 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-VISTA: Benchmarking Continual Learning in Video Large Language Models
Apr 01, 2026Video Large Language Models (Video-LLMs) require continual learning to adapt to non-stationary real-world data. However, existing benchmarks fall short of evaluating modern foundation models: many still rely on models without large-scale pre-training, and prevailing benchmarks typically partition a single dataset into sub-tasks, resulting in high task redundancy and negligible forgetting on pre-trained Video-LLMs. To address these limitations, we propose CL-VISTA, a benchmark tailored for continual video understanding of Video-LLMs. By curating 8 diverse tasks spanning perception, understanding, and reasoning, CL-VISTA induces substantial distribution shifts that effectively expose catastrophic forgetting. To systematically assess CL methods, we establish a comprehensive evaluation framework comprising 6 distinct protocols across 3 critical dimensions: performance, computational efficiency, and memory footprint. Notably, the performance dimension incorporates a general video understanding assessment to assess whether CL methods genuinely enhance foundational intelligence or merely induce task-specific overfitting. Extensive benchmarking of 10 mainstream CL methods reveals a fundamental trade-off: no single approach achieves universal superiority across all dimensions. Methods that successfully mitigate catastrophic forgetting tend to compromise generalization or incur prohibitive computational and memory overheads. We hope CL-VISTA provides critical insights for advancing continual learning in multimodal foundation models.
Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective
Jan 28, 2026Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the \textbf{Repeat Curse}. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model's growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present \textbf{CoTA}, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code is available at https://github.com/ErikZ719/CoTA
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Mar 17, 2025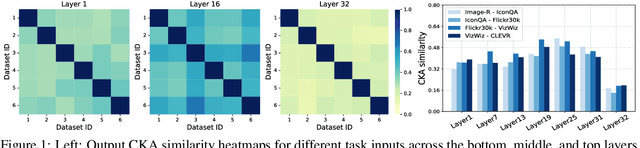
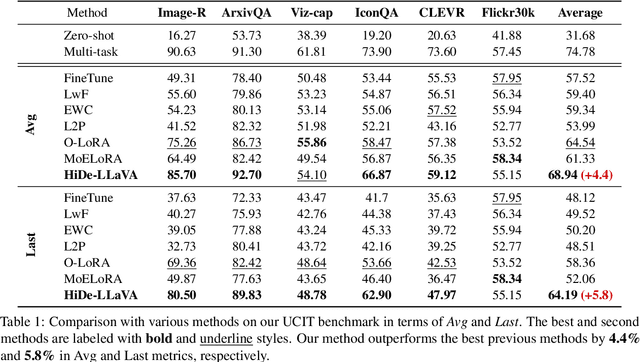
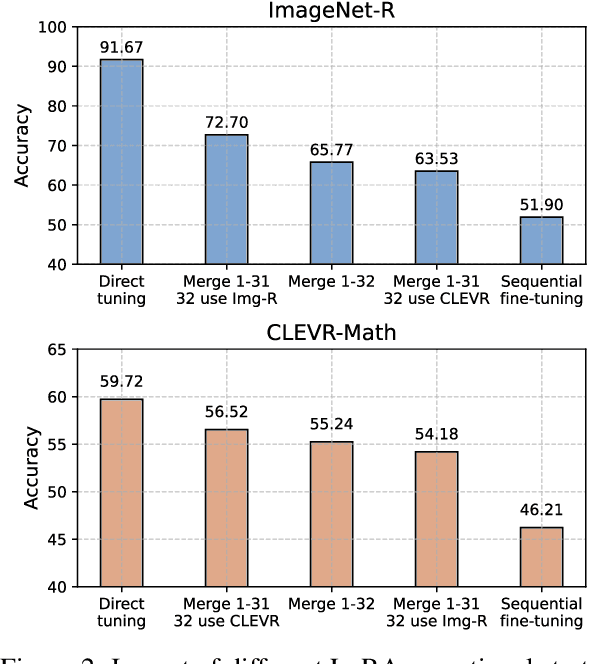
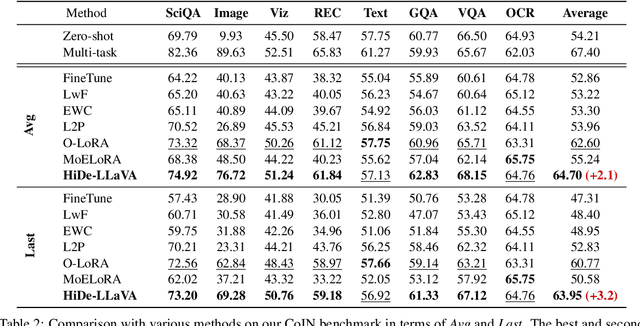
Instruction tuning is widely used to improve a pre-trained Multimodal Large Language Model (MLLM) by training it on curated task-specific datasets, enabling better comprehension of human instructions. However, it is infeasible to collect all possible instruction datasets simultaneously in real-world scenarios. Thus, enabling MLLM with continual instruction tuning is essential for maintaining their adaptability. However, existing methods often trade off memory efficiency for performance gains, significantly compromising overall efficiency. In this paper, we propose a task-specific expansion and task-general fusion framework based on the variations in Centered Kernel Alignment (CKA) similarity across different model layers when trained on diverse datasets. Furthermore, we analyze the information leakage present in the existing benchmark and propose a new and more challenging benchmark to rationally evaluate the performance of different methods. Comprehensive experiments showcase a significant performance improvement of our method compared to existing state-of-the-art methods. Our code will be public available.
