 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitting Reinforcement Learning Model to Behavioral Data under Bandits
Nov 06, 2025
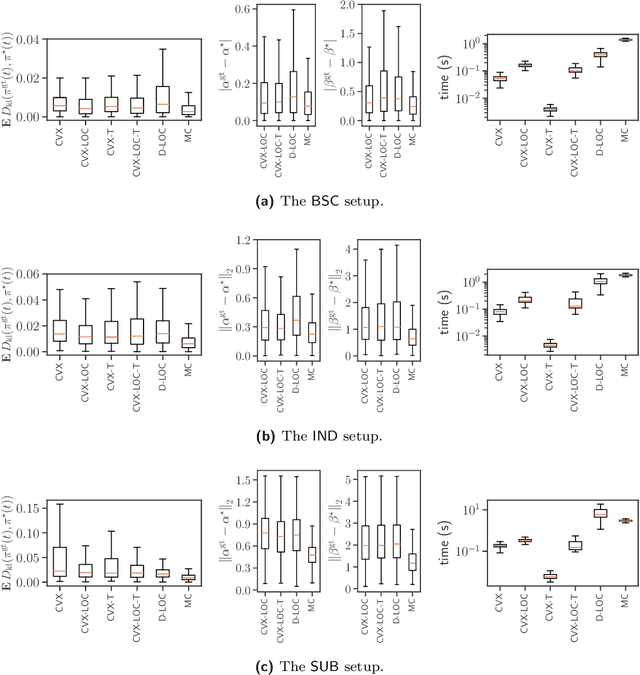

We consider the problem of fitting a reinforcement learning (RL) model to some given behavioral data under a multi-armed bandit environment. These models have received much attention in recent years for characterizing human and animal decision making behavior. We provide a generic mathematical optimization problem formulation for the fitting problem of a wide range of RL models that appear frequently in scientific research applications, followed by a detailed theoretical analysis of its convexity properties. Based on the theoretical results, we introduce a novel solution method for the fitting problem of RL models based on convex relaxation and optimization. Our method is then evaluated in several simulated bandit environments to compare with some benchmark methods that appear in the literature. Numerical results indicate that our method achieves comparable performance to the state-of-the-art, while significantly reducing computation time. We also provide an open-source Python package for our proposed method to empower researchers to apply it in the analysis of their datasets directly, without prior knowledge of convex optimization.
Constrained Reinforcement Learning for Safe Heat Pump Control
Sep 29, 2024



Constrained Reinforcement Learning (RL) has emerged as a significant research area within RL, where integrating constraints with rewards is crucial for enhancing safety and performance across diverse control tasks. In the context of heating systems in the buildings, optimizing the energy efficiency while maintaining the residents' thermal comfort can be intuitively formulated as a constrained optimization problem. However, to solve it with RL may require large amount of data. Therefore, an accurate and versatile simulator is favored. In this paper, we propose a novel building simulator I4B which provides interfaces for different usages and apply a model-free constrained RL algorithm named constrained Soft Actor-Critic with Linear Smoothed Log Barrier function (CSAC-LB) to the heating optimization problem. Benchmarking against baseline algorithms demonstrates CSAC-LB's efficiency in data exploration, constraint satisfaction and performance.
Revisiting Safe Exploration in Safe Reinforcement learning
Sep 02, 2024



