 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
StyMam: A Mamba-Based Generator for Artistic Style Transfer
Jan 19, 2026Image style transfer aims to integrate the visual patterns of a specific artistic style into a content image while preserving its content structure. Existing methods mainly rely on the generative adversarial network (GAN) or stable diffusion (SD). GAN-based approaches using CNNs or Transformers struggle to jointly capture local and global dependencies, leading to artifacts and disharmonious patterns. SD-based methods reduce such issues but often fail to preserve content structures and suffer from slow inference. To address these issues, we revisit GAN and propose a mamba-based generator, termed as StyMam, to produce high-quality stylized images without introducing artifacts and disharmonious patterns. Specifically, we introduce a mamba-based generator with a residual dual-path strip scanning mechanism and a channel-reweighted spatial attention module. The former efficiently captures local texture features, while the latter models global dependencies. Finally, extensive qualitative and quantitative experiments demonstrate that the proposed method outperforms state-of-the-art algorithms in both quality and speed.
Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
AutoPP: Towards Automated Product Poster Generation and Optimization
Dec 26, 2025Product posters blend striking visuals with informative text to highlight the product and capture customer attention. However, crafting appealing posters and manually optimizing them based on online performance is laborious and resource-consuming. To address this, we introduce AutoPP, an automated pipeline for product poster generation and optimization that eliminates the need for human intervention. Specifically, the generator, relying solely on basic product information, first uses a unified design module to integrate the three key elements of a poster (background, text, and layout) into a cohesive output. Then, an element rendering module encodes these elements into condition tokens, efficiently and controllably generating the product poster. Based on the generated poster, the optimizer enhances its Click-Through Rate (CTR) by leveraging online feedback. It systematically replaces elements to gather fine-grained CTR comparisons and utilizes Isolated Direct Preference Optimization (IDPO) to attribute CTR gains to isolated elements. Our work is supported by AutoPP1M, the largest dataset specifically designed for product poster generation and optimization, which contains one million high-quality posters and feedback collected from over one million users. Experiments demonstrate that AutoPP achieves state-of-the-art results in both offline and online settings. Our code and dataset are publicly available at: https://github.com/JD-GenX/AutoPP
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
Lay2Story: Extending Diffusion Transformers for Layout-Togglable Story Generation
Aug 12, 2025Storytelling tasks involving generating consistent subjects have gained significant attention recently. However, existing methods, whether training-free or training-based, continue to face challenges in maintaining subject consistency due to the lack of fine-grained guidance and inter-frame interaction. Additionally, the scarcity of high-quality data in this field makes it difficult to precisely control storytelling tasks, including the subject's position, appearance, clothing, expression, and posture, thereby hindering further advancements. In this paper, we demonstrate that layout conditions, such as the subject's position and detailed attributes, effectively facilitate fine-grained interactions between frames. This not only strengthens the consistency of the generated frame sequence but also allows for precise control over the subject's position, appearance, and other key details. Building on this, we introduce an advanced storytelling task: Layout-Togglable Storytelling, which enables precise subject control by incorporating layout conditions. To address the lack of high-quality datasets with layout annotations for this task, we develop Lay2Story-1M, which contains over 1 million 720p and higher-resolution images, processed from approximately 11,300 hours of cartoon videos. Building on Lay2Story-1M, we create Lay2Story-Bench, a benchmark with 3,000 prompts designed to evaluate the performance of different methods on this task. Furthermore, we propose Lay2Story, a robust framework based on the Diffusion Transformers (DiTs) architecture for Layout-Togglable Storytelling tasks. Through both qualitative and quantitative experiments, we find that our method outperforms the previous state-of-the-art (SOTA) techniques, achieving the best results in terms of consistency, semantic correlation, and aesthetic quality.