Federated Continual Instruction Tuning
Mar 17, 2025A vast amount of instruction tuning data is crucial for the impressive performance of Large Multimodal Models (LMMs), but the associated computational costs and data collection demands during supervised fine-tuning make it impractical for most researchers. Federated learning (FL) has the potential to leverage all distributed data and training resources to reduce the overhead of joint training. However, most existing methods assume a fixed number of tasks, while in real-world scenarios, clients continuously encounter new knowledge and often struggle to retain old tasks due to memory constraints. In this work, we introduce the Federated Continual Instruction Tuning (FCIT) benchmark to model this real-world challenge. Our benchmark includes two realistic scenarios, encompassing four different settings and twelve carefully curated instruction tuning datasets. To address the challenges posed by FCIT, we propose dynamic knowledge organization to effectively integrate updates from different tasks during training and subspace selective activation to allocate task-specific output during inference. Extensive experimental results demonstrate that our proposed method significantly enhances model performance across varying levels of data heterogeneity and catastrophic forgetting. Our source code and dataset will be made publicly available.
High-Order Structure Based Middle-Feature Learning for Visible-Infrared Person Re-Identification
Dec 14, 2023Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same persons captured by visible (VIS) and infrared (IR) cameras. Existing VI-ReID methods ignore high-order structure information of features while being relatively difficult to learn a reasonable common feature space due to the large modality discrepancy between VIS and IR images. To address the above problems, we propose a novel high-order structure based middle-feature learning network (HOS-Net) for effective VI-ReID. Specifically, we first leverage a short- and long-range feature extraction (SLE) module to effectively exploit both short-range and long-range features. Then, we propose a high-order structure learning (HSL) module to successfully model the high-order relationship across different local features of each person image based on a whitened hypergraph network.This greatly alleviates model collapse and enhances feature representations. Finally, we develop a common feature space learning (CFL) module to learn a discriminative and reasonable common feature space based on middle features generated by aligning features from different modalities and ranges. In particular, a modality-range identity-center contrastive (MRIC) loss is proposed to reduce the distances between the VIS, IR, and middle features, smoothing the training process. Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets show that our HOS-Net achieves superior state-of-the-art performance. Our code is available at \url{https://github.com/Jaulaucoeng/HOS-Net}.
