 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdamHD: Decoupled Huber Decay Regularization for Language Model Pre-Training
Nov 18, 2025Adaptive optimizers with decoupled weight decay, such as AdamW, are the de facto standard for pre-training large transformer-based generative models. Yet the quadratic nature of the $\ell_2$ penalty embedded in weight decay drives all parameters toward the origin at the same rate, making the update vulnerable to rare but extreme gradient directions and often over-penalizing well-conditioned coordinates. We propose AdamHuberDecay, a drop-in replacement for AdamW that substitutes the $\ell_2$ penalty with a decoupled smooth Huber regularizer. The resulting update decays parameters quadratically while their magnitude remains below a threshold $δ$, and linearly ($\ell_1$-like) once they exceed $δ$, yielding (i) bounded regularization gradients, (ii) invariance to per-coordinate second-moment rescaling, and (iii) stronger sparsity pressure on overgrown weights. We derive the closed-form decoupled Huber decay step and show how to integrate it with any Adam-family optimizer at $O(1)$ extra cost. Extensive experiments on GPT-2 and GPT-3 pre-training demonstrate that AdamHuberDecay (a) converges 10-15% faster in wall-clock time, (b) reduces validation perplexity by up to 4 points, (c) delivers performance improvements of 2.5-4.7% across downstream tasks, and (d) yields visibly sparser weight histograms that translate into 20-30% memory savings after magnitude pruning, without tuning the decay coefficient beyond the default grid used for AdamW. Ablations confirm robustness to outlier gradients and large-batch regimes, together with theoretical analyses that bound the expected parameter norm under noisy updates. AdamHuberDecay therefore provides a simple, principled path toward more efficient and resilient training of next-generation foundational generative transformers.
* 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: GPU-Accelerated and Scalable Optimization (ScaleOpt)
SparseOptimizer: Sparsify Language Models through Moreau-Yosida Regularization and Accelerate via Compiler Co-design
Jul 18, 2023This paper introduces SparseOptimizer, a novel deep learning optimizer that exploits Moreau-Yosida regularization to naturally induce sparsity in large language models such as BERT, ALBERT and GPT. Key to the design of SparseOptimizer is an embedded shrinkage operator, which imparts sparsity directly within the optimization process. This operator, backed by a sound theoretical framework, includes an analytical solution, thereby reinforcing the optimizer's robustness and efficacy. Crucially, SparseOptimizer's plug-and-play functionality eradicates the need for code modifications, making it a universally adaptable tool for a wide array of large language models. Empirical evaluations on benchmark datasets such as GLUE, RACE, SQuAD1, and SQuAD2 confirm that SparseBERT and SparseALBERT, when sparsified using SparseOptimizer, achieve performance comparable to their dense counterparts, BERT and ALBERT, while significantly reducing their parameter count. Further, this work proposes an innovative optimizer-compiler co-design strategy, demonstrating the potential of inference acceleration (\textbf{3.37x}, \textbf{6.30x}, and \textbf{7.15x} in comparison with Pytorch, TensorFlow, and LLVM generic compile, respectively) in SparseBERT when paired with an appropriately designed compiler. This study represents a significant step forward in the evolution of efficient, scalable, and high-performing large language models, setting a precedent for future exploration and optimization in this domain. The SparseOptimizer code and SparseALBERT model will be publicly available upon paper acceptance.
