 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025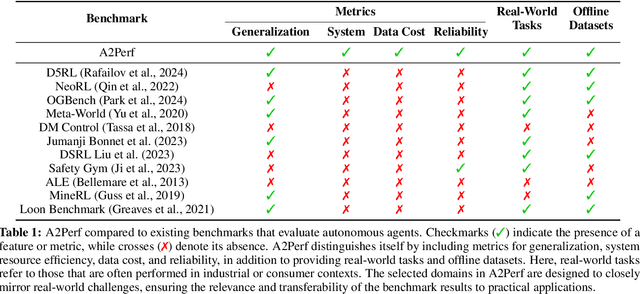

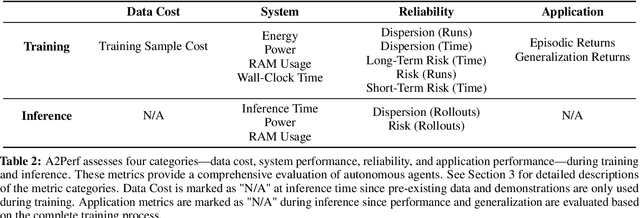

Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.
A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis
Jul 24, 2023



Pre-trained large language models (LLMs) have recently achieved better generalization and sample efficiency in autonomous web navigation. However, the performance on real-world websites has still suffered from (1) open domainness, (2) limited context length, and (3) lack of inductive bias on HTML. We introduce WebAgent, an LLM-driven agent that can complete the tasks on real websites following natural language instructions. WebAgent plans ahead by decomposing instructions into canonical sub-instructions, summarizes long HTML documents into task-relevant snippets, and acts on websites via generated Python programs from those. We design WebAgent with Flan-U-PaLM, for grounded code generation, and HTML-T5, new pre-trained LLMs for long HTML documents using local and global attention mechanisms and a mixture of long-span denoising objectives, for planning and summarization. We empirically demonstrate that our recipe improves the success on a real website by over 50%, and that HTML-T5 is the best model to solve HTML-based tasks; achieving 14.9% higher success rate than prior SoTA on the MiniWoB web navigation benchmark and better accuracy on offline task planning evaluation.
Understanding HTML with Large Language Models
Oct 08, 2022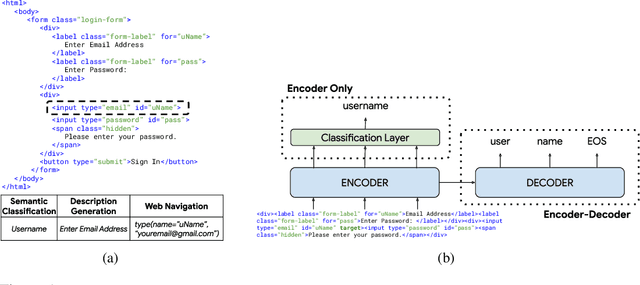

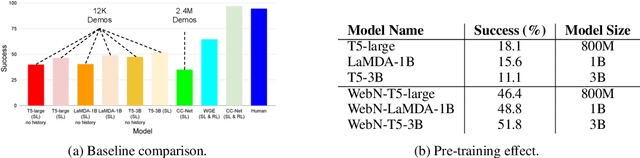
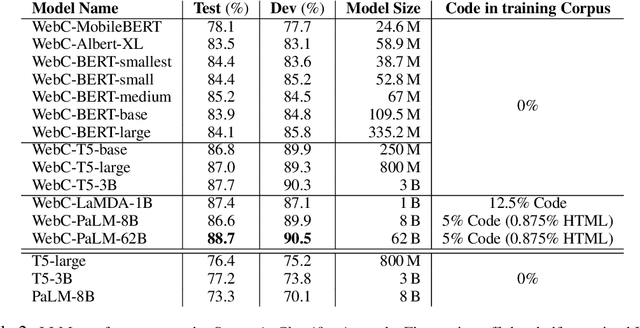
Large language models (LLMs) have shown exceptional performance on a variety of natural language tasks. Yet, their capabilities for HTML understanding -- i.e., parsing the raw HTML of a webpage, with applications to automation of web-based tasks, crawling, and browser-assisted retrieval -- have not been fully explored. We contribute HTML understanding models (fine-tuned LLMs) and an in-depth analysis of their capabilities under three tasks: (i) Semantic Classification of HTML elements, (ii) Description Generation for HTML inputs, and (iii) Autonomous Web Navigation of HTML pages. While previous work has developed dedicated architectures and training procedures for HTML understanding, we show that LLMs pretrained on standard natural language corpora transfer remarkably well to HTML understanding tasks. For instance, fine-tuned LLMs are 12% more accurate at semantic classification compared to models trained exclusively on the task dataset. Moreover, when fine-tuned on data from the MiniWoB benchmark, LLMs successfully complete 50% more tasks using 192x less data compared to the previous best supervised model. Out of the LLMs we evaluate, we show evidence that T5-based models are ideal due to their bidirectional encoder-decoder architecture. To promote further research on LLMs for HTML understanding, we create and open-source a large-scale HTML dataset distilled and auto-labeled from CommonCrawl.
Sim2Real Docs: Domain Randomization for Documents in Natural Scenes using Ray-traced Rendering
Dec 16, 2021