Stain-Adaptive Self-Supervised Learning for Histopathology Image Analysis
Aug 08, 2022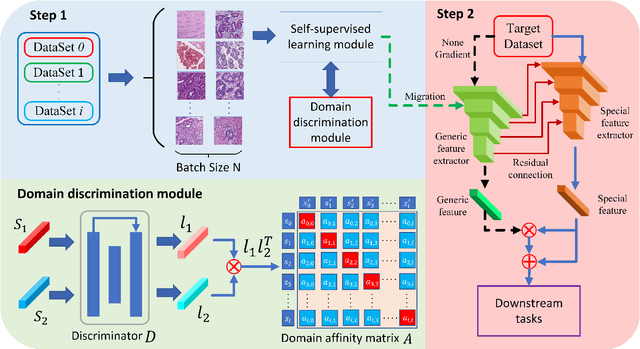

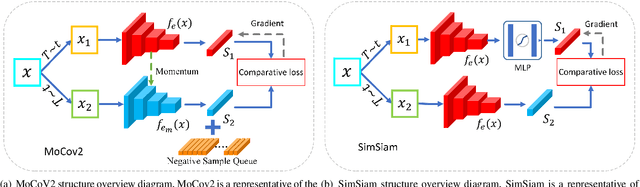

It is commonly recognized that color variations caused by differences in stains is a critical issue for histopathology image analysis. Existing methods adopt color matching, stain separation, stain transfer or the combination of them to alleviate the stain variation problem. In this paper, we propose a novel Stain-Adaptive Self-Supervised Learning(SASSL) method for histopathology image analysis. Our SASSL integrates a domain-adversarial training module into the SSL framework to learn distinctive features that are robust to both various transformations and stain variations. The proposed SASSL is regarded as a general method for domain-invariant feature extraction which can be flexibly combined with arbitrary downstream histopathology image analysis modules (e.g. nuclei/tissue segmentation) by fine-tuning the features for specific downstream tasks. We conducted experiments on publicly available pathological image analysis datasets including the PANDA, BreastPathQ, and CAMELYON16 datasets, achieving the state-of-the-art performance. Experimental results demonstrate that the proposed method can robustly improve the feature extraction ability of the model, and achieve stable performance improvement in downstream tasks.
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021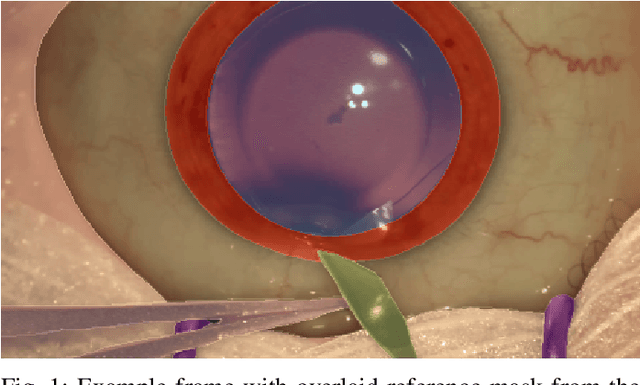
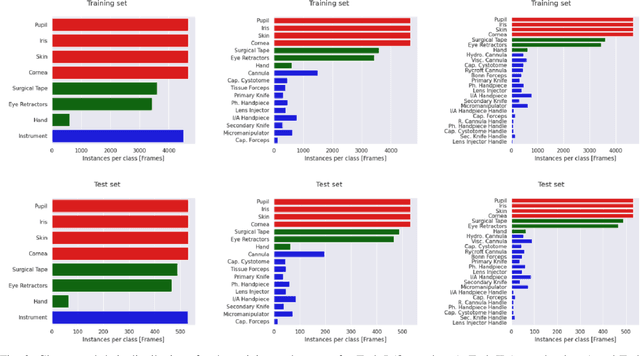
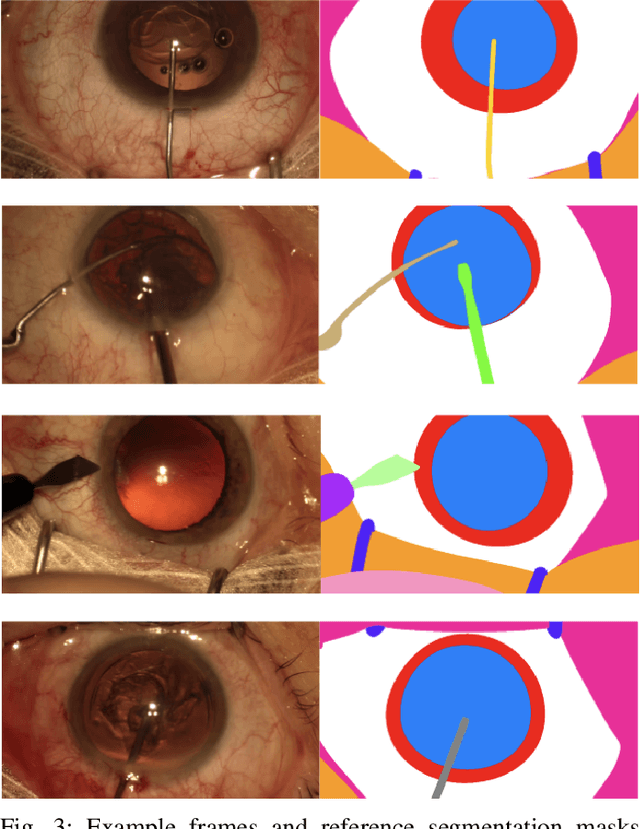
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.