Safe reinforcement learning (SafeRL) extends standard reinforcement learning with the idea of safety, where safety is typically defined through the constraint of the expected cost return of a trajectory being below a set limit. However, this metric fails to distinguish how costs accrue, treating infrequent severe cost events as equal to frequent mild ones, which can lead to riskier behaviors and result in unsafe exploration. We introduce a new metric, expected maximum consecutive cost steps (EMCC), which addresses safety during training by assessing the severity of unsafe steps based on their consecutive occurrence. This metric is particularly effective for distinguishing between prolonged and occasional safety violations. We apply EMMC in both on- and off-policy algorithm for benchmarking their safe exploration capability. Finally, we validate our metric through a set of benchmarks and propose a new lightweight benchmark task, which allows fast evaluation for algorithm design.
Constrained Reinforcement Learning with Smoothed Log Barrier Function
Mar 21, 2024Reinforcement Learning (RL) has been widely applied to many control tasks and substantially improved the performances compared to conventional control methods in many domains where the reward function is well defined. However, for many real-world problems, it is often more convenient to formulate optimization problems in terms of rewards and constraints simultaneously. Optimizing such constrained problems via reward shaping can be difficult as it requires tedious manual tuning of reward functions with several interacting terms. Recent formulations which include constraints mostly require a pre-training phase, which often needs human expertise to collect data or assumes having a sub-optimal policy readily available. We propose a new constrained RL method called CSAC-LB (Constrained Soft Actor-Critic with Log Barrier Function), which achieves competitive performance without any pre-training by applying a linear smoothed log barrier function to an additional safety critic. It implements an adaptive penalty for policy learning and alleviates the numerical issues that are known to complicate the application of the log barrier function method. As a result, we show that with CSAC-LB, we achieve state-of-the-art performance on several constrained control tasks with different levels of difficulty and evaluate our methods in a locomotion task on a real quadruped robot platform.
Geometric Regularity with Robot Intrinsic Symmetry in Reinforcement Learning
Jun 28, 2023
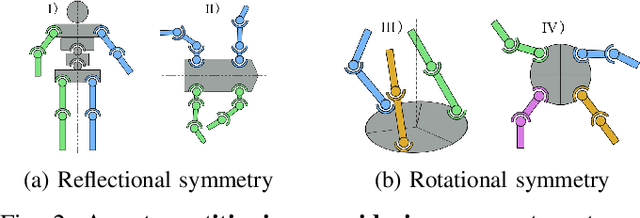
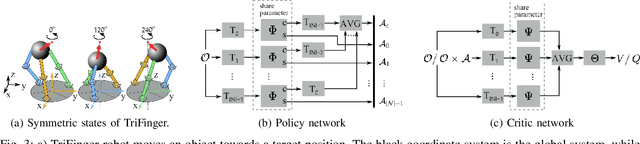

Geometric regularity, which leverages data symmetry, has been successfully incorporated into deep learning architectures such as CNNs, RNNs, GNNs, and Transformers. While this concept has been widely applied in robotics to address the curse of dimensionality when learning from high-dimensional data, the inherent reflectional and rotational symmetry of robot structures has not been adequately explored. Drawing inspiration from cooperative multi-agent reinforcement learning, we introduce novel network structures for deep learning algorithms that explicitly capture this geometric regularity. Moreover, we investigate the relationship between the geometric prior and the concept of Parameter Sharing in multi-agent reinforcement learning. Through experiments conducted on various challenging continuous control tasks, we demonstrate the significant potential of the proposed geometric regularity in enhancing robot learning capabilities.
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
Jan 11, 2022
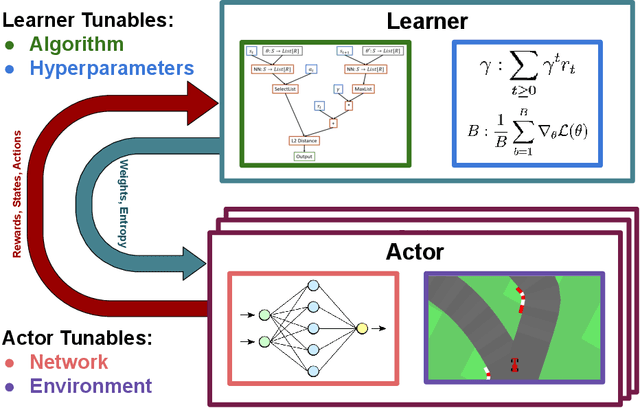
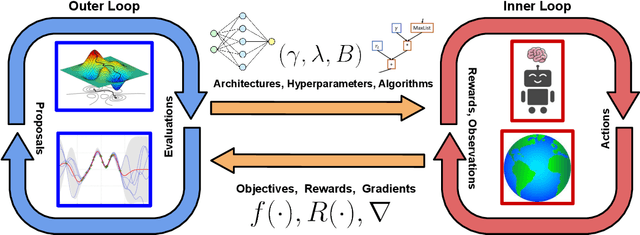