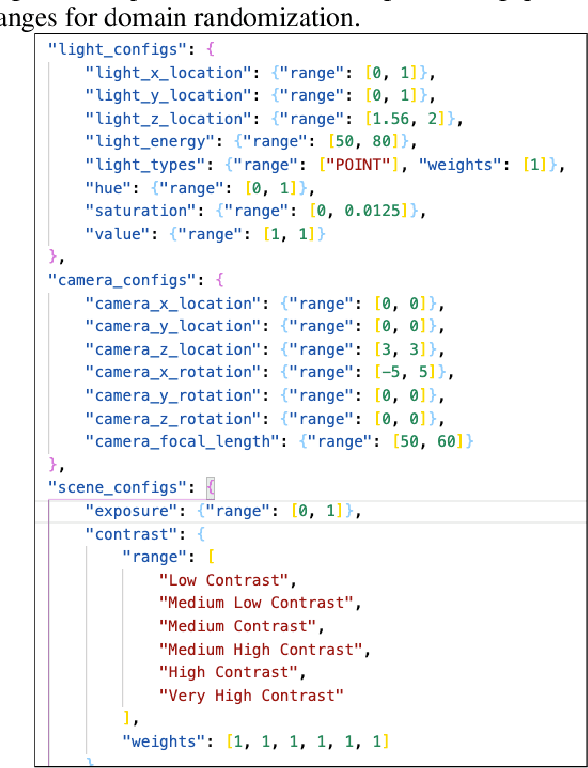
In the past, computer vision systems for digitized documents could rely on systematically captured, high-quality scans. Today, transactions involving digital documents are more likely to start as mobile phone photo uploads taken by non-professionals. As such, computer vision for document automation must now account for documents captured in natural scene contexts. An additional challenge is that task objectives for document processing can be highly use-case specific, which makes publicly-available datasets limited in their utility, while manual data labeling is also costly and poorly translates between use cases. To address these issues we created Sim2Real Docs - a framework for synthesizing datasets and performing domain randomization of documents in natural scenes. Sim2Real Docs enables programmatic 3D rendering of documents using Blender, an open source tool for 3D modeling and ray-traced rendering. By using rendering that simulates physical interactions of light, geometry, camera, and background, we synthesize datasets of documents in a natural scene context. Each render is paired with use-case specific ground truth data specifying latent characteristics of interest, producing unlimited fit-for-task training data. The role of machine learning models is then to solve the inverse problem posed by the rendering pipeline. Such models can be further iterated upon with real-world data by either fine tuning or making adjustments to domain randomization parameters.
Algorithm to Compilation Co-design: An Integrated View of Neural Network Sparsity
Jun 17, 2021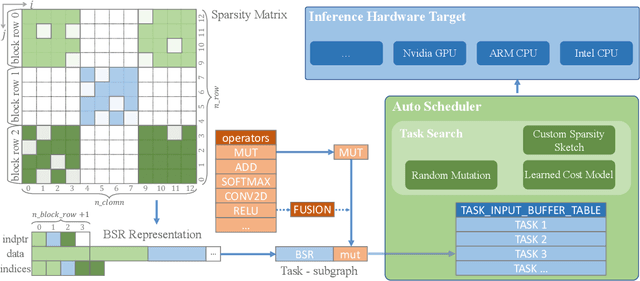
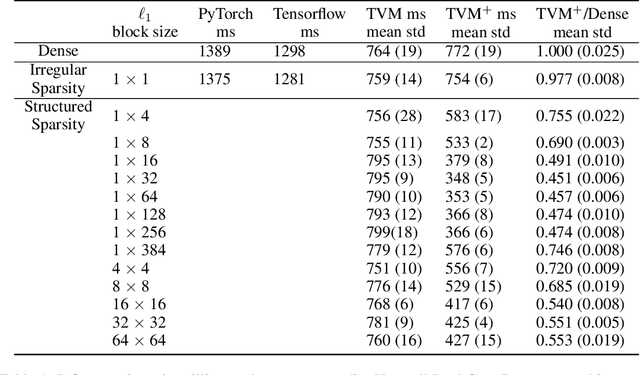
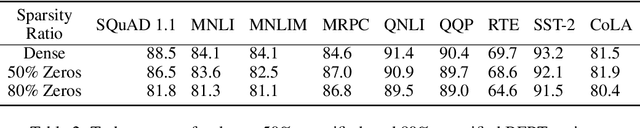
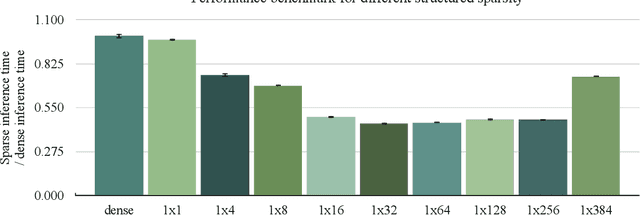
Reducing computation cost, inference latency, and memory footprint of neural networks are frequently cited as research motivations for pruning and sparsity. However, operationalizing those benefits and understanding the end-to-end effect of algorithm design and regularization on the runtime execution is not often examined in depth. Here we apply structured and unstructured pruning to attention weights of transformer blocks of the BERT language model, while also expanding block sparse representation (BSR) operations in the TVM compiler. Integration of BSR operations enables the TVM runtime execution to leverage structured pattern sparsity induced by model regularization. This integrated view of pruning algorithms enables us to study relationships between modeling decisions and their direct impact on sparsity-enhanced execution. Our main findings are: 1) we validate that performance benefits of structured sparsity block regularization must be enabled by the BSR augmentations to TVM, with 4x speedup relative to vanilla PyTorch and 2.2x speedup relative to standard TVM compilation (without expanded BSR support). 2) for BERT attention weights, the end-to-end optimal block sparsity shape in this CPU inference context is not a square block (as in \cite{gray2017gpu}) but rather a linear 32x1 block 3) the relationship between performance and block size / shape is is suggestive of how model regularization parameters interact with task scheduler optimizations resulting in the observed end-to-end performance.