ICM-Fusion: In-Context Meta-Optimized LoRA Fusion for Multi-Task Adaptation
Aug 06, 2025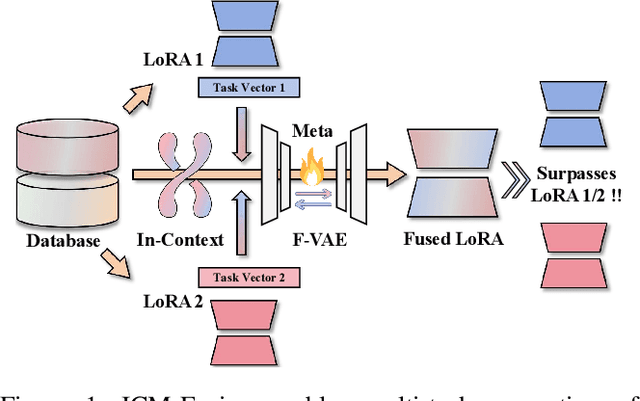
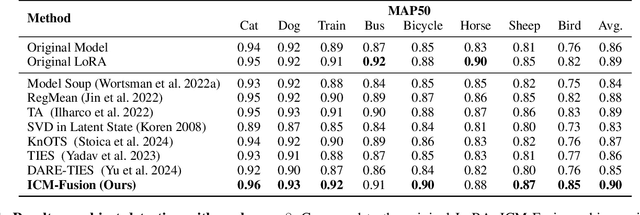
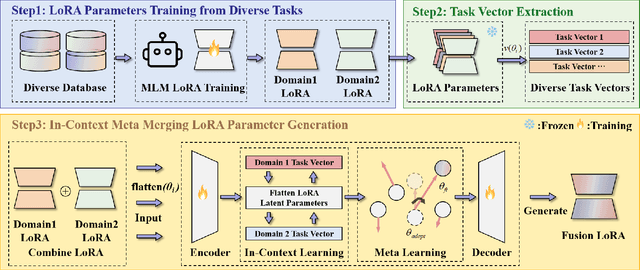
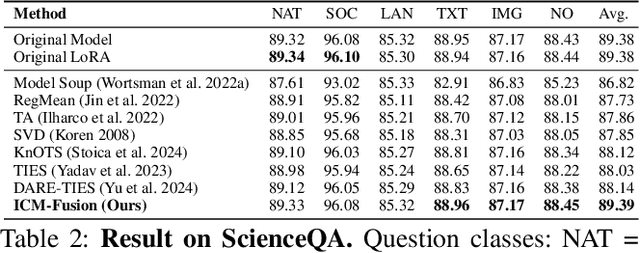
Enabling multi-task adaptation in pre-trained Low-Rank Adaptation (LoRA) models is crucial for enhancing their generalization capabilities. Most existing pre-trained LoRA fusion methods decompose weight matrices, sharing similar parameters while merging divergent ones. However, this paradigm inevitably induces inter-weight conflicts and leads to catastrophic domain forgetting. While incremental learning enables adaptation to multiple tasks, it struggles to achieve generalization in few-shot scenarios. Consequently, when the weight data follows a long-tailed distribution, it can lead to forgetting in the fused weights. To address this issue, we propose In-Context Meta LoRA Fusion (ICM-Fusion), a novel framework that synergizes meta-learning with in-context adaptation. The key innovation lies in our task vector arithmetic, which dynamically balances conflicting optimization directions across domains through learned manifold projections. ICM-Fusion obtains the optimal task vector orientation for the fused model in the latent space by adjusting the orientation of the task vectors. Subsequently, the fused LoRA is reconstructed by a self-designed Fusion VAE (F-VAE) to realize multi-task LoRA generation. We have conducted extensive experiments on visual and linguistic tasks, and the experimental results demonstrate that ICM-Fusion can be adapted to a wide range of architectural models and applied to various tasks. Compared to the current pre-trained LoRA fusion method, ICM-Fusion fused LoRA can significantly reduce the multi-tasking loss and can even achieve task enhancement in few-shot scenarios.
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Apr 17, 2025Video Anomaly Detection~(VAD) focuses on identifying anomalies within videos. Supervised methods require an amount of in-domain training data and often struggle to generalize to unseen anomalies. In contrast, training-free methods leverage the intrinsic world knowledge of large language models (LLMs) to detect anomalies but face challenges in localizing fine-grained visual transitions and diverse events. Therefore, we propose EventVAD, an event-aware video anomaly detection framework that combines tailored dynamic graph architectures and multimodal LLMs through temporal-event reasoning. Specifically, EventVAD first employs dynamic spatiotemporal graph modeling with time-decay constraints to capture event-aware video features. Then, it performs adaptive noise filtering and uses signal ratio thresholding to detect event boundaries via unsupervised statistical features. The statistical boundary detection module reduces the complexity of processing long videos for MLLMs and improves their temporal reasoning through event consistency. Finally, it utilizes a hierarchical prompting strategy to guide MLLMs in performing reasoning before determining final decisions. We conducted extensive experiments on the UCF-Crime and XD-Violence datasets. The results demonstrate that EventVAD with a 7B MLLM achieves state-of-the-art (SOTA) in training-free settings, outperforming strong baselines that use 7B or larger MLLMs.
PlanGen: Towards Unified Layout Planning and Image Generation in Auto-Regressive Vision Language Models
Mar 13, 2025In this paper, we propose a unified layout planning and image generation model, PlanGen, which can pre-plan spatial layout conditions before generating images. Unlike previous diffusion-based models that treat layout planning and layout-to-image as two separate models, PlanGen jointly models the two tasks into one autoregressive transformer using only next-token prediction. PlanGen integrates layout conditions into the model as context without requiring specialized encoding of local captions and bounding box coordinates, which provides significant advantages over the previous embed-and-pool operations on layout conditions, particularly when dealing with complex layouts. Unified prompting allows PlanGen to perform multitasking training related to layout, including layout planning, layout-to-image generation, image layout understanding, etc. In addition, PlanGen can be seamlessly expanded to layout-guided image manipulation thanks to the well-designed modeling, with teacher-forcing content manipulation policy and negative layout guidance. Extensive experiments verify the effectiveness of our PlanGen in multiple layoutrelated tasks, showing its great potential. Code is available at: https://360cvgroup.github.io/PlanGen.