Zero-Shot and Few-Shot Learning for Lung Cancer Multi-Label Classification using Vision Transformer
May 31, 2022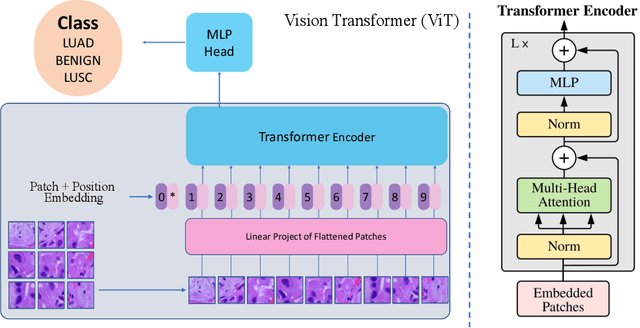
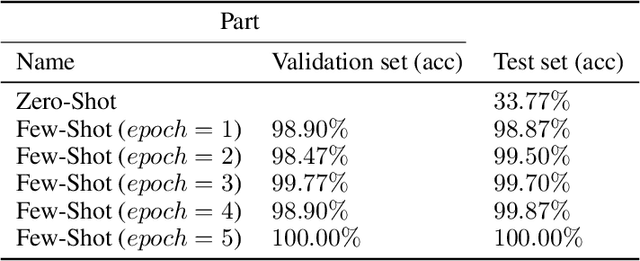
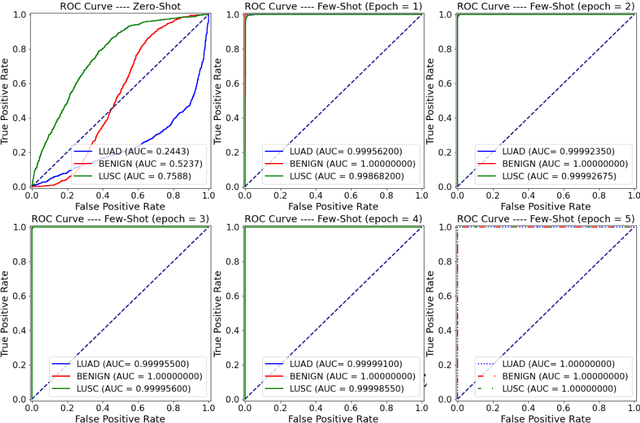
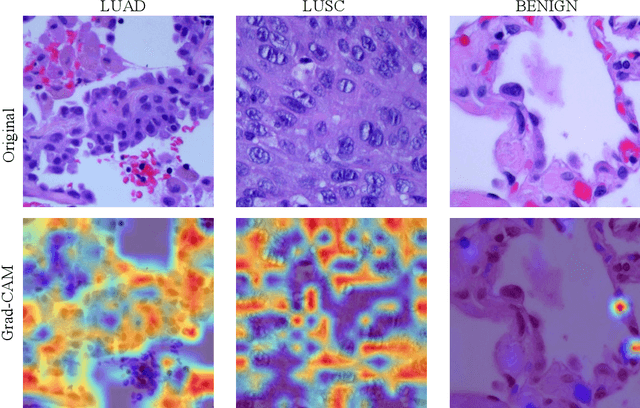
Lung cancer is the leading cause of cancer-related death worldwide. Lung adenocarcinoma (LUAD) and lung squamous cell carcinoma (LUSC) are the most common histologic subtypes of non-small-cell lung cancer (NSCLC). Histology is an essential tool for lung cancer diagnosis. Pathologists make classifications according to the dominant subtypes. Although morphology remains the standard for diagnosis, significant tool needs to be developed to elucidate the diagnosis. In our study, we utilize the pre-trained Vision Transformer (ViT) model to classify multiple label lung cancer on histologic slices (from dataset LC25000), in both Zero-Shot and Few-Shot settings. Then we compare the performance of Zero-Shot and Few-Shot ViT on accuracy, precision, recall, sensitivity and specificity. Our study show that the pre-trained ViT model has a good performance in Zero-Shot setting, a competitive accuracy ($99.87\%$) in Few-Shot setting ({epoch = 1}) and an optimal result ($100.00\%$ on both validation set and test set) in Few-Shot seeting ({epoch = 5}).
