 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real Docs: Domain Randomization for Documents in Natural Scenes using Ray-traced Rendering
Paper and Code


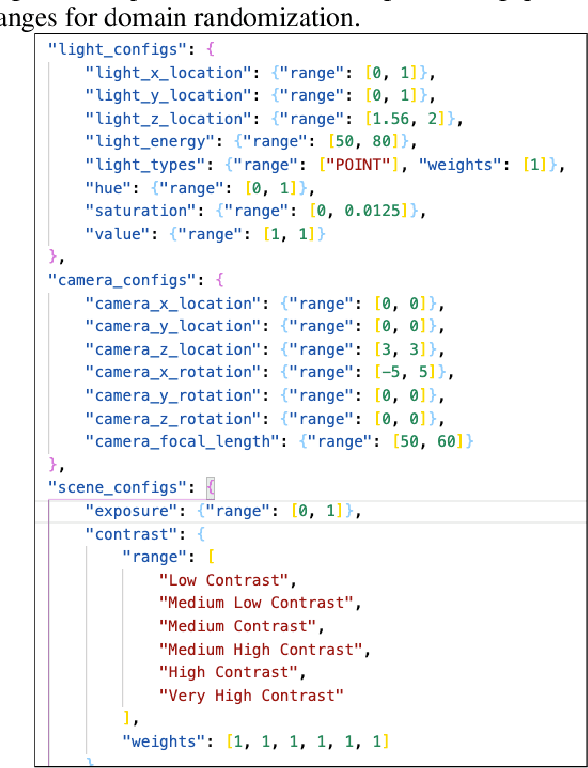
In the past, computer vision systems for digitized documents could rely on systematically captured, high-quality scans. Today, transactions involving digital documents are more likely to start as mobile phone photo uploads taken by non-professionals. As such, computer vision for document automation must now account for documents captured in natural scene contexts. An additional challenge is that task objectives for document processing can be highly use-case specific, which makes publicly-available datasets limited in their utility, while manual data labeling is also costly and poorly translates between use cases. To address these issues we created Sim2Real Docs - a framework for synthesizing datasets and performing domain randomization of documents in natural scenes. Sim2Real Docs enables programmatic 3D rendering of documents using Blender, an open source tool for 3D modeling and ray-traced rendering. By using rendering that simulates physical interactions of light, geometry, camera, and background, we synthesize datasets of documents in a natural scene context. Each render is paired with use-case specific ground truth data specifying latent characteristics of interest, producing unlimited fit-for-task training data. The role of machine learning models is then to solve the inverse problem posed by the rendering pipeline. Such models can be further iterated upon with real-world data by either fine tuning or making adjustments to domain randomization parameters.