Pretrained Generalized Autoregressive Model with Adaptive Probabilistic Label Clusters for Extreme Multi-label Text Classification
Jul 05, 2020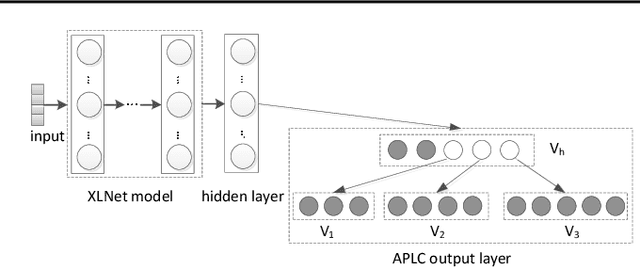
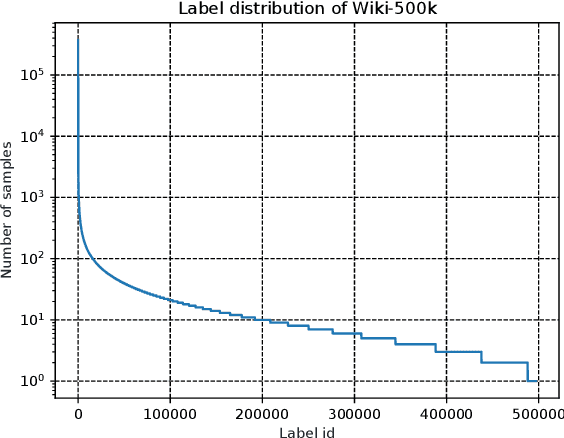
Extreme multi-label text classification (XMTC) is a task for tagging a given text with the most relevant labels from an extremely large label set. We propose a novel deep learning method called APLC-XLNet. Our approach fine-tunes the recently released generalized autoregressive pretrained model (XLNet) to learn a dense representation for the input text. We propose Adaptive Probabilistic Label Clusters (APLC) to approximate the cross entropy loss by exploiting the unbalanced label distribution to form clusters that explicitly reduce the computational time. Our experiments, carried out on five benchmark datasets, show that our approach significantly outperforms existing state-of-the-art methods. Our source code is available publicly at https://github.com/huiyegit/APLC_XLNet.
Robust Scene Text Recognition Using Sparse Coding based Features
Dec 29, 2015

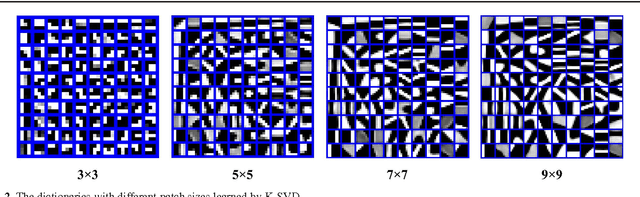
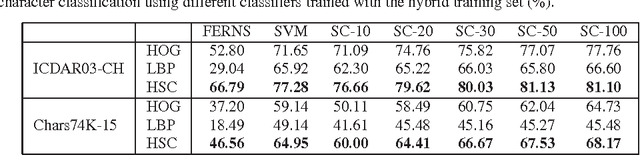
In this paper, we propose an effective scene text recognition method using sparse coding based features, called Histograms of Sparse Codes (HSC) features. For character detection, we use the HSC features instead of using the Histograms of Oriented Gradients (HOG) features. The HSC features are extracted by computing sparse codes with dictionaries that are learned from data using K-SVD, and aggregating per-pixel sparse codes to form local histograms. For word recognition, we integrate multiple cues including character detection scores and geometric contexts in an objective function. The final recognition results are obtained by searching for the words which correspond to the maximum value of the objective function. The parameters in the objective function are learned using the Minimum Classification Error (MCE) training method. Experiments on several challenging datasets demonstrate that the proposed HSC-based scene text recognition method outperforms HOG-based methods significantly and outperforms most state-of-the-art methods.