Sim2Real Docs: Domain Randomization for Documents in Natural Scenes using Ray-traced Rendering
Dec 16, 2021

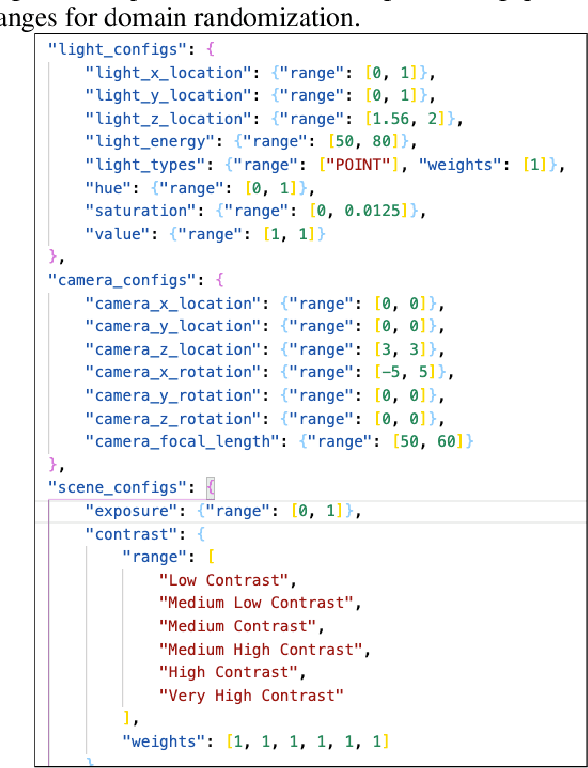
In the past, computer vision systems for digitized documents could rely on systematically captured, high-quality scans. Today, transactions involving digital documents are more likely to start as mobile phone photo uploads taken by non-professionals. As such, computer vision for document automation must now account for documents captured in natural scene contexts. An additional challenge is that task objectives for document processing can be highly use-case specific, which makes publicly-available datasets limited in their utility, while manual data labeling is also costly and poorly translates between use cases. To address these issues we created Sim2Real Docs - a framework for synthesizing datasets and performing domain randomization of documents in natural scenes. Sim2Real Docs enables programmatic 3D rendering of documents using Blender, an open source tool for 3D modeling and ray-traced rendering. By using rendering that simulates physical interactions of light, geometry, camera, and background, we synthesize datasets of documents in a natural scene context. Each render is paired with use-case specific ground truth data specifying latent characteristics of interest, producing unlimited fit-for-task training data. The role of machine learning models is then to solve the inverse problem posed by the rendering pipeline. Such models can be further iterated upon with real-world data by either fine tuning or making adjustments to domain randomization parameters.
Algorithm to Compilation Co-design: An Integrated View of Neural Network Sparsity
Jun 17, 2021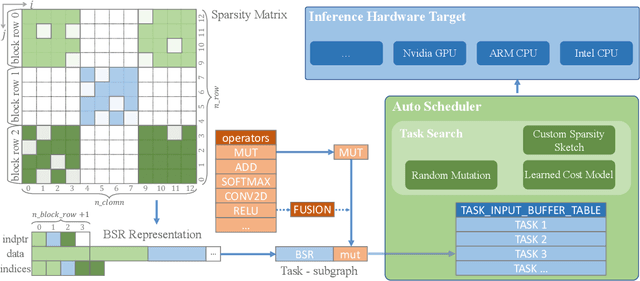
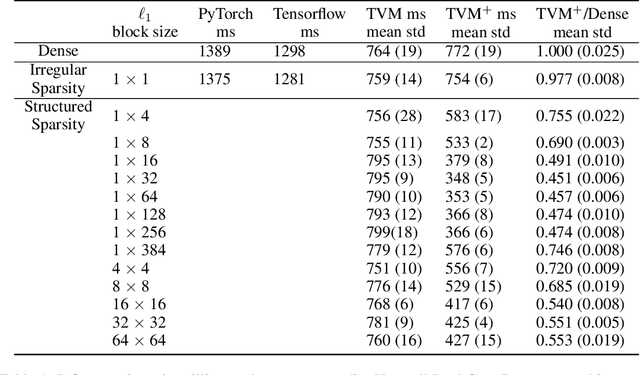
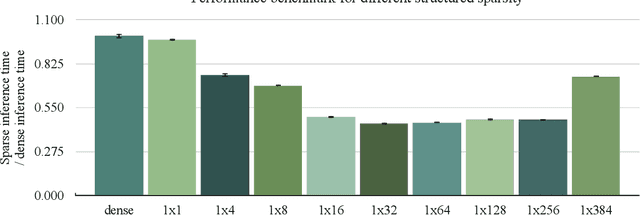
Reducing computation cost, inference latency, and memory footprint of neural networks are frequently cited as research motivations for pruning and sparsity. However, operationalizing those benefits and understanding the end-to-end effect of algorithm design and regularization on the runtime execution is not often examined in depth. Here we apply structured and unstructured pruning to attention weights of transformer blocks of the BERT language model, while also expanding block sparse representation (BSR) operations in the TVM compiler. Integration of BSR