The combination of Reinforcement Learning (RL) with deep learning has led to a series of impressive feats, with many believing (deep) RL provides a path towards generally capable agents. However, the success of RL agents is often highly sensitive to design choices in the training process, which may require tedious and error-prone manual tuning. This makes it challenging to use RL for new problems, while also limits its full potential. In many other areas of machine learning, AutoML has shown it is possible to automate such design choices and has also yielded promising initial results when applied to RL. However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go. Given the diversity of methods and environments considered in RL, much of the research has been conducted in distinct subfields, ranging from meta-learning to evolution. In this survey we seek to unify the field of AutoRL, we provide a common taxonomy, discuss each area in detail and pose open problems which would be of interest to researchers going forward.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
Feb 26, 2021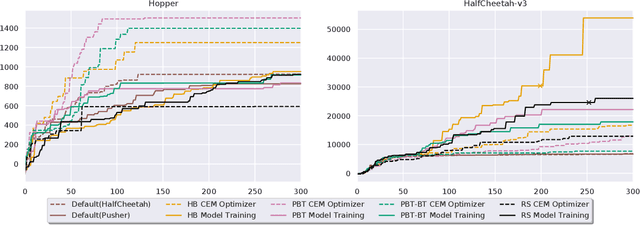
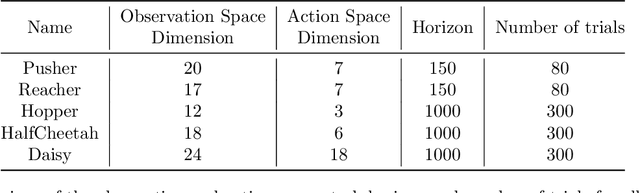
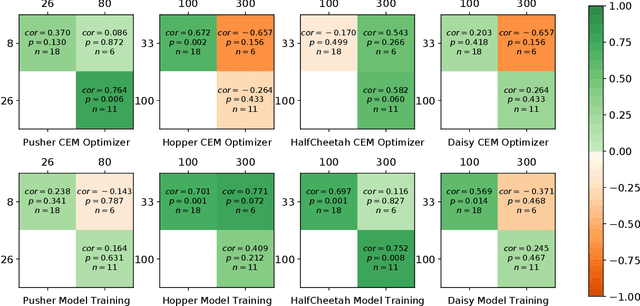
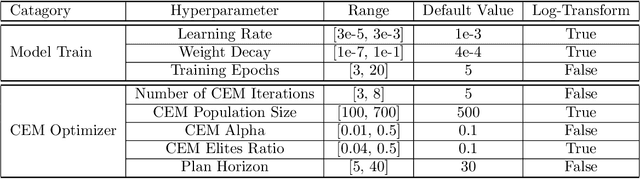
Model-based Reinforcement Learning (MBRL) is a promising framework for learning control in a data-efficient manner. MBRL algorithms can be fairly complex due to the separate dynamics modeling and the subsequent planning algorithm, and as a result, they often possess tens of hyperparameters and architectural choices. For this reason, MBRL typically requires significant human expertise before it can be applied to new problems and domains. To alleviate this problem, we propose to use automatic hyperparameter optimization (HPO). We demonstrate that this problem can be tackled effectively with automated HPO, which we demonstrate to yield significantly improved performance compared to human experts. In addition, we show that tuning of several MBRL hyperparameters dynamically, i.e. during the training itself, further improves the performance compared to using static hyperparameters which are kept fixed for the whole training. Finally, our experiments provide valuable insights into the effects of several hyperparameters, such as plan horizon or learning rate and their influence on the stability of training and resulting rewards.