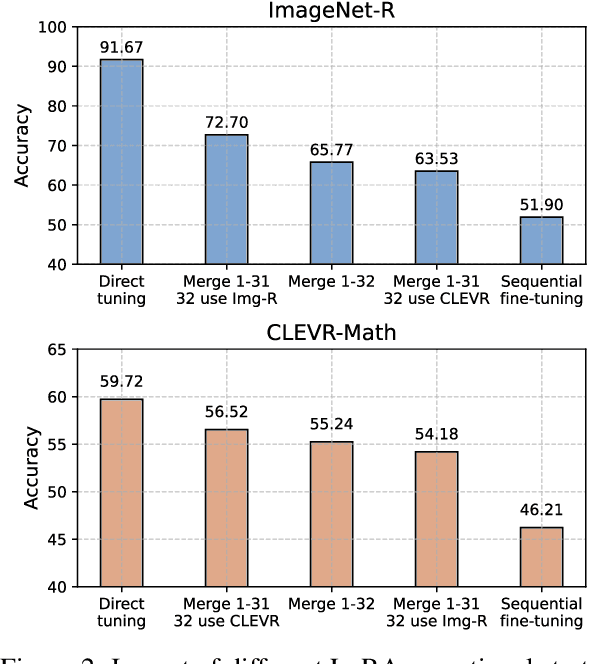
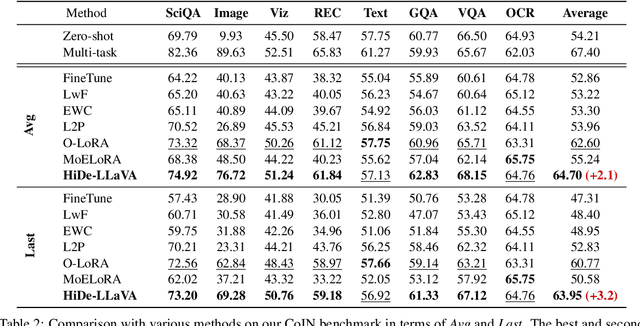
Instruction tuning is widely used to improve a pre-trained Multimodal Large Language Model (MLLM) by training it on curated task-specific datasets, enabling better comprehension of human instructions. However, it is infeasible to collect all possible instruction datasets simultaneously in real-world scenarios. Thus, enabling MLLM with continual instruction tuning is essential for maintaining their adaptability. However, existing methods often trade off memory efficiency for performance gains, significantly compromising overall efficiency. In this paper, we propose a task-specific expansion and task-general fusion framework based on the variations in Centered Kernel Alignment (CKA) similarity across different model layers when trained on diverse datasets. Furthermore, we analyze the information leakage present in the existing benchmark and propose a new and more challenging benchmark to rationally evaluate the performance of different methods. Comprehensive experiments showcase a significant performance improvement of our method compared to existing state-of-the-art methods. Our code will be public available.
Federated Continual Instruction Tuning
Mar 17, 2025A vast amount of instruction tuning data is crucial for the impressive performance of Large Multimodal Models (LMMs), but the associated computational costs and data collection demands during supervised fine-tuning make it impractical for most researchers. Federated learning (FL) has the potential to leverage all distributed data and training resources to reduce the overhead of joint training. However, most existing methods assume a fixed number of tasks, while in real-world scenarios, clients continuously encounter new knowledge and often struggle to retain old tasks due to memory constraints. In this work, we introduce the Federated Continual Instruction Tuning (FCIT) benchmark to model this real-world challenge. Our benchmark includes two realistic scenarios, encompassing four different settings and twelve carefully curated instruction tuning datasets. To address the challenges posed by FCIT, we propose dynamic knowledge organization to effectively integrate updates from different tasks during training and subspace selective activation to allocate task-specific output during inference. Extensive experimental results demonstrate that our proposed method significantly enhances model performance across varying levels of data heterogeneity and catastrophic forgetting. Our source code and dataset will be made publicly available.