operations enables the TVM runtime execution to leverage structured pattern sparsity induced by model regularization. This integrated view of pruning algorithms enables us to study relationships between modeling decisions and their direct impact on sparsity-enhanced execution. Our main findings are: 1) we validate that performance benefits of structured sparsity block regularization must be enabled by the BSR augmentations to TVM, with 4x speedup relative to vanilla PyTorch and 2.2x speedup relative to standard TVM compilation (without expanded BSR support). 2) for BERT attention weights, the end-to-end optimal block sparsity shape in this CPU inference context is not a square block (as in \cite{gray2017gpu}) but rather a linear 32x1 block 3) the relationship between performance and block size / shape is is suggestive of how model regularization parameters interact with task scheduler optimizations resulting in the observed end-to-end performance.
Reweighted Proximal Pruning for Large-Scale Language Representation
Sep 27, 2019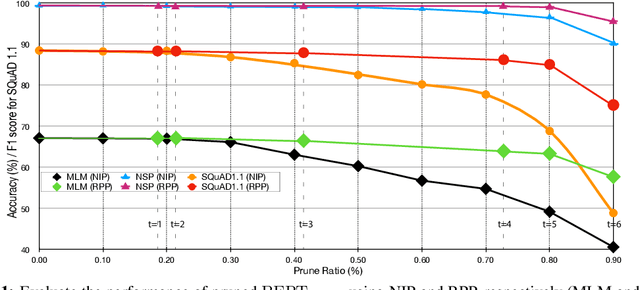
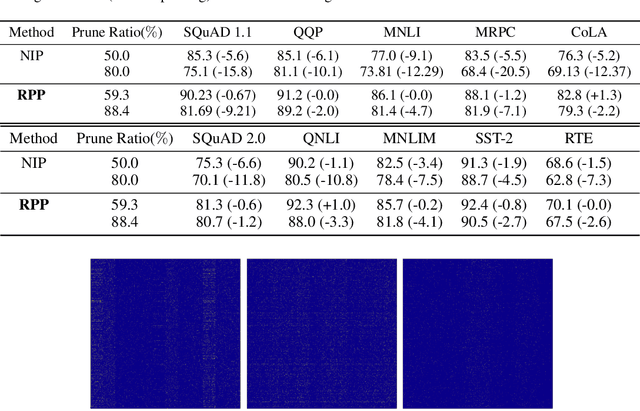
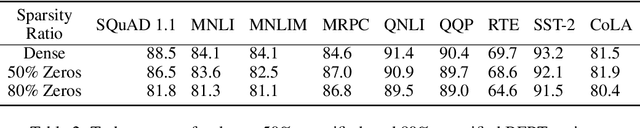
Recently, pre-trained language representation flourishes as the mainstay of the natural language understanding community, e.g., BERT. These pre-trained language representations can create state-of-the-art results on a wide range of downstream tasks. Along with continuous significant performance improvement, the size and complexity of these pre-trained neural models continue to increase rapidly. Is it possible to compress these large-scale language representation models? How will the pruned language representation affect the downstream multi-task transfer learning objectives? In this paper, we propose Reweighted Proximal Pruning (RPP), a new pruning method specifically designed for a large-scale language representation model. Through experiments on SQuAD and the GLUE benchmark suite, we show that proximal pruned BERT keeps high accuracy for both the pre-training task and the downstream multiple fine-tuning tasks at high prune ratio. RPP provides a new perspective to help us analyze what large-scale language representation might learn. Additionally, RPP makes it possible to deploy a large state-of-the-art language representation model such as BERT on a series of distinct devices (e.g., online servers, mobile phones, and edge devices).
PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-time Execution on Mobile Devices
Sep 12, 2019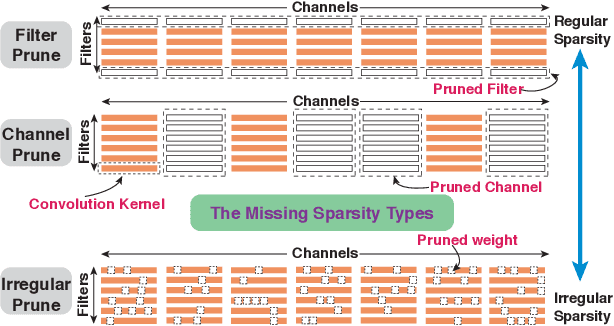
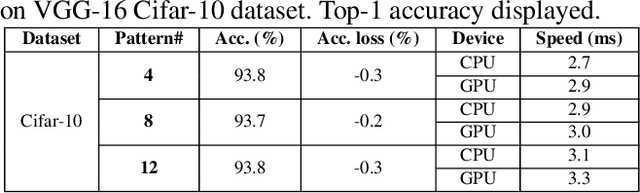
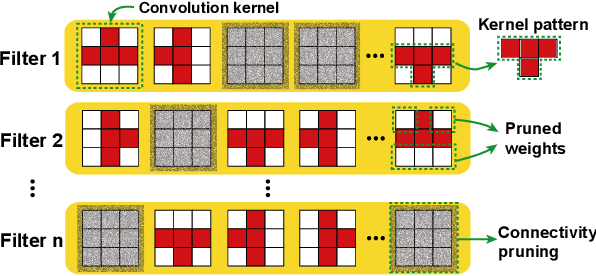

Model compression techniques on Deep Neural Network (DNN) have been widely acknowledged as an effective way to achieve acceleration on a variety of platforms, and DNN weight pruning is a straightforward and effective method. There are currently two mainstreams of pruning methods representing two extremes of pruning regularity: non-structured, fine-grained pruning can achieve high sparsity and accuracy, but is not hardware friendly; structured, coarse-grained pruning exploits hardware-efficient structures in pruning, but suffers from accuracy drop when the pruning rate is high. In this paper, we introduce PCONV, comprising a new sparsity dimension, -- fine-grained pruning patterns inside the coarse-grained structures. PCONV comprises two types of sparsities, Sparse Convolution Patterns (SCP) which is generated from intra-convolution kernel pruning and connectivity sparsity generated from inter-convolution kernel pruning. Essentially, SCP enhances accuracy due to its special vision properties, and connectivity sparsity increases pruning rate while maintaining balanced workload on filter computation. To deploy PCONV, we develop a novel compiler-assisted DNN inference framework and execute PCONV models in real-time without accuracy compromise, which cannot be achieved in prior work. Our experimental results show that, PCONV outperforms three state-of-art end-to-end DNN frameworks, TensorFlow-Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 39.2x, 11.4x, and 6.3x, respectively, with no accuracy loss. Mobile devices can achieve real-time inference on large-scale DNNs.